当前位置:网站首页>【语义分割】2017-PSPNet CVPR
【语义分割】2017-PSPNet CVPR
2022-08-10 19:12:00 【說詤榢】
文章目录
【语义分割】2017-PSPNet CVPR
论文题目:Pyramid Scene Parsing Network
论文链接:https://arxiv.org/abs/1612.01105
论文代码:https://github.com/hszhao/PSPNet
发表时间:2016年12月
引用:Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2881-2890.
引用数:7887
1. 简介
1.1 摘要
此篇论文通过金字塔池化模块(Pyramid Pooling Module)和基于此提出的金字塔场景解析网络(PSPNet),聚合了基于不同区域的上下文信息,来挖掘全局上下文信息的能力;金字塔池化模块产生的全局先验表示在场景解析任务上产生了良好的效果,在4种数据集上达到了最先进的性能。
1.2 介绍
场景解析的难度主要源于场景和标签的多样性(现有的算法在这方面做得不是很好,分割精度也比较低),所以需要准确地感知场景,场景上下文的先验信息很重要(不同类别之间的关联)
针对以上,本文的主要贡献有三个:
- 在基于FCN的像素预测框架中,我们提出了一种金字塔场景解析网络PSPNet
- 为深层的ResNet开发了一种有效的优化策略,基于深度监督的loss(也就是中途插入一个loss)
- 为场景解析和语义分割构建了一个最先进的实用的系统,其中包含了所有关键的实现细节
2. 网络
2.1 整体架构
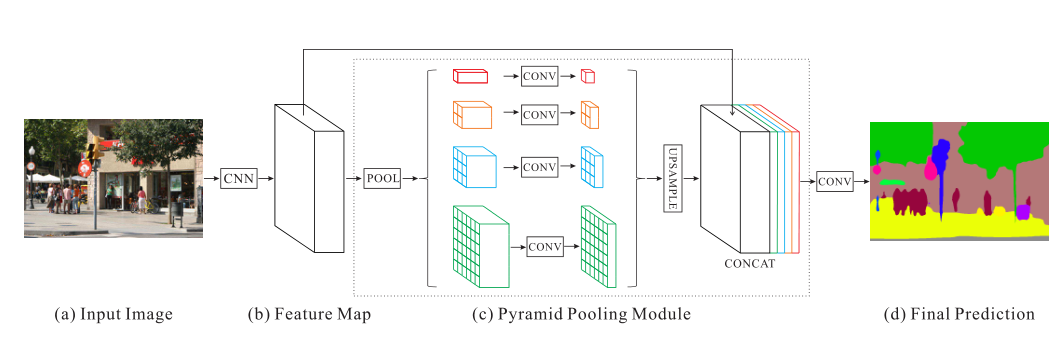
整个PSPNet的网络结构在上面已经给出了,整个流程为:
- 输入图像后,使用预训练的带空洞卷积ResNet提取特征图。最终的特征映射大小是输入图像的1/8
- 在特征图上,我们使用中的**金字塔池化模块来收集上下文信息:**使用4层金字塔结构,池化内核覆盖了图像的全部、一半和小部分,它们被融合为全局先验信息,最后将之前的金字塔特征映射与原始特征映射concate起来
- 最后再进行卷积,生成最终预测图
2.2 Pyramid Pooling Module
根据上述的分析,我们知道现在最重要的问题就是充分利用图像中的上下文信息;以往的做法有全局平均池化和金字塔池化(SPP)
1) 全局平均池化
通常用于图像分类的全局平均池化是一个很好的全局上下文先验知识baseline,Parsenet将它成功应用到了语义分割中。但对于ADE20K中的复杂场景图像,这种方式不足以涵盖必要的信息。这些场景图像中有许多种类的对象,直接将其融合形成一个单一的矢量可能会使其失去空间相关性。
一个更强大的表达应该是:**能融合不同子区域的信息与感受野(**感受野可以粗略的表示我们使用上下文信息的程度。在经典著作SPM和SPPNet中也得出了类似的结论
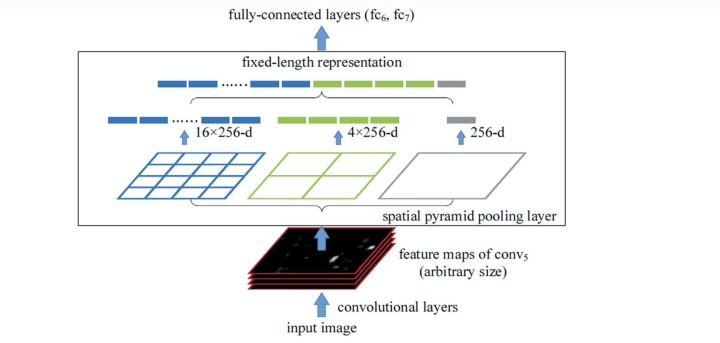
2) 金字塔池化SPP
在SPPNet,金字塔池化生成的不同层次的特征图最终被flatten并concate起来,再送入全连接层以进行分类,该全局先验知识旨在消除CNN要求图像分类输入大小固定的限制.
3) 金字塔池化模块
为了进一步减少不同子区域间上下文信息的丢失,如上图的Pyramid Pooling Module部分:本文提出了一个有层次的全局先验结构,包含不同尺度、不同子区域间的信息可以在深层神经网络的最终层特征图上构造全局场景先验信息。(我觉得它和SPP的不同主要是它最后没有展平送到全连接层,而且它最后还加上了原始的Feature Map)
金字塔池化模块可以融合四种不同金字塔尺度的特征
- 红色突出显示的是最粗糙级别的单个全局池化输出,下面的金字塔分支将特征映射划分为不同的子区域,并形成针对不同位置的集合表示
- 为了维护全局特性的权重,如果金字塔共有N个级别,则在每个级别后使用1×1卷积,将对应级别的通道数量降为原本的1/N(这边的意思就是如果不用1×1卷积降维的话,加了这个金字塔池化模块之后)
- 通过双线性插值直接对低维特征图进行上采样,得到与原始特征映射相同尺寸的特征图(1×1的怎么进行双线性插值:直接复制粘贴到图像的每个点上)
- 最后,将不同级别的特征concate起来,作为最终的金字塔池化全局特性(还加上了原始的Feature Map)。
本文使用的金字塔池化模块是一个四层结构,大小分别为1×1,2×2,3×3和6×6。(金字塔层级的数量和每一层的大小都可以进行调整)
2.3 Loss
这一部分主要讲的是,在第一个残差bolck之后提前插入一个loss
(我理解的意思是同时看这两个loss,从loss2的输出先调整一下模型,这样的话能够保证前面的没有训练坏掉,然后再往后调整loss1)
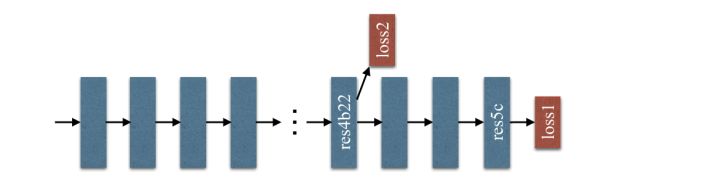
- 除了使用Softmax loss来训练最终分类器的的主分支外,在第四阶段后再使用另一个分类器loss2
- 这两个loss同时传播,通过各自前面所有层
- 辅助loss有助于优化学习过程,主loss仍是主要的优化方向。增加权重,以平衡辅助loss
- 在测试阶段,不用这个辅助分支,只使用优化好的主分支来进行最终的预测。
3. 代码
import os
from collections import OrderedDict
import math
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils import model_zoo
def load_weights_sequential(target, source_state):
new_dict = OrderedDict()
for (k1, v1), (k2, v2) in zip(target.state_dict().items(), source_state.items()):
new_dict[k1] = v2
target.load_state_dict(new_dict)
''' Implementation of dilated ResNet-101 with deep supervision. Downsampling is changed to 8x '''
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
}
def conv3x3(in_planes, out_planes, stride=1, dilation=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, dilation=dilation, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride=stride, dilation=dilation)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, stride=1, dilation=dilation)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, dilation=dilation,
padding=dilation, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers=(3, 4, 23, 3)):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation=4)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1, dilation=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = [block(self.inplanes, planes, stride, downsample)]
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, dilation=dilation))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x_3 = self.layer3(x)
x = self.layer4(x_3)
return x, x_3
def resnet18(pretrained=True):
model = ResNet(BasicBlock, [2, 2, 2, 2])
if pretrained:
load_weights_sequential(model, model_zoo.load_url(model_urls['resnet18']))
return model
def resnet34(pretrained=True):
model = ResNet(BasicBlock, [3, 4, 6, 3])
if pretrained:
load_weights_sequential(model, model_zoo.load_url(model_urls['resnet34']))
return model
def resnet50(pretrained=True):
model = ResNet(Bottleneck, [3, 4, 6, 3])
if pretrained:
load_weights_sequential(model, model_zoo.load_url(model_urls['resnet50']))
return model
def resnet101(pretrained=True):
model = ResNet(Bottleneck, [3, 4, 23, 3])
if pretrained:
load_weights_sequential(model, model_zoo.load_url(model_urls['resnet101']))
return model
def resnet152(pretrained=True):
model = ResNet(Bottleneck, [3, 8, 36, 3])
if pretrained:
load_weights_sequential(model, model_zoo.load_url(model_urls['resnet152']))
return model
# resnet
# ########################
model_urls = {
'mobilenetv2': 'http://sceneparsing.csail.mit.edu/model/pretrained_resnet/mobilenet_v2.pth.tar'
}
def conv_bn(in_channels, out_channels, stride):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def conv_1x1_bn(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, in_channels, out_channels, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_channels = round(in_channels * expand_ratio)
self.use_res_connect = self.stride == 1 and in_channels == out_channels
if expand_ratio == 1:
self.conv = nn.Sequential(
# depthwise conv
nn.Conv2d(hidden_channels, hidden_channels, 3, stride, 1, groups=hidden_channels, bias=False),
nn.BatchNorm2d(hidden_channels),
nn.ReLU6(inplace=True),
# pointwise conv
nn.Conv2d(hidden_channels, out_channels, 1, 1, 0, bias=False),
nn.BatchNorm2d(out_channels)
)
else:
self.conv = nn.Sequential(
# 升维
nn.Conv2d(in_channels, hidden_channels, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_channels),
nn.ReLU6(inplace=True),
# depthwise conv
nn.Conv2d(hidden_channels, hidden_channels, 3, stride, 1, groups=hidden_channels, bias=False),
nn.BatchNorm2d(hidden_channels),
nn.ReLU6(inplace=True),
# pointwise conv
nn.Conv2d(hidden_channels, out_channels, 1, 1, 0, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class mobilenet(nn.Module):
def __init__(self, num_classes=1000, input_size=224, width_mult=1.):
super(mobilenet, self).__init__()
block = InvertedResidual
input_channels = 32
last_channels = 1280
interverted_residual_settings = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1]
]
assert input_size % 32 == 0
input_channels = int(input_channels * width_mult)
self.last_channels = int(last_channels * width_mult) if width_mult > 1.0 else last_channels
self.features = [conv_bn(3, input_channels, 2)]
for t, c, n, s in interverted_residual_settings:
output_channels = int(c * width_mult)
for i in range(n):
if i == 0:
self.features.append(block(input_channels, output_channels, s, expand_ratio=t))
else:
self.features.append(block(input_channels, output_channels, 1, expand_ratio=t))
input_channels = output_channels
self.features.append(conv_1x1_bn(input_channels, self.last_channels))
self.features = nn.Sequential(*self.features)
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channels, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.mean(3).mean(2)
x = self.classifier(x)
return x
def load_url(url, model_dir='./model_data', map_loaction=None):
if not os.path.exists(model_dir):
os.makedirs(model_dir)
filename = url.split('/')[-1]
cached_file = os.path.join(model_dir, filename)
if os.path.exists(cached_file):
return torch.load(cached_file, map_location=map_loaction)
else:
return model_zoo.load_url(url, model_dir=model_dir)
def mobilenetv2(pretrained=False, **kwargs):
model = mobilenet(num_classes=1000, **kwargs)
if pretrained:
model.load_state_dict(load_url(model_urls['mobilenetv2']), strict=False)
return model
class MobileNetV2(nn.Module):
def __init__(self, downsample_factor=8, pretrained=True):
super(MobileNetV2, self).__init__()
model = mobilenetv2(pretrained=pretrained)
self.features = model.features[:-1]
self.total_idx = len(self.features)
self.down_idx = [2, 4, 7, 14]
if downsample_factor == 8:
for i in range(self.down_idx[-2], self.down_idx[-1]):
self.features[i].apply(partial(self._nostride_dilate, dilate=2))
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(partial(self._nostride_dilate, dilate=4))
else:
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(partial(self._nostride_dilate, dilate=2))
@staticmethod
def _nostride_dilate(m, dilate):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
if m.stride == (2, 2):
m.stride = (1, 1)
if m.kernel_size == (3, 3):
m.dilation = (dilate // 2, dilate // 2)
m.padding = (dilate // 2, dilate // 2)
else:
if m.kernel_size == (3, 3):
m.dilation = (dilate, dilate)
m.padding = (dilate, dilate)
def forward(self, x):
x_aux = self.features[:14](x)
x = self.features[14:](x_aux)
return x, x_aux
################
class _PSPModule(nn.Module):
def __init__(self, in_channels, pool_sizes, norm_layer):
super(_PSPModule, self).__init__()
out_channels = in_channels // len(pool_sizes)
# -----------------------------------------------------#
# 分区域进行平均池化
# 30, 30, 320 + 30, 30, 80 + 30, 30, 80 + 30, 30, 80 + 30, 30, 80 = 30, 30, 640
# -----------------------------------------------------#
self.stages = nn.ModuleList(
[self._make_stages(in_channels, out_channels, pool_size, norm_layer) for pool_size in pool_sizes])
# 30, 30, 640 -> 30, 30, 80
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels + (out_channels * len(pool_sizes)), out_channels, kernel_size=3, padding=1,
bias=False),
norm_layer(out_channels),
nn.ReLU(inplace=True),
nn.Dropout2d(0.1)
)
def _make_stages(self, in_channels, out_channels, bin_sz, norm_layer):
prior = nn.AdaptiveAvgPool2d(output_size=bin_sz)
conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
bn = norm_layer(out_channels)
relu = nn.ReLU(inplace=True)
return nn.Sequential(prior, conv, bn, relu)
def forward(self, features):
h, w = features.size()[2], features.size()[3]
pyramids = [features]
pyramids.extend(
[F.interpolate(stage(features), size=(h, w), mode='bilinear', align_corners=True) for stage in self.stages])
output = self.bottleneck(torch.cat(pyramids, dim=1))
return output
class PSPNet(nn.Module):
def __init__(self,
num_classes,
backbone="resnet50",
out_channel=2048,
pretrained=False):
""" Args: num_classes: backbone: bn_momentum: """
super(PSPNet, self).__init__()
norm_layer = nn.BatchNorm2d
self.backbone = eval(backbone)(pretrained=pretrained)
self.psp_layer = nn.Sequential(
_PSPModule(out_channel, pool_sizes=[1, 2, 3, 6], norm_layer=norm_layer),
nn.Conv2d(out_channel // 4, num_classes, kernel_size=1)
)
def forward(self, input):
b, c, h, w = input.shape
# 1/8 特征图
x, x_3 = self.backbone(input)
# torch.Size([1, 2048, 28, 28])
# torch.Size([1, 1024, 28, 28])
psp_fm = self.psp_layer(x)
pred = F.interpolate(psp_fm, size=input.size()[2:4], mode='bilinear', align_corners=True)
return pred
def pspnet_resnet50(num_classes, pretrained=False):
return PSPNet(num_classes=num_classes, backbone="resnet50", pretrained=pretrained, out_channel=2048)
def pspnet_resnet101(num_classes, pretrained=False):
return PSPNet(num_classes=num_classes, backbone="resnet101", pretrained=pretrained, out_channel=2048)
def pspnet_mobilenetv2(num_classes, pretrained=False):
return PSPNet(num_classes=num_classes, backbone="MobileNetV2", pretrained=pretrained, out_channel=320)
if __name__ == '__main__':
# 因为使用了batchnorm,所以batch_size 必须大于1
x = torch.randn(2, 3, 224, 224)
model = pspnet_mobilenetv2(num_classes=19)
y = model(x)
print(y.shape)
参考资料
PSPNet论文详解_何如千泷的博客-CSDN博客_pspnet论文
【论文阅读】PSPNet(Pyramid Scene Parsing Network)_不想编程的三只羊的博客-CSDN博客_pspnet论文
边栏推荐
- QoS Quality of Service Seven Switch Congestion Management
- 【LeetCode】42、接雨水
- servlet映射路径匹配解析
- We used 48h to co-create a web game: Dice Crush, to participate in international competitions
- 史上最全GIS相关软件(CAD、FME、Arcgis、ArcgisPro)
- 几行深度学习代码设计包含功能位点的候选免疫原、酶活性位点、蛋白结合蛋白、金属配位蛋白
- 杭电多校七 1003-Counting Stickmen(组合数学)
- 电脑为什么会蓝屏的原因
- Metasploit——渗透攻击模块(Exploit)
- 2020 ICPC Shanghai Site G
猜你喜欢
 [email protected] nanomimetic e"/>
[email protected] nanomimetic e"/>Water-soluble alloy quantum dot nanozymes|CuMoS nanozymes|porous silicon-based Pt(Au) nanozymes|[email protected] nanomimetic e

多功能纳米酶Ag/PANI|柔性衬底纳米ZnO酶|铑片纳米酶|Ag-Rh合金纳米颗粒纳米酶|铱钌合金/氧化铱仿生纳米酶
whois信息收集&企业备案信息

【知识分享】在音视频开发领域中SEI到底是个啥?

【LeetCode】42、接雨水
Ferritin particle-loaded raltitrexed/pemetrexed/sulfadesoxine/adamantane (scientific research reagent)
电脑重装系统Win11格式化硬盘的详细方法
whois information collection & corporate filing information
转铁蛋白(TF)修饰紫杉醇(PTX)脂质体(TF-PTX-LP)|转铁蛋白(Tf)修饰姜黄素脂质体

Common ports and services
随机推荐
2022杭电多校七 Black Magic (签到)
The Biotin-PEG3-Br/acid/NHS ester/alcohol/amine collection that everyone wants to share
[Go WebSocket] 你的第一个Go WebSocket服务: echo server
uni-app 数据上拉加载更多功能
laya打包发布apk
1D Array Dynamics and Question Answers
[Teach you how to make a small game] Write a function with only a few lines of native JS to play sound effects, play BGM, and switch BGM
七月券商金工精选
QoS Quality of Service Seven Switch Congestion Management
[Go WebSocket] Your first Go WebSocket server: echo server
GBASE 8s 高可用RSS集群搭建
【greenDao】Cannot access ‘org.greenrobot.greendao.AbstractDaoSession‘ which is a supertype of
The servlet mapping path matching resolution
idea汉化教程[通俗易懂]
@Autowired annotation --required a single bean, but 2 were found causes and solutions
常用Anaconda安装错误解决办法Traceback (most recent call last):[通俗易懂]
【毕业设计】基于Stm32的智能疫情防控门禁系统 - 单片机 嵌入式 物联网
赎金信问题答记
Pt/CeO2单原子纳米酶|[email protected] NPs纳米酶|碳纳米管负载铂颗粒纳米酶|白血病拮抗多肽修饰的FeOPtPEG复合纳米酶
QoS服务质量六路由器拥塞管理