当前位置:网站首页>Multi view depth estimation by fusing single view depth probability with multi view geometry
Multi view depth estimation by fusing single view depth probability with multi view geometry
2022-04-23 08:48:00 【CV scientific research memoir】
Address of thesis :https://arxiv.org/abs/2112.08177
Source code address :https://github.com/baegwangbin/MaGNet
summary
starting point :
- MVS Building multi view matching cost body brings huge video memory consumption
- Monocular depth estimation in the absence of ( weak ) Texture area 、 Reflective surface 、 The estimation effect in the case of moving objects is better than
So , In this paper, a new framework combining single view depth probability and multi view geometry is proposed (Monocular and Geometric Network : MaGNet), For each frame of image ,MaGNet Predict the depth probability distribution of single view , It is parameterized into a Gaussian distribution at the pixel level ; then , The distribution estimated by the reference frame is used to sample the prime depth assumption . This probabilistic sampling strategy enables the network to establish fewer depth assumptions and obtain higher accuracy ; The depth consistency weighting method is also proposed for the multi view matching score , To ensure that the multi view depth is consistent with the single view prediction .
The innovations of the article are as follows : - Probabilistic depth sampling( Depth value sampling based on probability distribution ): The probability distribution is obtained from monocular estimation , Use probability distribution to generate depth assumptions ;
- Depth consistency weighting for multi-view matching( Multi view depth consistency weight ): The depth probability distribution of single view is used to generate multi view matching weight , The multi view matching results are weighted ;
- Iterative refinement( Iterative optimization strategy ): A compact initial matching cost volume is constructed by using the depth hypothesis volume constructed by probability distribution and multi view consistency weight , If there is an error in the depth probability distribution of a single view , As a result, the depth assumption cannot be obtained by sampling . In view of this situation, a strategy based on iterative optimization is proposed , The updated probability distribution is fed back to the probability depth sampling module , Continuously improve the accuracy of probability distribution ;
It mainly includes the following steps :
- Predict the depth probability distribution of a single frame image , And parameterize it into Gaussian distribution ;
- The predicted distribution is used to sample the depth of each pixel of the reference image to obtain the depth assumption value ;
- Using depth assumptions and camera parameters, the features of the reference frame are extracted warp To neighborhood frame , The matching cost is calculated by point multiplication ;
- The matching score of each adjacent view is multiplied by the binary depth consistency weight inferred from the single view depth probability estimated by the view ;
- Using the matching cost volume, the matching probability volume is obtained by cost volume regularization ;
- step 2-5 Iterations can be repeated to improve accuracy ;
In this way , The final output is the pixel by pixel depth probability distribution , From this, we can infer the expected value and related uncertainty .
Model architecture

The goal of the model is to predict the reference frame I t I_t It stay t Depth map of time , Input as pictures in a time series : W t = { I t − 2 Δ t , I t − Δ t , I t , I t + Δ t , I t + 2 Δ t } \mathcal{W}_{t}=\left\{I_{t-2 \Delta t}, I_{t-\Delta t}, I_{t}, I_{t+\Delta t}, I_{t+2 \Delta t}\right\} Wt={ It−2Δt,It−Δt,It,It+Δt,It+2Δt} And camera parameters , Pictured 2 Shown , It mainly includes the following 3 A step :1. Feature extraction and depth probability distribution prediction are carried out for each frame image ;2. The depth hypothesis is sampled through probability distribution , And generate multi view consistency weights ;3. The matching cost volume is used to estimate the multi view depth probability volume ;
Single-View Depth Probability and Features( Single view feature extraction and depth probability distribution construction )
Single-view depth probability
about W t ∈ R H × W \mathcal{W}_t \in R^{H\times W} Wt∈RH×W Each input image in I t I_t It, Use D-Net To predict its depth probability distribution ∈ R H 4 × W 4 \in R^{\frac{H}{4}\times \frac{W}{4}} ∈R4H×4W, about I t I_t It Every pixel ( u , v ) (u, v) (u,v) , The probability distribution is parameterized as follows 1 Shown :
p u , v ( d ∣ I t ) = 1 σ u , v ( I t ) 2 π e − 1 2 ( d − μ u , v ( I t ) σ u , v ( I t ) ) 2 (1) p_{u, v}\left(d \mid I_{t}\right)=\frac{1}{\sigma_{u, v}\left(I_{t}\right) \sqrt{2 \pi}} e^{-\frac{1}{2}\left(\frac{d-\mu_{u, v}\left(I_{t}\right)}{\sigma_{u, v}\left(I_{t}\right)}\right)^{2}}\tag1 pu,v(d∣It)=σu,v(It)2π1e−21(σu,v(It)d−μu,v(It))2(1)
among μ and σ \mu and \sigma μ and σ Is the mean and variance , A lightweight codec structure and EfficientNet B5 As a backbone network , The linear activation layer is used to calculate the mean value μ \mu μ , Use modified ELU Function to calculate the variance σ \sigma σ : f ( x ) = E L U ( x ) + 1 f(x) = ELU(x) +1 f(x)=ELU(x)+1, This ensures that the calculated variance is positive , And has a smooth gradient ; When training the rest of the modules, you need to D-Net The weights are frozen ; Use NLL Loss to monitor model training :
L u , v ( d u , v g t ∣ I t ) = 1 2 log σ u , v 2 ( I t ) + ( d u , v g t − μ u , v ( I t ) ) 2 2 σ u , v 2 ( I t ) (2) L_{u, v}\left(d_{u, v}^{\mathrm{gt}} \mid I_{t}\right)=\frac{1}{2} \log \sigma_{u, v}^{2}\left(I_{t}\right)+\frac{\left(d_{u, v}^{\mathrm{gt}}-\mu_{u, v}\left(I_{t}\right)\right)^{2}}{2 \sigma_{u, v}^{2}\left(I_{t}\right)}\tag2 Lu,v(du,vgt∣It)=21logσu,v2(It)+2σu,v2(It)(du,vgt−μu,v(It))2(2)
The above formula means , At the boundary point of the object , When the model is difficult to reduce ( d g t − μ ) 2 (d^{gt}-\mu)^2 (dgt−μ)2 The error of the , Will make the standard deviation σ 2 \sigma^2 σ2 Larger to make the second term smaller , The first will limit the variance to too large ; In non boundary areas , At this time, the correct depth value is different from the estimated depth value μ \mu μ Close , The second term is approximately 0, In order to make the whole loss function smaller , The model tends to make the first term smaller , That is to say σ 2 \sigma^2 σ2 smaller ;
Single-view features
Use F-Net To extract the features of each picture ∈ R H 4 × W 4 \in R^{\frac{H}{4}\times \frac{W}{4}} ∈R4H×4W, Then the matching cost volume is calculated based on the point multiplication of the corresponding point eigenvector , For pixels ( u , v ) (u, v) (u,v) At depth { d k } k = 1 N s \{d_k\}_{k=1}^{N_s} {
dk}k=1Ns, The matching cost is as follows 3 Shown :
s u , v , k ( I t ) = ∑ i ≠ t * f u , v ( I t ) , f u i k , v i k ( I i ) * (3) s_{u, v, k}\left(I_{t}\right)=\sum_{i \neq t}\left\langle\mathbf{f}_{u, v}\left(I_{t}\right), \mathbf{f}_{u_{i k}, v_{i k}}\left(I_{i}\right)\right\rangle\tag3 su,v,k(It)=i=t∑*fu,v(It),fuik,vik(Ii)*(3)
stay depth Dimensionality softmax Get the probability body p u , v , k = s o f r m a x k ( s u , v , k ) p_{u,v,k}=sofrmax_k(s_{u, v, k}) pu,v,k=sofrmaxk(su,v,k), Finally, the depth map is calculated based on the expectation d ^ u , v = ∑ k p u , v , k ⋅ d k \hat{d}_{u,v}=\sum_{k}p_{u,v,k}\cdot d_k d^u,v=∑kpu,v,k⋅dk,F-Net By uniformly sampling the depth of the assumed volume { d k } \{d_k\} { dk} And minimize d u , v ^ And d u , v g t \hat{d_{u,v}} And d_{u,v}^{gt} du,v^ And du,vgt Between L1 Get the pre training weight ;
Fusing Single-View Depth Probability with Multi-View Geometry( Single view depth probability distribution and multi view geometric information fusion )

notes : This process has no parameters to learn ( No gradient descent is required )
Probabilistic depth sampling( Depth hypothesis sampling based on probability distribution )
In this paper, the depth assumption value of each pixel is defined, and the search range is [ μ u , v − β σ u , v , μ u , v + β σ u , v ] [\mu_{u,v}-\beta\sigma_{u,v}\ , \ \mu_{u,v}+\beta\sigma_{u,v}] [μu,v−βσu,v , μu,v+βσu,v], KaTeX parse error: Undefined control sequence: \bata at position 1: \̲b̲a̲t̲a̲ For a super parameter , Then divide the search scope into 10 Intervals , This allows more depth assumptions to approach μ u , v \mu_{u,v} μu,v , The midpoint of each interval is the assumed value of depth , The first k A depth assumption d u , v , k d_{u,v,k} du,v,k The definition is as follows 4 Shown :
d u , v , k = μ u , v + b k σ u , v w h e r e b k = 1 2 [ Φ − 1 ( k − 1 N s P ∗ + 1 − P ∗ 2 ) + Φ − 1 ( k N s P ∗ + 1 − P ∗ 2 ) ] (4) d_{u, v, k}=\mu_{u, v}+b_{k} \sigma_{u, v} \\ \ \\where \ \ \ \ \begin{aligned} b_{k}=\frac{1}{2}[& \Phi^{-1}\left(\frac{k-1}{N_{s}} P^{*}+\frac{1-P^{*}}{2}\right) &\left.+\Phi^{-1}\left(\frac{k}{N_{s}} P^{*}+\frac{1-P^{*}}{2}\right)\right] \end{aligned}\tag4 du,v,k=μu,v+bkσu,v where bk=21[Φ−1(Nsk−1P∗+21−P∗)+Φ−1(NskP∗+21−P∗)](4)
among , Φ − 1 ( . ) \Phi^{-1}(.) Φ−1(.) It's a probability function , and P ⋆ = e r f ( β / 2 ) P^\star = erf(\beta / \sqrt2) P⋆=erf(β/2) Indicates the interval [ μ u , v − β σ u , v , μ u , v + β σ u , v ] [\mu_{u,v}-\beta\sigma_{u,v}\ , \ \mu_{u,v}+\beta\sigma_{u,v}] [μu,v−βσu,v , μu,v+βσu,v] The probability mass of ;
notes : { b k } \{b_k\} {
bk} Only with N s N_s Ns and β \beta β of , There is no need to calculate per pixel ;
chart 3 The left side compares the uniform sampling with the sampling method proposed in this paper , For pixels with high uncertainty , Increase the spacing between candidate points , Thus, a wider range of candidate points can be evaluated .
Depth consistency weighting( Depth consistency weight )
If the depth assumption is correct , Explain the corresponding 3D The point is on the surface of the object , If this 3D The point is visible in the neighborhood view , Then the probability value of the corresponding single view to this depth should be high ; Equivalent to “ If the single view depth probability of the depth assumption estimated from adjacent views is low , It means that the depth candidate is wrong or it is not visible in the view ( For example, due to occlusion )”; So , The score of multi view matching is as follows 5 Shown :
s u , v , k ( I t ) = ∑ i ≠ t w u i k , v i k , d i k d c * f u , v ( I t ) , f u i k , v i k ( I i ) * w u i k , v i k , d i k d c = δ ( p u i k , v i k ( d i k ∣ I i ) > p thres ) (5) \begin{aligned} s_{u, v, k}\left(I_{t}\right) &=\sum_{i \neq t} w_{u_{i k}, v_{i k}, d_{i k}}^{\mathrm{dc}}\left\langle\mathbf{f}_{u, v}\left(I_{t}\right), \mathbf{f}_{u_{i k}, v_{i k}}\left(I_{i}\right)\right\rangle \\ \\ w_{u_{i k}, v_{i k}, d_{i k}}^{\mathrm{dc}} &=\delta\left(p_{u_{i k}, v_{i k}}\left(d_{i k} \mid I_{i}\right)>p_{\text {thres }}\right) \end{aligned}\tag5 su,v,k(It)wuik,vik,dikdc=i=t∑wuik,vik,dikdc*fu,v(It),fuik,vik(Ii)*=δ(puik,vik(dik∣Ii)>pthres )(5)
among , When the depth probability of single view p u i k , v i k ( d i k ∣ I i ) > p thres p_{u_{i k}, v_{i k}}\left(d_{i k} \mid I_{i}\right)>p_{\text {thres }} puik,vik(dik∣Ii)>pthres when , w u i k , v i k , d i k d c = 1 w_{u_{i k}, v_{i k}, d_{i k}}^{\mathrm{dc}}=1 wuik,vik,dikdc=1 , Or equal to 0, take s u , v , k ( I t ) s_{u, v, k}\left(I_{t}\right) su,v,k(It) As the depth consistency weight ; p thres p_{\text {thres }} pthres The setting of is very important , Too many candidate depth values will be eliminated ( It may contain the correct depth value ); Set in the text p thres = exp ( − κ 2 / 2 ) / σ u i k , v i k 2 π p_{\text {thres }}=\exp \left(-\kappa^{2} / 2\right) / \sigma_{u_{i k}, v_{i k}} \sqrt{2 \pi} pthres =exp(−κ2/2)/σuik,vik2π, If d i , k d_{i,k} di,k stay k-sigma Within the confidence interval of p Will tend to 1, p thres p_{\text {thres }} pthres Is determined by each pixel and the view ; If D-Net Uncertainty about the predicted depth ( σ \sigma σ It's big ), be p t h r e s p_{thres} pthres Very low , More depth assumptions can be considered ;
Depth consistency weighting can eliminate candidate depth values with low single view depth probability . Especially when the multi view matching is not clear or reliable , This weighting method can improve the robustness of the model . for example , If the pixel is within a textured surface , A wide range of depth candidates will result in similar matching scores . If the scene contains reflective surfaces , The matching score is calculated between reflections , This leads to overestimation of depth . In both cases ,MaGNet Both can make robust prediction by favoring depth candidates with high single view depth probability .
Estimating Multi-View Depth Probability Distribution ( Multi view depth probability distribution estimation )
Updating single-view depth probability distribution( Update the single view depth probability distribution )
Thanks to the depth hypothesis sampling strategy based on probability distribution , The dimension of the matching cost obtained by the model is H 4 × W 4 × N s \frac{H}{4}\times \frac{W}{4} \times N_s 4H×4W×Ns , among N s N_s Ns Is the number of depth assumptions ; Enter it as , Use G-Net Update the mean and variance of single view to estimate the multi view depth probability distribution ; because µ u , v µ_{u,v} µu,v and σ u , v σ_{ u,v} σu,v Not coded in input , It is difficult to update the mean and variance of by direct regression . So ,G-Net Adopt the idea of residual learning , Estimate the normalized residual value of mean and variance Δ μ u , v / σ u , v \Delta \mu_{u, v} / \sigma_{u, v} Δμu,v/σu,v. For example, when the parallax of two pixels is k ′ k^\prime k′ When the match score is high , Model to learn b k ′ b_{k^\prime} bk′ To update the mean : μ u , v new = μ u , v + b k ′ σ u , v \mu_{u, v}^{\text {new }}=\mu_{u, v}+b_{k^{\prime}} \sigma_{u, v} μu,vnew =μu,v+bk′σu,v. Empathy ,G-Net Study σ u , v new / σ u , v \sigma_{u, v}^{\text {new }} / \sigma_{u, v} σu,vnew /σu,v To update the variance value ; In this way, the depth probability distribution of multi view is updated ; notes :G-Net The output of can be fed back to the sampling module , And the process can be repeated to continuously optimize the output .
Learned upsampling( Learnable upsampling )
G-Net The output of is a multi view probability distribution diagram ∈ R 2 × H 4 × W 4 \in R^{2\times \frac{H}{4}\times \frac{W}{4}} ∈R2×4H×4W, In order to sample this probability distribution map to the original resolution , In this paper, a learning up sampling strategy is proposed : The input to the model is D-Net Characteristic graph , Use a lightweight CNN To predict the R 1 × ( 3 ∗ 3 ) × 4 × 4 × H 4 × W 4 ) R^{1\times(3*3)\times4\times4\times\frac{H}{4}\times \frac{W}{4})} R1×(3∗3)×4×4×4H×4W) Of mask (4 Represents the scale of the original image ) , Plot the probability distribution R 2 × H 4 × W 4 R^{2\times \frac{H}{4}\times \frac{W}{4}} R2×4H×4W Every point of 3 × 3 3\times3 3×3 Take out the neighborhood pixels of , Form neighborhood characteristic graph ∈ R 2 × ( 3 ∗ 3 ) × 1 × 1 × H 4 × W 4 \in R^{2\times(3*3)\times 1\times1\times\frac{H}{4}\times\frac{W}{4}} ∈R2×(3∗3)×1×1×4H×4W , With the mask After dot multiplication, it will be in 3 ∗ 3 3*3 3∗3 Sum the dimensions to get R 2 × 4 × 4 × H 4 × W 4 R^{2\times 4\times4\times\frac{H}{4}\times\frac{W}{4}} R2×4×4×4H×4W , Last resize obtain R 2 × H × W R^{2 \times H\times W} R2×H×W
def upsample_depth_via_mask(depth, up_mask, k):
# depth: low-resolution depth (B, 2, H, W)
# up_mask: (B, 9*k*k, H, W)
N, o_dim, H, W = depth.shape
up_mask = up_mask.view(N, 1, 9, k, k, H, W)
up_mask = torch.softmax(up_mask, dim=2) # (B, 1, 3*3, k, k, H, W)
up_depth = F.unfold(depth, [3, 3], padding=1) # (B, 2, H, W) -> (B, 2 X 3*3, H*W)
up_depth = up_depth.view(N, o_dim, 9, 1, 1, H, W) # (B, 2, 3*3, 1, 1, H, W)
up_depth = torch.sum(up_mask * up_depth, dim=2) # (B, 2, k, k, H, W)
up_depth = up_depth.permute(0, 1, 4, 2, 5, 3) # (B, 2, H, k, W, k)
return up_depth.reshape(N, o_dim, k*H, k*W) # (B, 2, k*H, k*W)
Iterative refinement and network training( Iterative optimization and model training )
Through repeated iterations N i t e r N_{iter} Niter Multiple view matching process ( Depth hypothesis sampling based on probability distribution ——> Multi view consistency weight matching ——> adopt G-Net Update the probability distribution parameters ) You can get N i t e r N_{iter} Niter A prediction ; Calculate the formula in each iteration 2 Of NLL Loss , Calculated by each iteration NLL The loss is multiplied by γ N iter − i \gamma^{N_{\text {iter }}-i} γNiter −i ( The weight of the back is greater than that of the front ), The sum of these losses is used to train G-Net With a learnable mountain sampling module ;
This iterative strategy has two benefits : (1) If in an iteration , The matching score of a pixel is high , Then the mean value of the depth hypothesis space will converge to the predicted depth value of the pixel and the variance will decrease , In the next iteration, we will look for the depth hypothesis space near the last maximum value , This can lead to higher matching scores ;(2) Iterative updates can also prevent D-Net Inaccurate prediction leads to model collapse , For example, the of a pixel Ground True The search scope of the initial depth assumption space is no longer [ μ u , v − β σ u , v , μ u , v + β σ u , v ] [\mu_{u,v}-\beta \sigma_{u,v}, \mu_{u,v} + \beta \sigma_{u,v}] [μu,v−βσu,v,μu,v+βσu,v] Inside , No candidate depth value can get a high matching score , In this case G-Net Will be reduced by 2 Of NLL Loss value to get a larger variance value , In the next iteration, we can find the depth value in a wider range ;
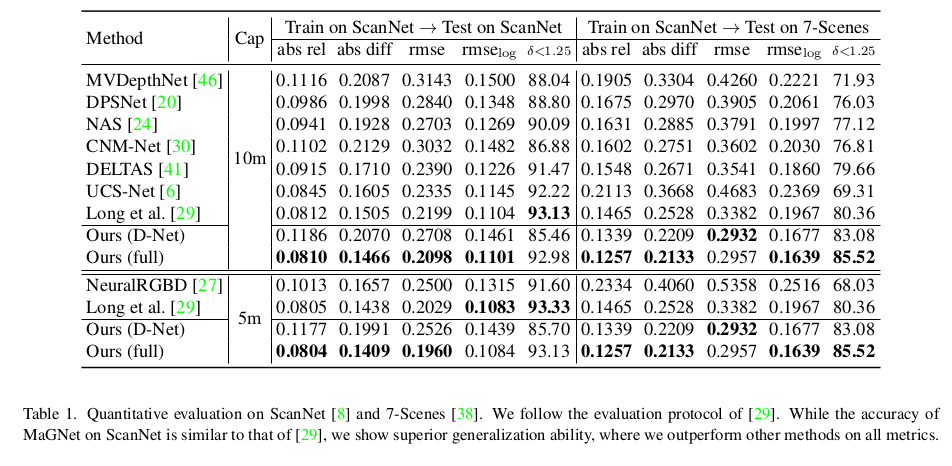
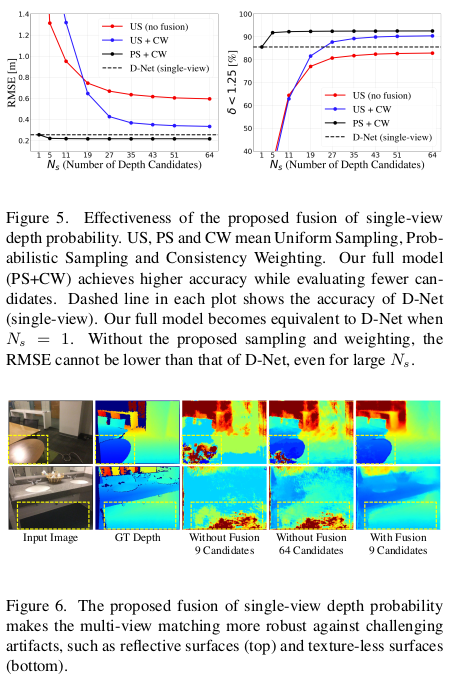
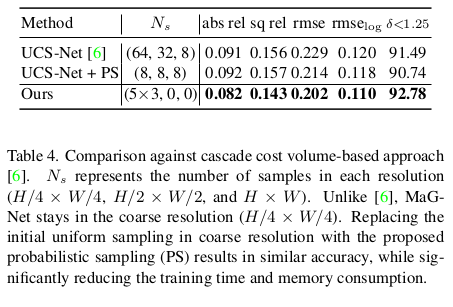
experimental result




版权声明
本文为[CV scientific research memoir]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230846539979.html
边栏推荐
- PCTP考试经验分享
- L2-3 浪漫侧影 (25 分)
- Search tree judgment (25 points)
- 错误: 找不到或无法加载主类
- idea打包 jar文件
- STM32 uses Hal library. The overall structure and function principle are introduced
- Go语言自学系列 | golang方法
- Talent Plan 学习营初体验:交流+坚持 开源协作课程学习的不二路径
- IDEA导入commons-logging-1.2.jar包
- Flash project cross domain interception and DBM database learning [Baotou cultural and creative website development]
猜你喜欢

Harbor企业级镜像管理系统实战

L2-022 rearrange linked list (25 points) (map + structure simulation)

Automatic differentiation and higher order derivative in deep learning framework

L2-024 tribe (25 points) (and check the collection)

Use of Arthas in JVM tools

GUI编程简介 swing

共享办公室,提升入驻体验

LaTeX论文排版操作

bashdb下载安装

洋桃電子STM32物聯網入門30步筆記一、HAL庫和標准庫的區別
随机推荐
1099 建立二叉搜索树 (30 分)
Type anonyme (Principes fondamentaux du Guide c)
2022-04-22 OpenEBS云原生存储
Enterprise wechat application authorization / silent login
Introduction to GUI programming swing
IDEA导入commons-logging-1.2.jar包
Go语言自学系列 | golang嵌套结构体
Idea package jar file
匿名類型(C# 指南 基礎知識)
OneFlow学习笔记:从Functor到OpExprInterpreter
请提前布局 Star Trek突破链游全新玩法,市场热度持续高涨
idea打包 jar文件
Error: cannot find or load main class
虚拟线上展会-线上vr展馆实现24h沉浸式看展
Latex mathematical formula
okcc呼叫中心外呼系统智能系统需要用多大的盘存录音?
Large amount of data submitted by form post
How much inventory recording does the intelligent system of external call system of okcc call center need?
Introduction to matlab
Single chip microcomputer nixie tube stopwatch