当前位置:网站首页>CVPR2022——A VERSATILE MULTI-VIEW FRAMEWORK
CVPR2022——A VERSATILE MULTI-VIEW FRAMEWORK
2022-08-11 06:15:00 【zhSunw】
A VERSATILE MULTI-VIEW FRAMEWORK FOR LIDAR-BASED 3D OBJECT DETECTION WITH GUIDANCE FROM PANOPTIC SEGMENTATION
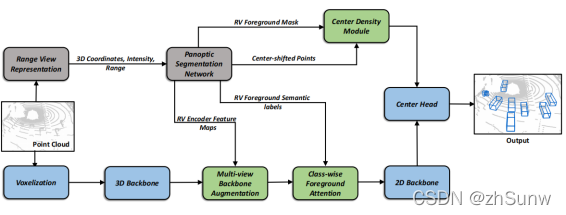
Grey represents the CPSeg module, blue represents the CenterPoint module
Contribution:
- Proposes a multi-task framework (panoramic segmentation + object detection), and panoramic segmentation improves object detection.
- The framework can be used for any BEV-based object detection method
- Extensive experiments and ablation experiments
Keyknowledge:
- Multi-View Backbone Augmentation
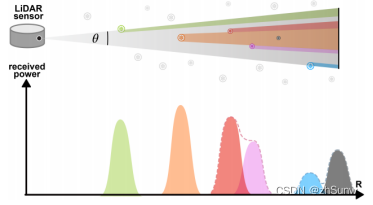
RV: Feature representation is dense, easy to detect small objects.But there are size changes (near big and far small) and occlusion.
BEV: There is no problem of near, far, small and occlusion, and it is easy to detect dense targets and determine boundaries.But sparsity is not good for detecting small objects.
Cascade RV Feature Fusion Module: Fusion Multi-Level Range View Features
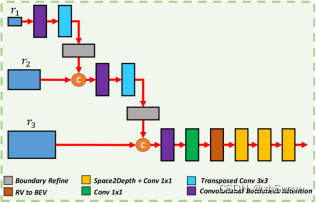
Three different resolution features provided by the panorama segmentationThe graph starts from r1 (minimum resolution), first through the Convolutional Block Attention Module (CBAM) module to weight the feature map layer by layer, and then through deconvolution upsampling to connect to a higher resolution feature map until the highest resolutionThe r3 feature map of .It is then projected to the BEV plane, and the resolution is adapted to the 2D BackBone detection head through Space2Depth + Conv 1x1 downsampling block compression.
Attention-based RV-BEV Feature Weighting Module: Weights the two RV-BEV feature maps to highlight important feature values.
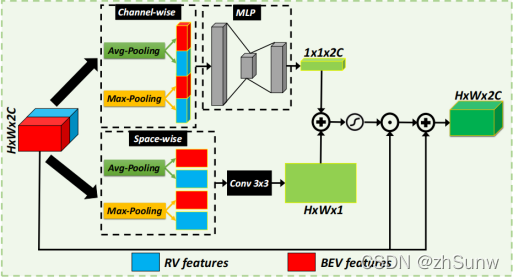
The modified CBAM module is used for both RV and BEVThe channel attention feature map and the spatial attention feature map are calculated separately for each feature map, and the two feature maps are broadcasted and added and then activated to generate the attention map.The input RV-BEV features are weighted with an attention map to highlight feature values that are helpful for the detection task.Finally, it is added to the input features to obtain an attention-weighted multi-view feature map.
Attention-Based Feature Weighting Map Visualization: The red and blue regions represent where the BEV and RV features are considered to have higher weights, respectively.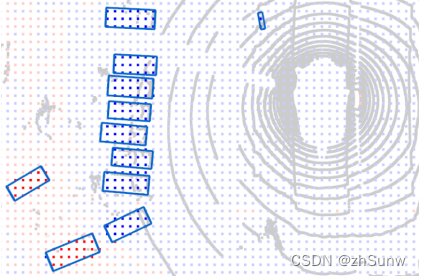
Attention-based RV-BEV weighting module as representativeRV features for nearby and smaller objects are assigned higher weights, while occluded and distant objects tend to favor BEV features.
Class-wise Foreground Attention Module: Embedding Foreground Semantic Information into Features
Because the paper lacks a module diagram and has not been open sourced 
According to the textThe description draws the module diagram according to his own understanding: 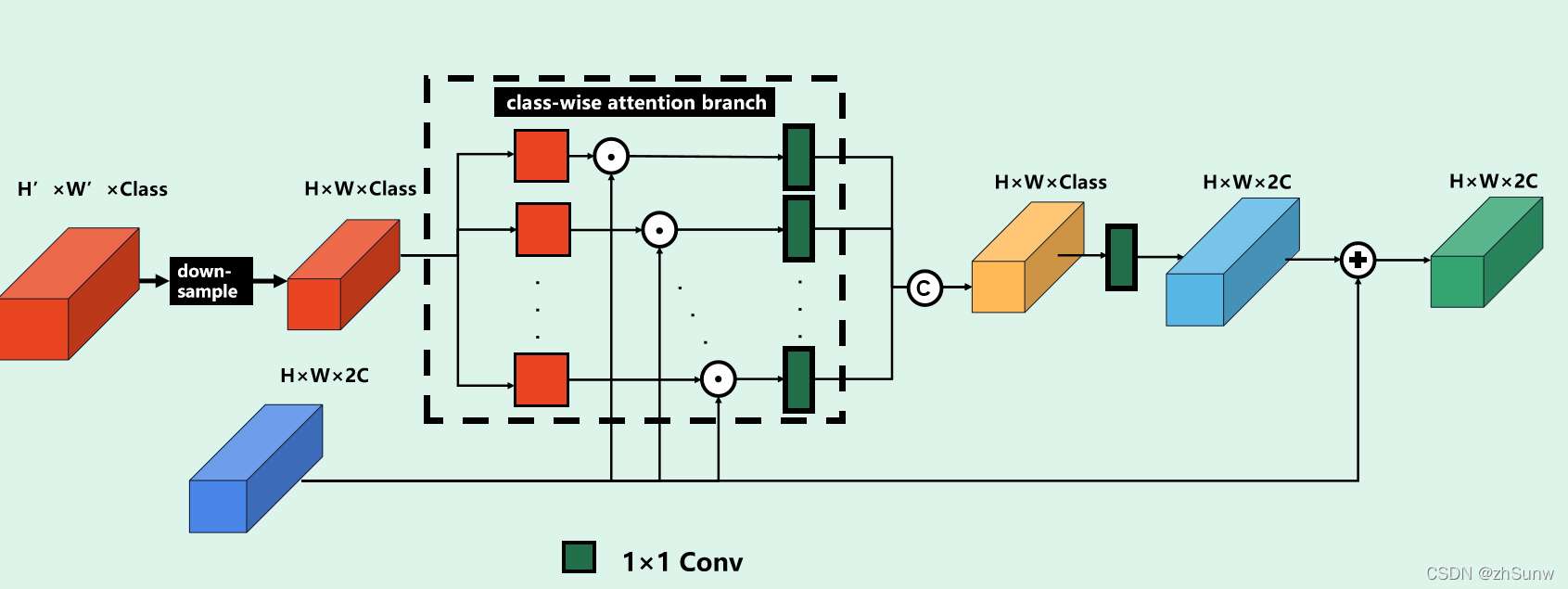
Provide the panorama segmentedThe per-foreground class probabilities of each point (disregarding background points) are maxpooling down-sampled to the same resolution as the RV-BEV weighted feature map.Then weight by class: each class weights the feature map by element multiplication by probability, and then 1×1 convolution compresses the channel dimension to obtain the Class-wise Foreground Attention Map, and finally connects the weighted maps of each class.Changing the shape of the feature map through 1×1 convolution is the same as the input RV-BEV feature map, and then adding the two to obtain the final weighted feature map.
Center Density Heatmap Module: Calculate Center Density
Draw the Center Density Heatmap through the 3D BBox center offset of each point estimated by CPSeg:
First use the foreground mask to pass the background points, and the remaining points are offset according to the offset prediction and projected on the BEV plane,Then create a Heatmap according to the Heatmap function: 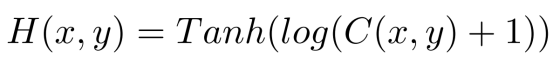
C(x,y) represents the number of projections to this point.
The more times a point is predicted to be the center point, the larger the value, the darker (green) the color: 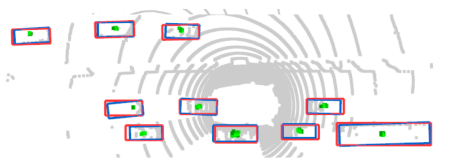
Experiments
Sota:
Ablation experiment: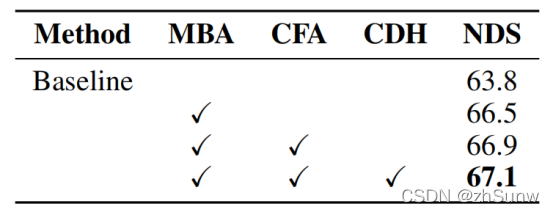
Effectiveness of multitasking framework: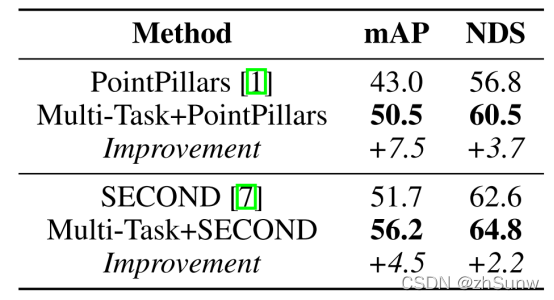
Effectiveness of multi-task (single-task pre-trained CPSeg):
边栏推荐
猜你喜欢
![《现代密码学》学习笔记——第三章 分组密码 [二] AES](/img/83/161111c5f085f2f3d6587e32e15805.png)


随机推荐
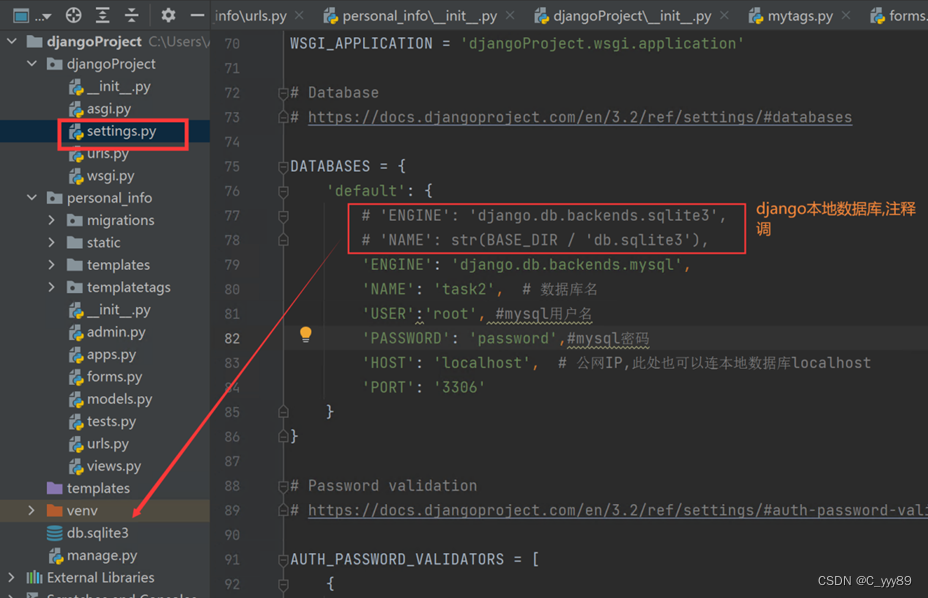
Nodered系列—使用node-red-node-mysql写入mysql详细步骤
华为手机软键盘挡住Toast
《现代密码学》学习笔记——第七章 密钥管理[一]
基于AI智能图像识别:4个不同的行业应用
恶劣天气 3D 目标检测数据集收集
Joint 3D Instance Segmentation and Object Detection for Autonomous Driving
【uniapp】跨端开发问题记录
基于uniapp开发的聊天界面
梅科尔工作室-深度学习第二讲 BP神经网络
关于修改挂载到宿主机上的mysql配置文件不生效这件事
GBase 8s分片技术介绍
GBase 8s性能简介
HUE部署
如何修改严格模式让MySQL5.7插入用户表的方式新建用户成功?delete和drop的不同
Docker安装Mysql及常用命令
Toolbar 和 DrawerLayout 滑动菜单
GBase 8a 并行技术
云计算学习笔记——第四章 存储虚拟化
经纬度距离
Androd 基本布局(其一)