当前位置:网站首页>[point cloud series] full revolutionary geometric features
[point cloud series] full revolutionary geometric features
2022-04-23 13:18:00 【^_^ Min Fei】
List of articles
Inventory clearing series , It took a long time .
1. Summary
The paper :Fully-Convolutional geometric features
Code :https://github.com/chrischoy/fcgf
Background knowledge supplement :
In reverse engineering, the point data set of product appearance surface obtained by measuring instrument is also called point cloud , Generally, the number of points obtained by using three-dimensional coordinate measuring machine is relatively small , The distance between points is also relatively large , It's called sparse point cloud ; A three-dimensional laser scanner or cloud scanner is used to obtain points , The number of points is relatively large and dense , It's called dense point cloud .
2. motivation
Existing methods often need to calculate the underlying features as input Or block based finite receptive field features .
Differentiated 3D features , Especially registration 、 track 、 In the scene flow task .
Therefore, this paper proposes FCGF, Through the full convolution network, the feature of point cloud is calculated , No need to deal with , Compact structure (32 dimension ).
Specifically : Use Minkowski Convolution coefficient expression + Use ResUnet The extracted features + new loss Measure
Basically, it can be understood as Minkowski Of U-Net Convolution form , utilize Minkowski The sparsity of + Residuals and U-Net Feature retention enables compact expression .
3. Method
The overall framework :
Basically, it benefits from U-Net+ The good effect of residuals
Residual structure : 2 A convolution operation on the output , As shown in the orange box on the right .
Encoder :3 individual (Conv+BN+Res) Structure , The blue module , Nuclear size : 3 × 3 3\times 3 3×3, The first convolution stride=1, The rest is 2.
decoder :3 individual (Transposed Conv+BN+Res) structure , Yellow module , Remove the first one Transposed Conv, The rest have two inputs .
Feature extraction layer : the last one Conv, Output 32 passageway ;

Point clouds express : Coordinate matrix C+ features F, That is, the pattern of Minkowski convolution .
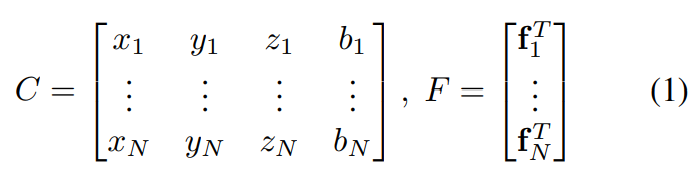
Loss function
4 Loss function in :
- Contrast the loss (Contrastive loss)
- Triplet loss (Triplet loss)
- Hard sample - Contrast the loss (Hardest-contrastive)
- Hard sample - A triple (Hardest-triplet)
The basic design idea meets :
If (i, j) That's right , Then their characteristic distance satisfies D ( f i , f j ) − > 0 D(f_i, f_j) ->0 D(fi,fj)−>0, General Settings D ( f i , f j ) < m p D(f_i, f_j) <m_p D(fi,fj)<mp that will do , Prevent over fitting ;
If (i, j) Is a negative sample pair , Then the characteristics between them should meet D ( f i , f j ) > m n D(f_i, f_j) >m_n D(fi,fj)>mn.
m It's the threshold . The following compares the differences between the four methods :
Blue arrow : A positive sample is right ; orange : Negative sample pair ;

Contrast the loss

Formula analysis :
I i j = 1 I_{ij}=1 Iij=1:(i, j) Positive sample pair ; otherwise I i j = 0 I_{ij}=0 Iij=0
I ˉ i j = 1 \bar{I}_{ij}=1 Iˉij=1: (i, j) Is a negative sample pair ; otherwise I ˉ i j = 0 \bar{I}_{ij}=0 Iˉij=0
Positive sample alignment by 3DMatch Data GT Our nearest neighbors get , Negative samples are generated randomly , Filter out the points belonging to the positive sample through the hash table .
Hard sample - Contrast the loss
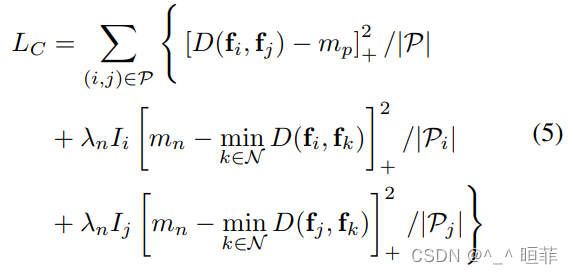
Formula analysis :
The formula is divided into three parts , The part measured by the positive sample remains unchanged , Compared with the loss . It just expands the negative sample into two parts , Calculated proportionally . That is, it refines the loss of the part of the negative sample that is easy to distinguish into positive samples .
P P P: Number of positive samples
P i P_i Pi And P j P_j Pj: All negative samples , Two positive samples correspond to one negative sample , So there are two parts .
Icon 3 Very clear .
Triplet loss

Formula analysis :
Want to minimize the distance between two positive samples , Maximize the distance between two negative samples at the same time .
f f f: Current characteristics ;
f + f_+ f+: f f f A positive sample of
f − f_- f−: f f f The negative sample of
Hard sample - Triplet loss

Formula analysis :
Just a pair of positive samples (i, j) Respectively for i i i Build a triple , Yes j j j Build a triple . Each point corresponds to a negative sample , So it becomes a triple loss of two terms . It is hoped that the larger the sample spacing is , The smaller the negative sample spacing .
4. experimental result
Experimental setup
The optimizer is SGD, Initial learning rate 0.1, Exponential decay learning rate ( γ = 0.99 \gamma = 0.99 γ=0.99).Batch size Set to 4, Training 100 individual epoches. Use random data in training scale(0.8 - 1.2) And random rotation (0-360°) The enhancement of .
Data sets
3D Match
KITTI
Evaluation indicators
-
Feature-match Recall (FMR)

Formula analysis : The average value of each point cloud's judgment on the quality of features .
1 1 1: Indicator function
Ω s \Omega_s Ωs: The first s s s individual pair Nearest neighbor
T ∗ T^* T∗: Translation and rotation transformation of point cloud pair
y j = a r g m i n y j ∣ ∣ F x i − F y j ∣ ∣ y_j = argmin_{y_j} ||F_{xi}-F_{yj}|| yj=argminyj∣∣Fxi−Fyj∣∣. That is to say x i x_i xi stay Y The point with the smallest feature distance .
τ 1 = 0.1 , τ 2 = 0.05 \tau_1=0.1, \tau_2=0.05 τ1=0.1,τ2=0.05 -
Registration recall

Formula analysis : Measure two pairs of points (i, j) With its estimated point pair T ^ i , j \hat{T}_{i,j} T^i,j Of MSE distance .
Ω ∗ \Omega^* Ω∗: Point pair set , If (i , j) Coverage is in 30% above , So think E R M S E < 0.2 m E_{RMSE}<0.2m ERMSE<0.2m The match is correct . -
Associated rotation and conversion losses :
R T E = ∣ T ^ − T ∗ ∣ RTE = |\hat{T} - T^*| RTE=∣T^−T∗∣
R R E = a r c o s s ( ( T r ( R ^ T R ∗ ) − 1 ) / 2 ) RRE = arcoss((Tr(\hat{R}^TR^*)-1)/2) RRE=arcoss((Tr(R^TR∗)−1)/2), R ^ \hat{R} R^ Is the predicted rotation matrix , R ∗ R^* R∗ yes GT.
experiment
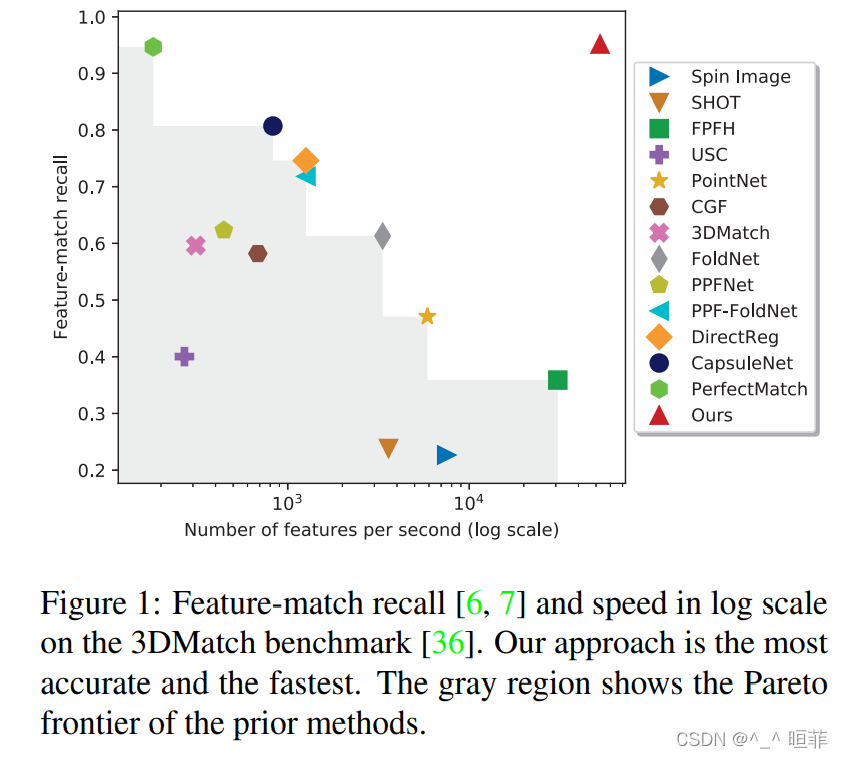
Feature matching recall chart , It can be seen that the proposed method is the best

Visual matching diagram :

visualization KITTI Effect of dataset :

3DMatch Dataset effects : Low dimension , The effect is good .

Ablation Experiment : Output feature dimensions :32 The best .

Ablation Experiment :
For comparative losses , Normalized features are better than non normalized features
Hard sample - Compare the loss ratio Compared with the loss , And the best of all .
For triple loss , Non normalized features are better than normalized features .
Hard sample - Triple loss ratio Triple loss is better , But it can easily lead to collapse .

Different threshold design effects ,
In general , m n m p \frac{m_n}{m_p} mpmn The bigger it is , The better ; But if >30, The effect began to decline .

3D Match Data sets : Registration Recall result . The average effect is the best .

KITTI Effect on dataset :

5. Conclusion and thinking
- be based on Minkowski Convoluted fully connected network , Sparse representation optimizes video memory ;
- The quantization of sparse expression will lose some point cloud information ;
- Loss design , Use hash to speed up the generation of triples ;
- The follow-up work is to use it in the end-to-end point cloud registration task ;
6. Reference resources
版权声明
本文为[^_^ Min Fei]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230611136447.html
边栏推荐
- three. JS text ambiguity problem
- X509 parsing
- mui + hbuilder + h5api模拟弹出支付样式
- Example interview | sun Guanghao: College Club grows and starts a business with me
- Imx6ull QEMU bare metal tutorial 1: GPIO, iomux, I2C
- MySQL 8.0.11下载、安装和使用可视化工具连接教程
- 【动态规划】221. 最大正方形
- AUTOSAR from introduction to mastery 100 lectures (52) - diagnosis and communication management function unit
- decast id.var measure. Var data splitting and merging
- 100000 college students have become ape powder. What are you waiting for?
猜你喜欢
![[official announcement] Changsha software talent training base was established!](/img/ee/0c2775efc4578a008c872022a95559.png)
[official announcement] Changsha software talent training base was established!

Ding ~ your scholarship has arrived! C certified enterprise scholarship list released
【官宣】长沙软件人才实训基地成立!

MySQL 8.0.11 download, install and connect tutorials using visualization tools
![[wechat applet] flex layout usage record](/img/ab/7b2392688d8a0130e671f179e09dce.png)
[wechat applet] flex layout usage record

Melt reshape decast long data short data length conversion data cleaning row column conversion

Example interview | sun Guanghao: College Club grows and starts a business with me

Lpddr4 notes

SHA512 / 384 principle and C language implementation (with source code)

8086 of x86 architecture
随机推荐
RTOS mainstream assessment
Nodejs + Mysql realize simple registration function (small demo)
叮~ 你的奖学金已到账!C认证企业奖学金名单出炉
Loading and using image classification dataset fashion MNIST in pytorch
Request和Response及其ServletContext总结
Mysql数据库的卸载
Solve the problem of Oracle Chinese garbled code
【微信小程序】flex布局使用记录
Feature Engineering of interview summary
CSDN College Club "famous teacher college trip" -- Hunan Normal University Station
Proteus 8.10 installation problem (personal test is stable and does not flash back!)
Xi'an CSDN signed a contract with Xi'an Siyuan University, opening a new chapter in IT talent training
解决虚拟机中Oracle每次要设置ip的问题
Design of STM32 multi-channel temperature measurement wireless transmission alarm system (industrial timing temperature measurement / engine room temperature timing detection, etc.)
「玩转Lighthouse」轻量应用服务器自建DNS解析服务器
Uninstall MySQL database
榜样专访 | 孙光浩:高校俱乐部伴我成长并创业
torch. Where can transfer gradient
ECDSA signature verification principle and C language implementation
Esp32 vhci architecture sets scan mode for traditional Bluetooth, so that the device can be searched