当前位置:网站首页>Btree index and Hash index
Btree index and Hash index
2022-08-10 23:12:00 【Small wood with】
Hash Index
The location where the data is stored is located by calculating the Hash value of the data, so when querying the data, you can directly locate the location of the data, without the need to search for the data again and again through the binary tree like the B-tree.Very efficient.But why are Hash indexes rarely used?
Disadvantages:
- Only specified data can be queried, and range query cannot be performed. Searches such as < >= in cannot be realized
- The data cannot be sorted because the size of the hash value of the data does not represent the size of the data itself
- Cannot avoid full table scan through index, because the range cannot be delineated, all can only scan all data
BTree Index
It is a very good index structure. It is realized through the structure of B+ tree. It builds an index tree by extracting index fields, so as to locate the cache page where the data is located when querying, so as to realize the range filtering operation of the data.
And the index can also be used when there is no wildcard "zhang%" on the left side of the like statement.It is very suitable for operations such as sorting and range querying of large amounts of data.
边栏推荐
猜你喜欢

阿里云贾朝辉:云XR平台支持彼真科技呈现国风科幻虚拟演唱会

金山云CEO王育林离职:正值冲刺港股之际 雷军曾送金砖

PyQt5 窗口自适应大小
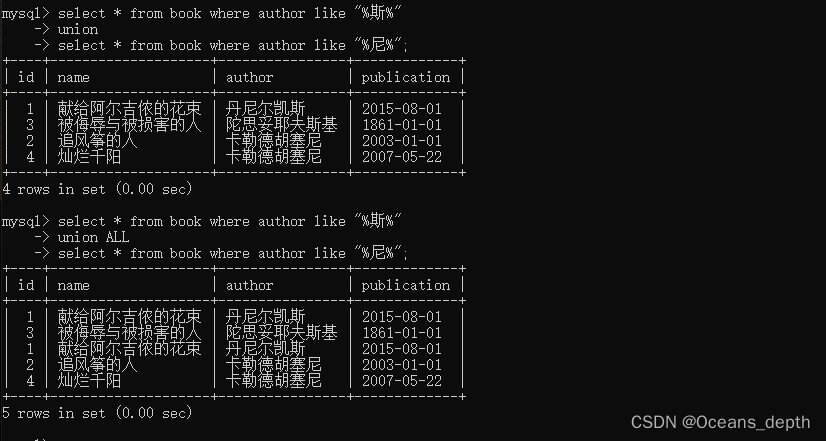
MySQL学习笔记(1)——基础操作
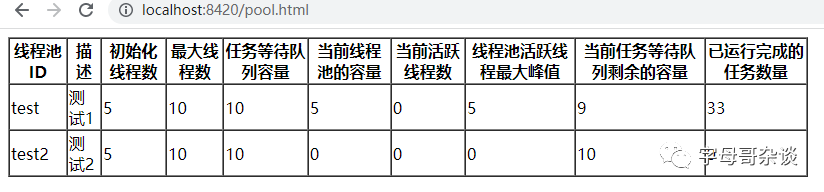
web项目访问引用jar内部的静态资源
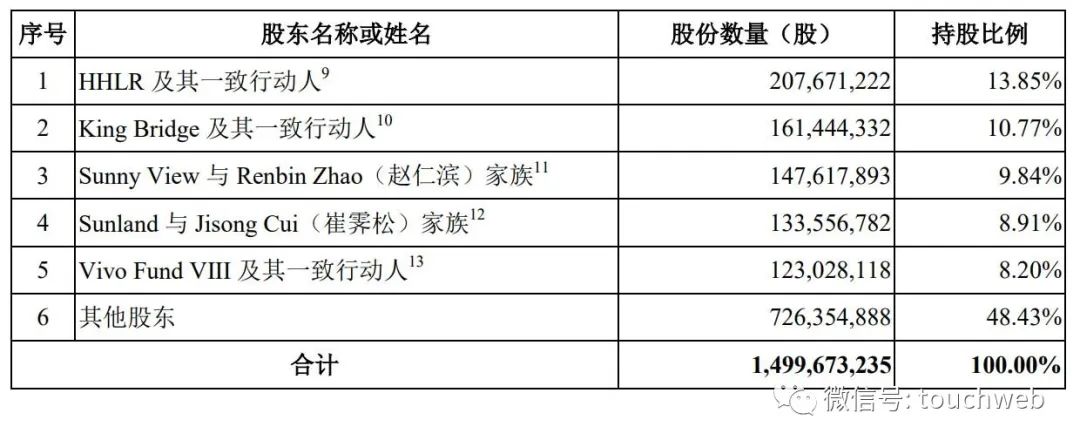
诺诚健华通过注册:施一公家族身价15亿 高瓴浮亏5亿港元

【640. Solving Equations】
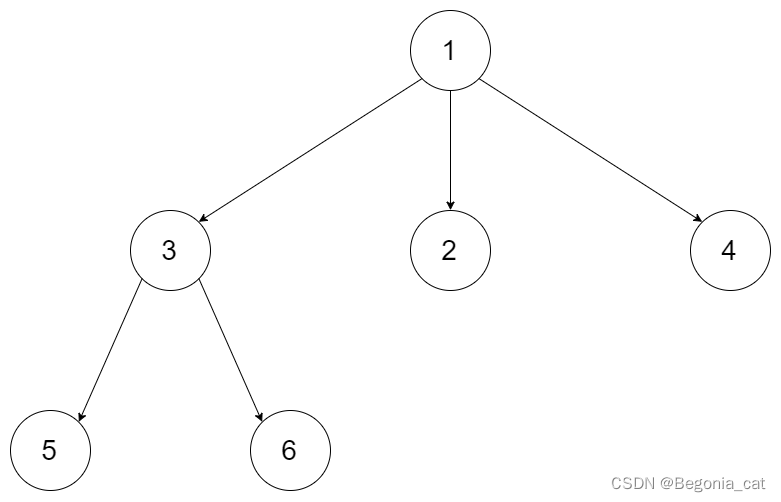
二叉树 | 递归遍历 | leecode刷题笔记

Leave a message with a prize | OpenBMB x Tsinghua University NLP: The update of the large model open class is complete!
DC-7靶场下载及渗透实战详细过程(DC靶场系列)
随机推荐
二叉树 | 对称二叉树、相同的树、子树相同 | leecode刷题笔记
3598. Binary tree traversal (Huazhong University of Science and Technology exam questions)
带着昇腾去旅行:一日看尽金陵城里的AI胜景
实例054:位取反、位移动
MySQL:MySQL的集群——主从复制的原理和配置
Merge k sorted linked lists
Research on multi-element N-k fault model of power system based on AC power flow (implemented by Matlab code) [Power System Fault]
VulnHub之DC靶场下载与DC靶场全系列渗透实战详细过程
Splunk中解决数据质量问题常见日期格式化
pytorch手撕CNN
STL-deque
如何成为一名正义黑客?你应该学习什么?
JS use regular expressions in g model and non g difference
CFdiv2-Beautiful Mirrors-(期望)
阿里云贾朝辉:云XR平台支持彼真科技呈现国风科幻虚拟演唱会
2022年8月10日:使用 ASP.NET Core 为初学者构建 Web 应用程序--使用 ASP.NET Core 创建 Web UI(没看懂需要再看一遍)
leetcode:355. 设计推特
web项目访问引用jar内部的静态资源
阿里云架构师金云龙:基于云XR平台的视觉计算应用部署
JS中使用正则表达式g模式和非g模式的区别