当前位置:网站首页>Redis学习笔记【二】
Redis学习笔记【二】
2022-08-11 05:31:00 【爱吃西瓜爱吃肉】
--mget:获得多个key的值
--mset:同时设置多个键值对
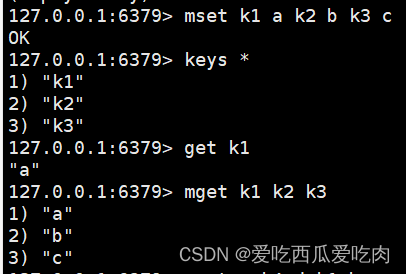
--msetnx:和mset一样 ,不同的是,如果设置的key有相同的,该行命令会执行失败。而mset同样和set一致,如果遇到相同key会覆盖前面设置的
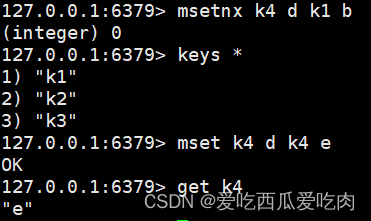
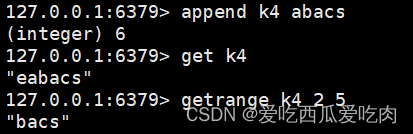
--getrange <key><起始位置><.结束位置>:获取值的范围,类似Java的substring
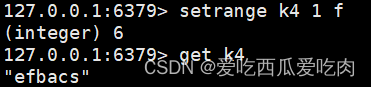
--setrange <key><位置><字符>:在key值的指定位置替换指定字符
--setex <key><过期时间><value>:替换或创建key-value值,同时设置过期时间
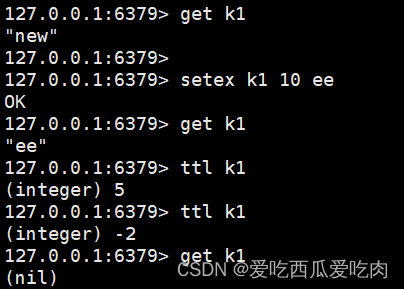
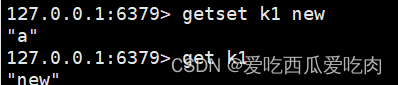
--getset key value:新value值换旧值,返回的是旧值
Redis列表List
单键多值
Redis列表是简单的字符串列表,按照插入顺序排序,可实现双向添加。底层实际是双向链表,对两端的操作性高,通过索引下标的操作,中间的节点性能较差
在列表元素较少的情况下会使用一块连续的内存存储,此结构时ziplist,即压缩列表。将所有元素紧挨在一起存储。当数据较多时会改为quicklist(即将链表和压缩链表结合起来)

--lpush <key><value1><value2>....:从头部插入多个数据
--lrange <key><起始位置><终止位置>:按范围获取key数据(0~-1全部数据)

--rpush <key><value1><value2>....:从尾部插入多个数据
![]()
--lpop/rpop <key>:从左边/右边拿出key的一个值(不是查询是拿出!!)
键在值在,值光键亡
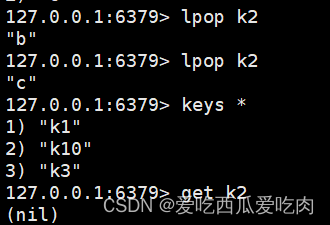
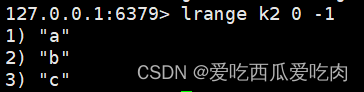
--rpoplpush <key1><key2>:从key1列表右边抽出一个值,插入到key2列表左边
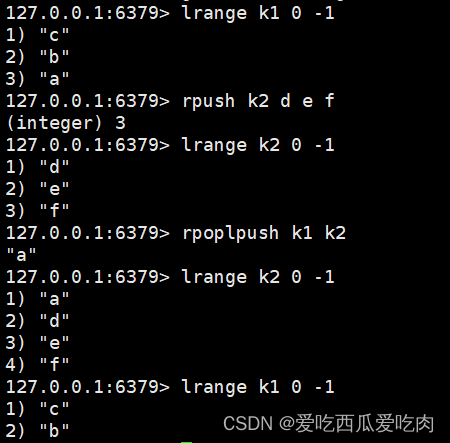
--lindex <key><index>:获取第index+1的值
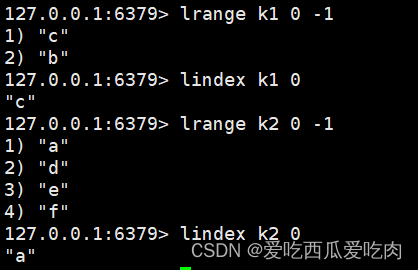
--llen <key>获得列表长度

--linsert <key> before/after <value><newvalue>在key列表value值的前/后插入新值,如果没有该value,返回-1执行不成功

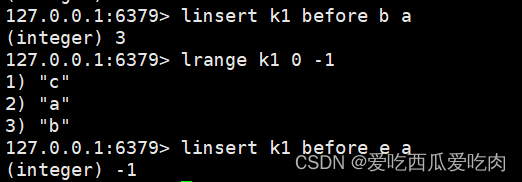
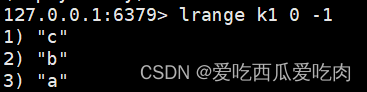
--lrem <key><n><value>:从左边删除n个value(k1原始数据:c a b)
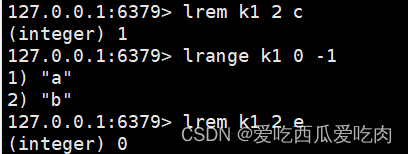
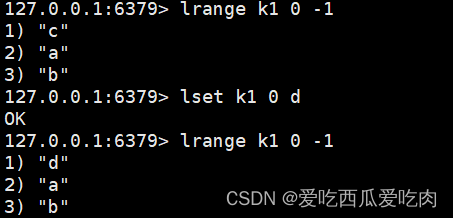
--lset<key><index><value>:替换key列表index下标的值
Redis集合Set
类似List,最大区别是Set自动排重(无序,不可重复),数据结构时dict字典,字典由哈希表实现
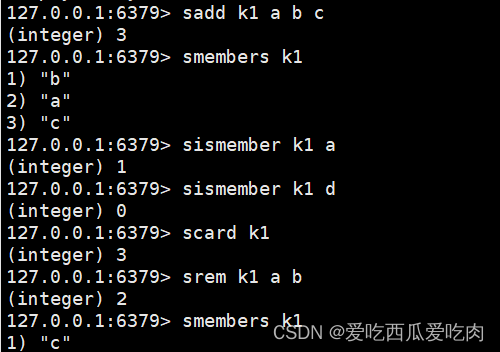
--sadd <key><value><value>....:插入多个member元素,重复忽略
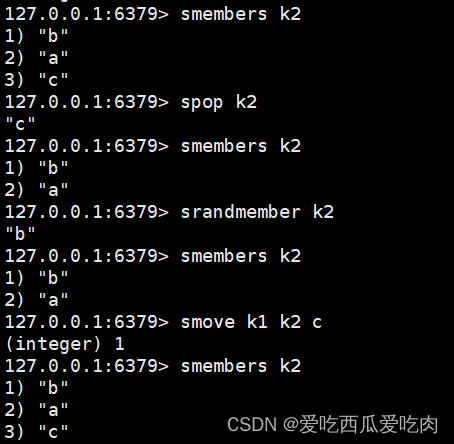
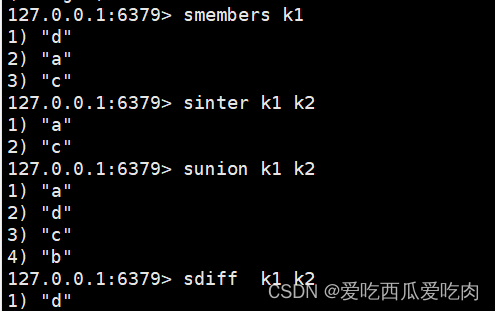
--smembers <key>:取出多个值
--sismember <key><value>:判断该集合中是否有该值,有1无0
--scard <key>:返回该集合的元素个数
--srem <key><value1><value2>...:删除集合中的元素
--spop<key>:随机从该集合中吐出一个值
--srandmember <key><n>:随机从该集合中查询出n个值
--smove <k1><k2><value>:把k1集合中value转到k2集合
--sinter <key1><key2>:返回两个集合的交集元素
--sunion <key1><key2>:返回并集
--sdiff <key1><key2>:返回差集(key1中不包括key2的)
Redis集合hash
Redis hash是一个string类型的field和value的映射表,特别适合存储对象,类似Java中的Map<String,Object>
在列表元素较少的情况下会使用一块连续的内存存储,此结构时ziplist,即压缩列表。将所有元素紧挨在一起存储。当数据较多时会改为HashTable
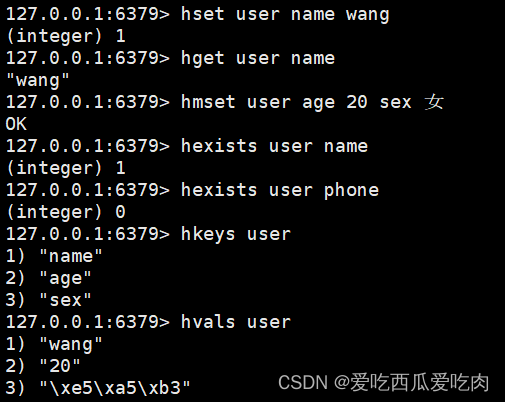
--hset <key><field><value>:给集合中field赋值
--hget <key1><field>:从集合的field取值
--hmset <key1><field><value1><field2><value2>......:批量给集合赋值
--hexists<key1><field>:判断field是否存在key集合中
--hkeys<key>:列出集合中所有field
--hvals<key>:列出集合中所有value
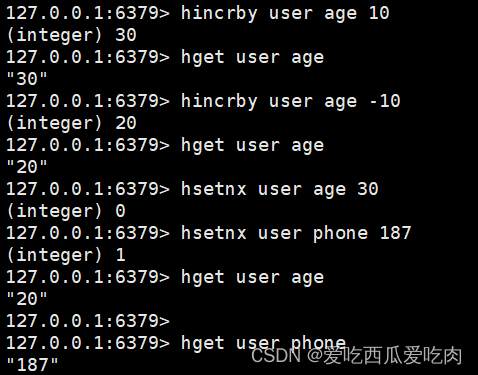
--hincrby<key><field><increment>:为哈希表中field的值加上1/-1
--hsetnx<key><field><value>:将field的值设为value,当且仅当field不存在
Redis集合Zset
Redis有序集合zset与普通集合set非常相似,是没有重复元素的字符串集合
最大的不同时有序集合的每个成员都关联了一个评分,评分被用来按照从最低分到最高分的方式排序集合中的成员,集合中的成员是是唯一的,但是评分可以重复
底层数据结构:2
1.hash ,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到响应的score值
2.跳跃表,目的在于给元素value排序,根据score的范围获取元素列表
--zadd <key><score1><value1><score2><value2>....:key集合中添加分数为score值为value的多条数据
--zrange <key><start><stop>[withscores]:返回有序集合,下标在start、stop之间的元素,按分数从小到大排序。加上withscores返回带分数的所有值
--zrangebyscore key minmax [withscores][limit offset count]:返回有续集中,所有score介于min和max之间的值,按从小到大
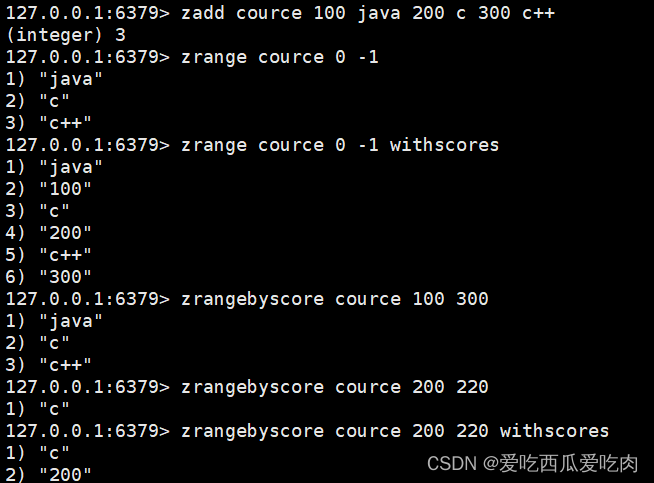
--zrevrangebyscore key maxmin[withscores][limit offset count]:返回所有score介于min和max之间的值,按大到小排序
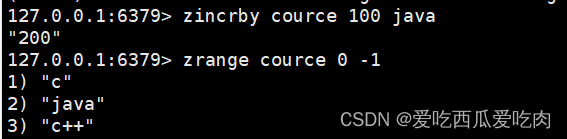
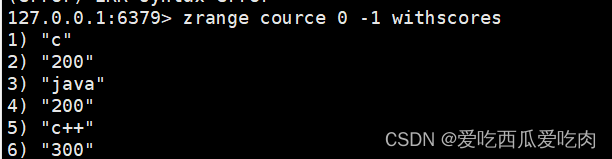
--zincrby <key><increment><value>:为元素score加上增量
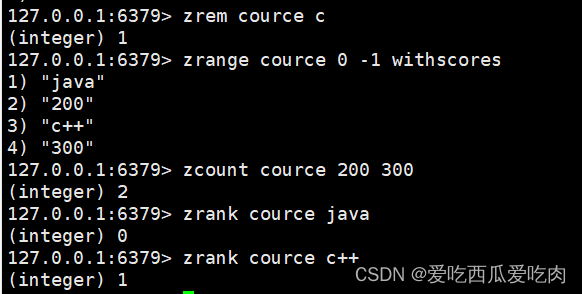
--zrem <key><values>:删除指定元素
--zcount <key><min><max>:统计分数区间内的元素个数
--zrank <key><value>:返回该值在集合中的排名,从0开始
边栏推荐
猜你喜欢
Real-time Feature Computing Platform Architecture Methodology and Practice Based on OpenMLDB

【LeetCode-36】有效的数独

C语言-内存操作函数
C语言-6月8日-求两个数的最小公倍数和最大公因数;判断一个数是否为完数,且打印出它的因子
The whole process of Tinker access --- Compilation
C语言-7月21日-指针的深入

Unity的程序集Assembly 与 加快代码编译速度
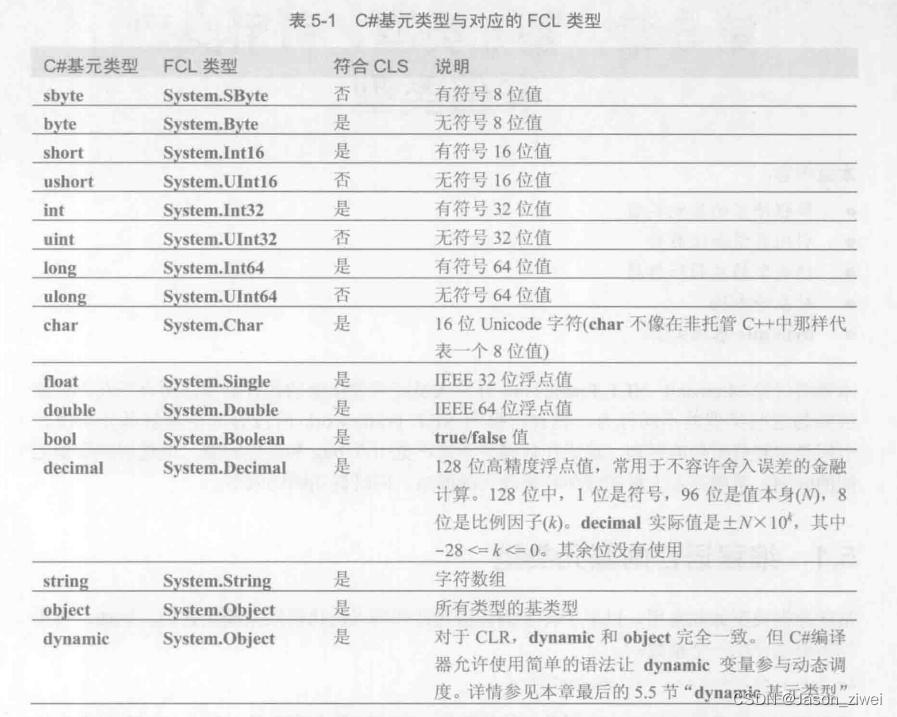
CLR via C# 第五章 基元类型、引用类型和值类型
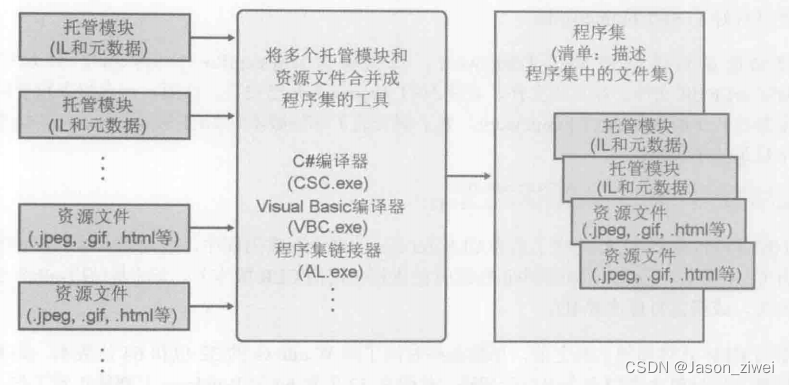
CLR via C# 第一章 CLR的执行模型
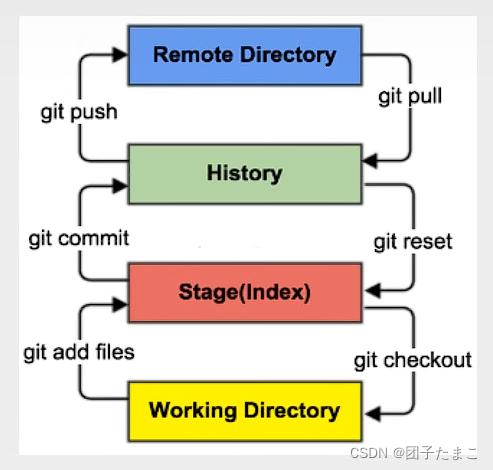
Day 83
随机推荐
BaseFragment的抽取
USB URB
unity小技巧
vim 编辑器使用学习
heap2 (tcache attack,house of orange)
【LeetCode-56】合并区间
星盟-pwn-babyheap
【LeetCode-13】罗马数字转整数
OpenGL 简化点光源与平行光的对比实验
基于微信小程序云开发实现的电商项目,可以自行定制开发
buuctf hacknote
Day 79
C语言-7月22日- NULL和nullptr的深入了解以及VScode对nullptr语句报错问题的解决
微信小程序云开发项目wx-store代码详解
Use the adb command to manage applications
手把手导入企业项目(快速完成本地项目配置)
【Unity】关于一个炮台Prefab的剖析
【LeetCode-75】 颜色分类
星盟-pwn-babyfmt
IO流和序列化与反序列化