当前位置:网站首页>线上突然查询变慢怎么核查
线上突然查询变慢怎么核查
2022-08-10 23:47:00 【闲猫】
目录
系统架构
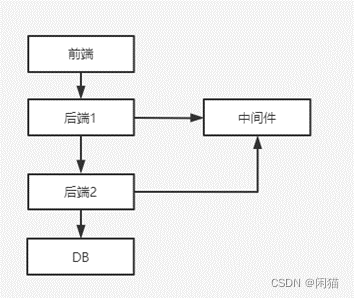
- 网络
- 对中间件的竞争
- 后端服务本身慢
- 竞争DB本身
- DB查询慢
网络层面
网络丢包,重传
如果涉及双数据中心,或者多中心办公场景,就会有这种情况。
可以长时间ping测试丢包情况。
网卡满 比如大字段
使用dstat命令测试网络拥堵情况
网络链路变长
涉及系统集成,涉及老系统,如果调用链路长会导致此类问题。
如果有cat这类分布式链路追踪系统,可以看,否则不怎么好搞
受到IO影响
如果数据库服务 可能有备份服务导致的磁盘IO,CPU,内存被大量占用,导致查询变慢。本质是其他服务占用了“主服务”资源导致。
后端服务如果大批量写文件会导致磁盘IO抢占,导致操作慢
核查:
- 使用top检查CPU,内存占用的进程
- 如果是后端服务,查询线程占用内存情况,top -Hp PID
- 用linux dstat验证IO读写情况
CPU/MEM
CPU和内存 一般都是其他服务被占用导致
服务
资源抢占
比如redis锁,DB连接 等。这类如果并发高就会导致大量线程处于等待状况。
检查:
- jstack 输出java栈
- jmap dump快照,使用jvisualvm,jprofiler,mat等工具分析
FullGc
频繁FullGC会造成服务卡顿,CPU占有率升高
检查:
- 用jstat -gcutil pid 查看gc数量和时间
- 使用dump文件分析 可能的内存泄露
数据库
没有走索引
随着数据库变多,如果正好某个查询条件没有走索引,查询会比较慢。
检查:
- 查看慢sql
- 查看执行计划explain
并行更新同一条数据
常见的秒杀场景:数据库并发执行update,更新同一行的动作会被其他已经持有锁的会话堵住,并且需要要进行判断会不会由于自己的加入导致死锁
数据分布不均
a=11,10条数据
a=21,10W数据,查询自然不同
查询不合适
select *** from tt limit 10000000,10;
这类需要先找到10000000条,然后往后找10条
调整为:
select * from tt where id >= 10 limit 10;
表设计有问题
varchar(2000) text
调整:
- 纵向拆分,将varchar 2000 这种字段拆分到另一个表
innodb 刷脏页
InnoDB引擎采用Write Ahead Log(WAL)策略,即事务提交时,先写日志(redo log),再写磁盘。为了提高IO效率,在写日志的时候会先写buffer,然后集中flush buffer pool 到磁盘。 这个过程 我们称之为刷脏页。
这个过程中就有可能导致平时执行很快的SQL突然变慢。
边栏推荐
猜你喜欢

随机推荐
10. Notes on receiving parameters
2022下半年软考「高项」易混淆知识点汇总(2)
如何判断一个数为多少进制?
C语言篇,操作符之 移位运算符(>>、<<)详解
[21天学习挑战赛——内核笔记](五)——devmem读写寄存器调试
[C language] Implementation of guessing number game
回收站的文件删了怎么恢复,回收站文件恢复的两种方法
[C Language Chapter] Detailed explanation of bitwise operators (“<<”, “>>”, “&”, “|”, “^”, “~”)
14. Thymeleaf
一条SQL查询语句是如何执行的?
SQL注入基础---order by \ limit \ 宽字节注入
给肯德基打工的调料商,年赚两亿
7. yaml
后疫情时代,VR全景营销这样玩更加有趣!
proxy代理服务_2
Part of the reserve bank is out of date
String
Summary of Confused Knowledge Points for "High Items" in the Soft Examination in the Second Half of 2022 (2)
英文文献阅读时,如何做笔记?
Design and implementation of flower online sales management system