当前位置:网站首页>SQL: query duplicate data and delete duplicate data
SQL: query duplicate data and delete duplicate data
2022-04-23 20:24:00 【First code】
1. Single column
select * from test
where name in (select name from test group by name having count
(name) > 1 select * from [ Department information summary ]
where Effective or not = 1 and [ Department name ] in (select [ Department name ] from [ Department information summary ] where Effective or not =1 group by [ Department name ] having count
([ Department name ]) > 1)
and Where in (select Where from[ Department information summary ] group by Where having count
( Where ) > 1)
2 Multiple columns
SELECT a.* FROM test a,(
SELECT name,code
FROM test
GROUP BY name,code
HAVING COUNT(1)>1
) AS b
WHERE a.name=b.name AND a.code=b.code3 Delete duplicate data
Take deleting duplicate ID cards as an example
delete from Test
where ID number in( select ID number from Test group by ID number having count( ID number ) > 1) and
TK not in(select max(TK) from Test group by ID number having count( ID number ) > 1 )Query duplicate ID card
select ID number ,count(*) from Test group by ID number having count(*) > 1版权声明
本文为[First code]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204210551267930.html
边栏推荐
- R language ggplot2 visualization: ggplot2 visualizes the scatter diagram and uses geom_ mark_ The ellipse function adds ellipses around data points of data clusters or data groups for annotation
- 考研英语唐叔的语法课笔记
- Markdown < a > tag new page open link
- Still using listview? Use animatedlist to make list elements move
- 波场DAO新物种下场,USDD如何破局稳定币市场?
- 論文寫作 19: 會議論文與期刊論文的區別
- LeetCode 994、腐烂的橘子
- Linux64Bit下安装MySQL5.6-不能修改root密码
- PCL点云处理之基于PCA的几何形状特征计算(五十二)
- 2022dasctf APR x fat epidemic prevention challenge crypto easy_ real
猜你喜欢
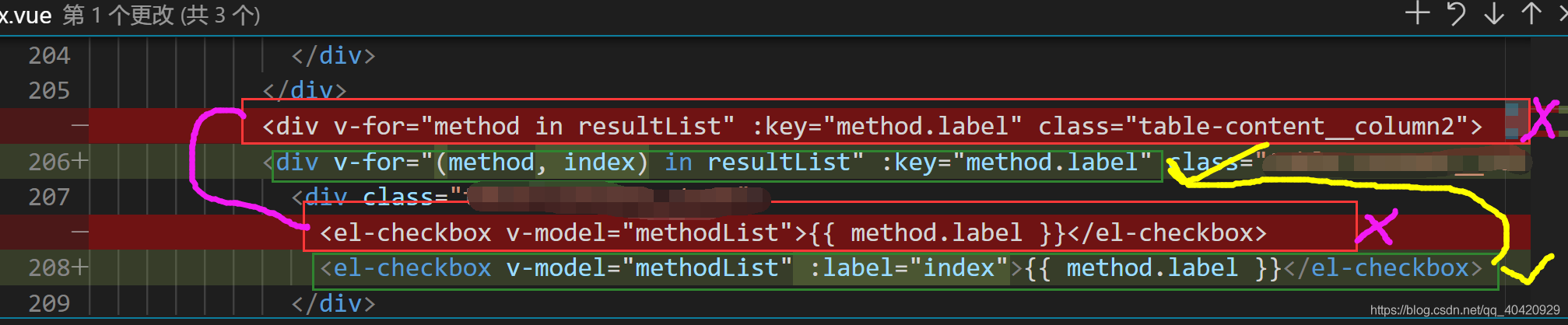
Click an EL checkbox to select all questions

DTMF双音多频信号仿真演示系统
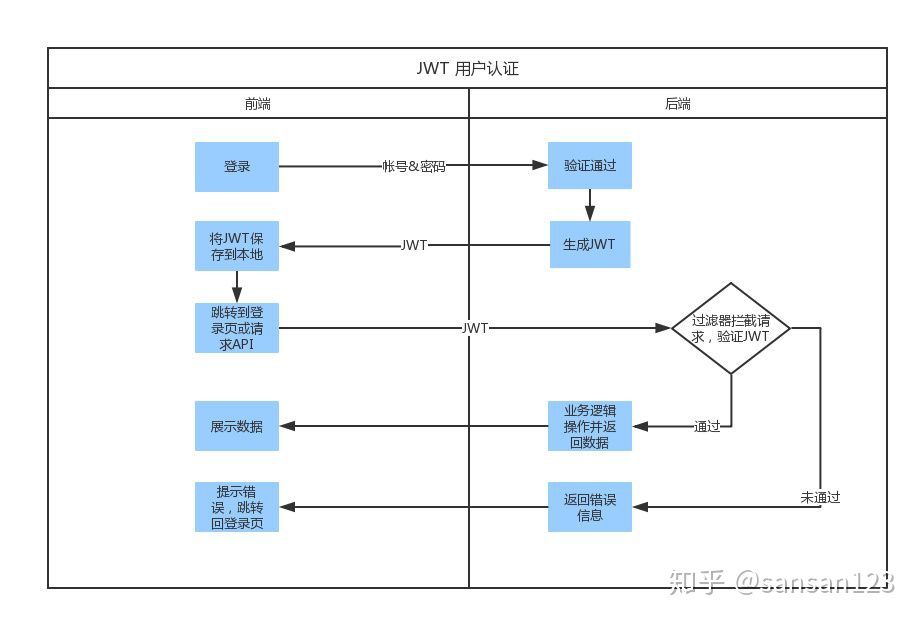
Five minutes to show you what JWT is
![[PTA] l1-002 printing hourglass](/img/9e/dc715f7debf7edb7a40e9ecfa69cef.png)
[PTA] l1-002 printing hourglass
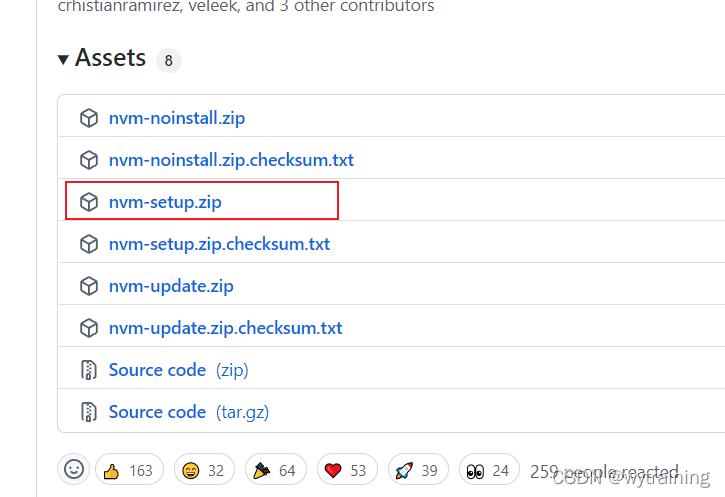
Installation and use of NVM
![Es error: request contains unrecognized parameter [ignore_throttled]](/img/17/9131c3eb023b94b3e06b0e1a56a461.png)
Es error: request contains unrecognized parameter [ignore_throttled]
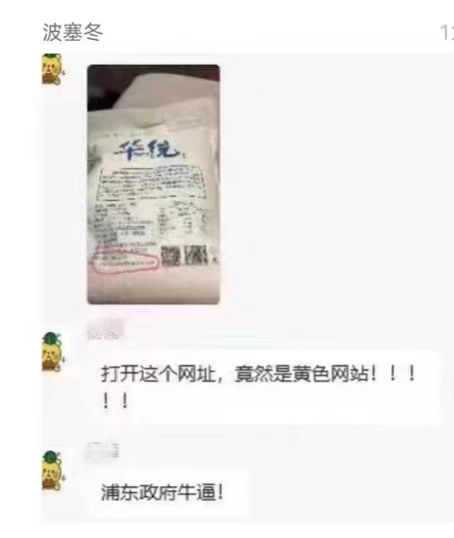
上海回應“面粉官網是非法網站”:疏於運維被“黑”,警方已立案

go-zero框架数据库方面避坑指南

selenium.common.exceptions.WebDriverException: Message: ‘chromedriver‘ executable needs to be in PAT
Numpy - creation of data type and array
随机推荐
[target tracking] pedestrian attitude recognition based on frame difference method combined with Kalman filter, with matlab code
如何做产品创新?——产品创新方法论探索一
R language survival package coxph function to build Cox regression model, ggrisk package ggrisk function and two_ Scatter function visualizes the risk score map of Cox regression, interprets the risk
Es keyword sorting error reason = fielddata is disabled on text fields by default Set fielddata = true on keyword in order
【PTA】L2-011 玩转二叉树
[problem solving] 'ASCII' codec can't encode characters in position XX XX: ordinal not in range (128)
On BIM data redundancy theory
Leetcode dynamic planning training camp (1-5 days)
How about CICC fortune? Is it safe to open an account
Some basic knowledge of devexpress report development
Scrapy教程 - (2)寫一個簡單爬蟲
Introduction to link database function of cadence OrCAD capture CIS replacement components, graphic tutorial and video demonstration
SQL Server Connectors By Thread Pool | DTSQLServerTP plugin instructions
Numpy Index & slice & iteration
Mathematical modeling column | Part 5: MATLAB optimization model solving method (Part I): Standard Model
go-zero框架数据库方面避坑指南
JDBC database addition, deletion, query and modification tool class
DTMF双音多频信号仿真演示系统
How to do product innovation—— Exploration of product innovation methodology I
DTMF dual tone multi frequency signal simulation demonstration system