当前位置:网站首页>CVPR2022——Not All Points Are Equal : IA-SSD
CVPR2022——Not All Points Are Equal : IA-SSD
2022-08-11 06:17:00 【zhSunw】
IA-SSD
Not All Points Are Equal:IA-SSD
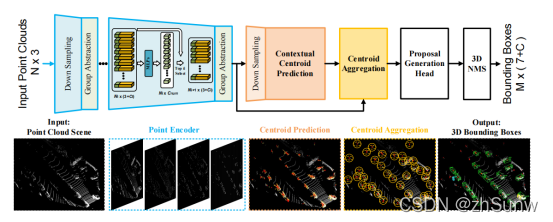
Write in front: with RandLa-Net recently readThe pointcut is similar to the downsampling method.
Motivation
The current Point-Based methods all use "task-agnostic" (unrelated to the detection itself) sampling methods: Random, D-FPS, Feat-FPS.For these sampling methods are ignored: "For the detection task, foreground points are more important than background points".
Contribution
- This paper proposes two "learnable, task-oriented, instance-aware" sampling methods (instance-aware learning methods related to detection tasks).
- An efficient model IA-SSD is proposed based on the sampling method.
- Extensive experiments were performed on KITTI, Waymo, ONCE datasets.
Keyknowledge
Instance-aware Downsampling Strategy
- Class-aware Sampling
The training branch learns point semantic information*, predicts the foreground point probability score of each point, and takes the top k as the sampling point and sends it to the next layer.
The loss function uses normal cross-entropy: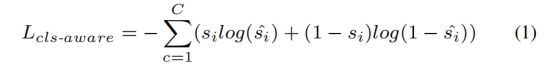
Difference from Feature-FPS: This paper wants as many foreground points as possible, while F-FPS wants points with as large a feature gap as possible. - Centroid-aware Sampling
Introduce the central mask mask based on Class-aware Sampling: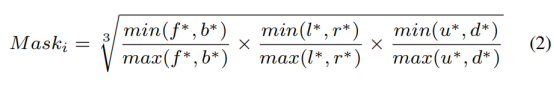
The mask has the same centrality as in 3DSSD: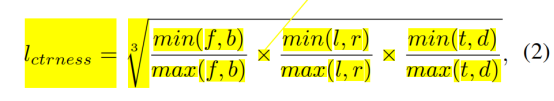
Use the center mask to weight the cross-entropy loss to improve the probability of being sampled close to the center point and preserve the center point as much as possible (considering that instance center estimation is the key to the final object detection):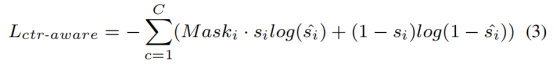
Contextual Instance Centroid Perception
- Contextual Centroid Prediction
Follows the VoteNet method to predict an offset from the center, and adds a regularization, so that the center prediction of each instance is aggregated, reducing the instability of the predicted center offset: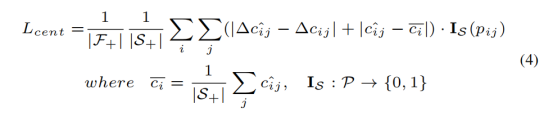
and VoteNet use only the points in the BBox to predict the center pointDifferently, this paper also utilizes the surrounding representative points: manually expanding the BBox, or scaling up the box to cover more relevant contextual information near the object. - Centroid-based Instance Aggregation
For each center point, use PointNet++ to learn the features of the instance: convert the adjacent points into a local regular coordinate system, and then aggregate the point features through shared mlp and symmetric functions. - Proposal Generation Head
Predicts BBox based on aggregated instance features, and then performs 3D-NMS post-processing.
Loss
Add multiple losses and jointly optimize to achieve end-to-end training.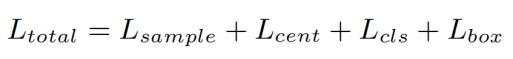
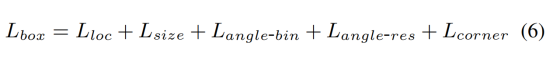
Experiment
Comparison of sampling methods on KITII validation set

In the case of low sampling points (256points) articleThe sampling ratio of the proposed two samples to the instances is obviously due to other sampling methods.At the same time, Feature-FPS takes into account the characteristics of each point, so the sampling ratio of instances is also higher than random and D-FPS.
Quantitative comparison of detection performance of different methods on the KITTI test set
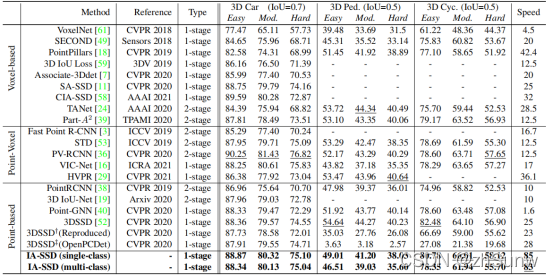
IA-SSD is on two instances of Car and CycThe effect is better, the accuracy is higher in the Point-based method, but lower than PV_RCNN, and the effect is poor on Ped instances.Simultaneous detection speed is higher than all other methods.
边栏推荐
- 解决Glide图片缓存问题,同一url换图片不起作用问题
- xss.haozi靶场通关
- NodeRed系列—创建mqtt broker(mqtt服务器),并使用mqttx进行消息发送验证
- 内核与用户空间通过字符设备通信
- 梅科尔工作室-PR第三次培训笔记(效果与转场及插件使用)
- XSS跨站脚本攻击详解以及复现gallerycms字符长度限制短域名绕过
- 基于uniapp开发的聊天界面
- GBase 8a技术特性-集群架构
- Maykel Studio - Django Web Application Framework + MySQL Database Second Training
- SCNet: Semantic Consistency Networks for 3D Object Detection
猜你喜欢



随机推荐
【sqlyog】【mysql】csv导入问题
安全帽佩戴识别系统介绍
Toolbar 和 DrawerLayout 滑动菜单
OSPF综合实验
RIP综合实验
微信小程序部分功能细节
Maykle Studio - HarmonyOS Application Development First Training
uniapp 在HBuilder X中配置微信小程序开发工具
梅科尔工作室-HarmonyOS应用开发的第二次培训
>>数据管理:读书笔记|第一章 数据管理
CVPR2022——A VERSATILE MULTI-VIEW FRAMEWORK
【docker-compose】mysql安装
梅科尔工作室-Pr第一次培训笔记(安装及项目创建)
目标检测前言
Redis主从复制的搭建
>>数据管理:DAMA简介
【uniapp】跨端开发问题记录
windows下的redis安装及密码修改
AI智能图像识别的工作原理及行业应用
梅科尔工作室-HarmonyOS应用开发第四次培训