当前位置:网站首页>Partitionby of spark operator
Partitionby of spark operator
2022-04-23 15:45:00 【Uncle flying against the wind】
Preface
In previous studies , We use groupBy The data can be processed according to the specified key Grouping rules , Imagine a scenario like this , If you want to tuple Data of type , namely key/value What should I do to group data of different types ? In response to this Spark Provides partitionBy Operator solution ;
partitionBy
Function signature
def partitionBy( partitioner: Partitioner ): RDD[(K, V)]
Function description
Set the data as specified Partitioner Repartitioning . Spark The default comparator is HashPartitioner
The case shows
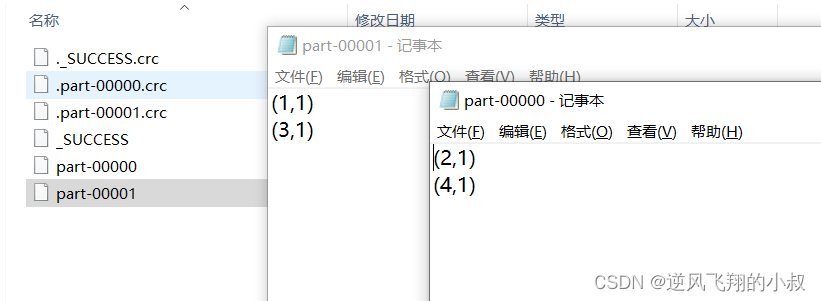
Pass a set of data through partitionBy Then it is stored in multiple partition files
import org.apache.spark.rdd.RDD
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
object PartionBy_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO operator - (Key - Value type )
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
val mapRDD: RDD[(Int, Int)] = rdd.map((_, 1))
// partitionBy Repartition the data according to the specified partition rules
val newRDD = mapRDD.partitionBy(new HashPartitioner(2)).saveAsTextFile("E:\\output")
sc.stop()
}
}Run the above code , After execution , Observe the local directory , You can see 4 Pieces of data cannot be divided into different partition files
版权声明
本文为[Uncle flying against the wind]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231544587236.html
边栏推荐
- MySQL optimistic lock to solve concurrency conflict
- gps北斗高精度卫星时间同步系统应用案例
- Multitimer V2 reconstruction version | an infinitely scalable software timer
- Application of Bloom filter in 100 million flow e-commerce system
- pywintypes. com_ Error: (- 2147221020, 'invalid syntax', none, none)
- 一刷314-剑指 Offer 09. 用两个栈实现队列(e)
- What is CNAs certification? What are the software evaluation centers recognized by CNAs?
- Pgpool II 4.3 Chinese Manual - introductory tutorial
- 基于 TiDB 的 Apache APISIX 高可用配置中心的最佳实践
- Single architecture system re architecture
猜你喜欢
时序模型:长短期记忆网络(LSTM)

APISIX jwt-auth 插件存在错误响应中泄露信息的风险公告(CVE-2022-29266)
Config组件学习笔记
【AI周报】英伟达用AI设计芯片;不完美的Transformer要克服自注意力的理论缺陷

MetaLife与ESTV建立战略合作伙伴关系并任命其首席执行官Eric Yoon为顾问
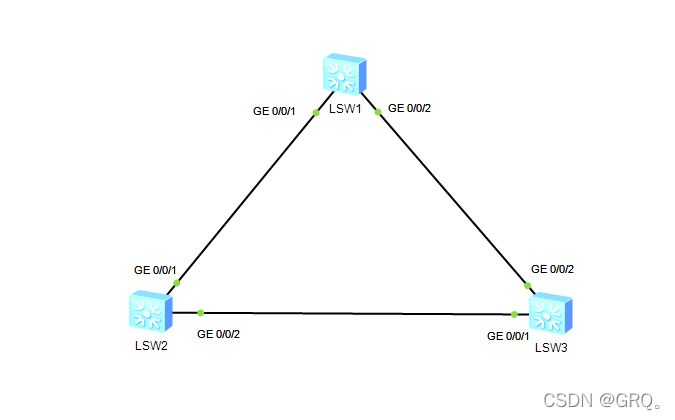
Configuration of multi spanning tree MSTP

腾讯Offer已拿,这99道算法高频面试题别漏了,80%都败在算法上

Do we media make money now? After reading this article, you will understand
Codejock Suite Pro v20. three
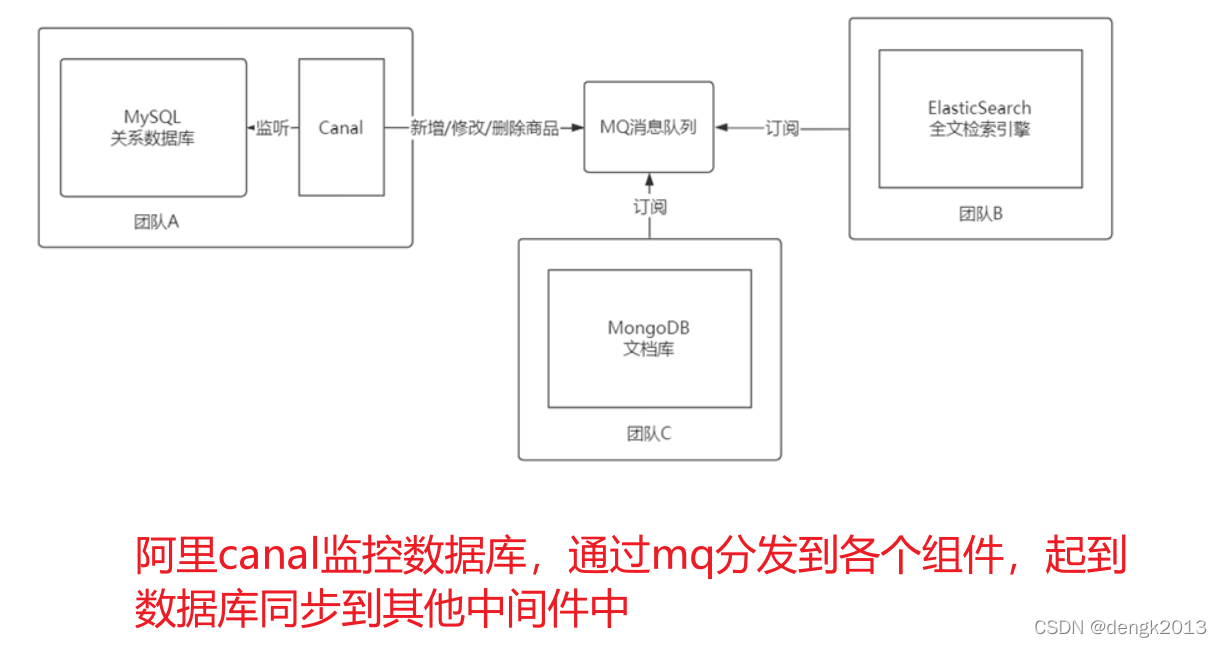
MySQL Cluster Mode and application scenario
随机推荐
【开源工具分享】单片机调试助手(示波/改值/日志) - LinkScope
Upgrade MySQL 5.1 to 5.69
Cookie&Session
考试考试自用
删除字符串中出现次数最少的字符
String sorting
多生成树MSTP的配置
Today's sleep quality record 76 points
MySQL Cluster Mode and application scenario
C#,贝尔数(Bell Number)的计算方法与源程序
携号转网最大赢家是中国电信,为何人们嫌弃中国移动和中国联通?
Treatment of idempotency
Application of Bloom filter in 100 million flow e-commerce system
一刷314-剑指 Offer 09. 用两个栈实现队列(e)
s16.基于镜像仓库一键安装containerd脚本
单体架构系统重新架构
腾讯Offer已拿,这99道算法高频面试题别漏了,80%都败在算法上
通過 PDO ODBC 將 PHP 連接到 MySQL
时序模型:长短期记忆网络(LSTM)
【递归之数的拆分】n分k,限定范围的拆分