当前位置:网站首页>A general U-shaped transformer for image restoration
A general U-shaped transformer for image restoration
2022-04-23 06:00:00 【umbrellalalalala】
2021 year 6 month 6 Submitted to arxiv Articles on .ICCV2021 Of Eformer Namely Uformer Based on improvement , It seems worth reading , Simply record .
Know that the account with the same name is released synchronously .
Catalog
One 、 Architecture design
The structure is as shown in the figure :

Compared to the ordinary UNet, The difference is that LeWin Transformer, such Transformer It is also the innovation of this work .
So-called LeWin Transformer, Namely local-enhanced window Transformer, It includes W-MSA and LeFF:
- W-MSA:non-overlapping window-based self-attention, The purpose is to reduce the computational overhead ( Tradition transformer It is calculated globally self-attention, And it's not );
- LeFF: Tradition transformer Feedforward neural network is used in , Can't make good use of local context,LeFF The adoption of can capture local information.
️ Two innovations :
- Put forward LeWin Transformer, introduce UNet
- Three jump connections
Two 、 Main module details
2.1,W-MSA
This is the biggest innovation of this work . ( Reminded ,swin Transformer There are )

First will C×H×W Of X It is divided into N individual C×M×M individual patch, Every patch Deemed to have M×M individual C dimension vector(N = H × W / M²), this C individual vector enter W-MSA in . According to the above formula , A simple understanding is to make X Divided into non overlapping N slice , And then... For each piece self-attention The calculation of .

Author expresses , Although it is carried out on one piece self-attention The calculation of , But in UNet Of encode Stage , Due to the existence of down sampling , So calculate self attention on this piece , Corresponding to the calculation of self attention on the larger receptive field before down sampling .
Adopted relative position encoding, So the calculation formula can be expressed as :

A reference to this location code [48,41] Namely :
[48] Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position repre-
sentations. arXiv preprint arXiv:1803.02155, 2018.
[41] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining
Guo. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint
arXiv:2103.14030, 2021.
2.2,LeFF
LeFF yes Incorporating Convolution Designs into Visual Transformers Invented , Among them Convolution-enhanced image Transformer (CeiT) Including this design .
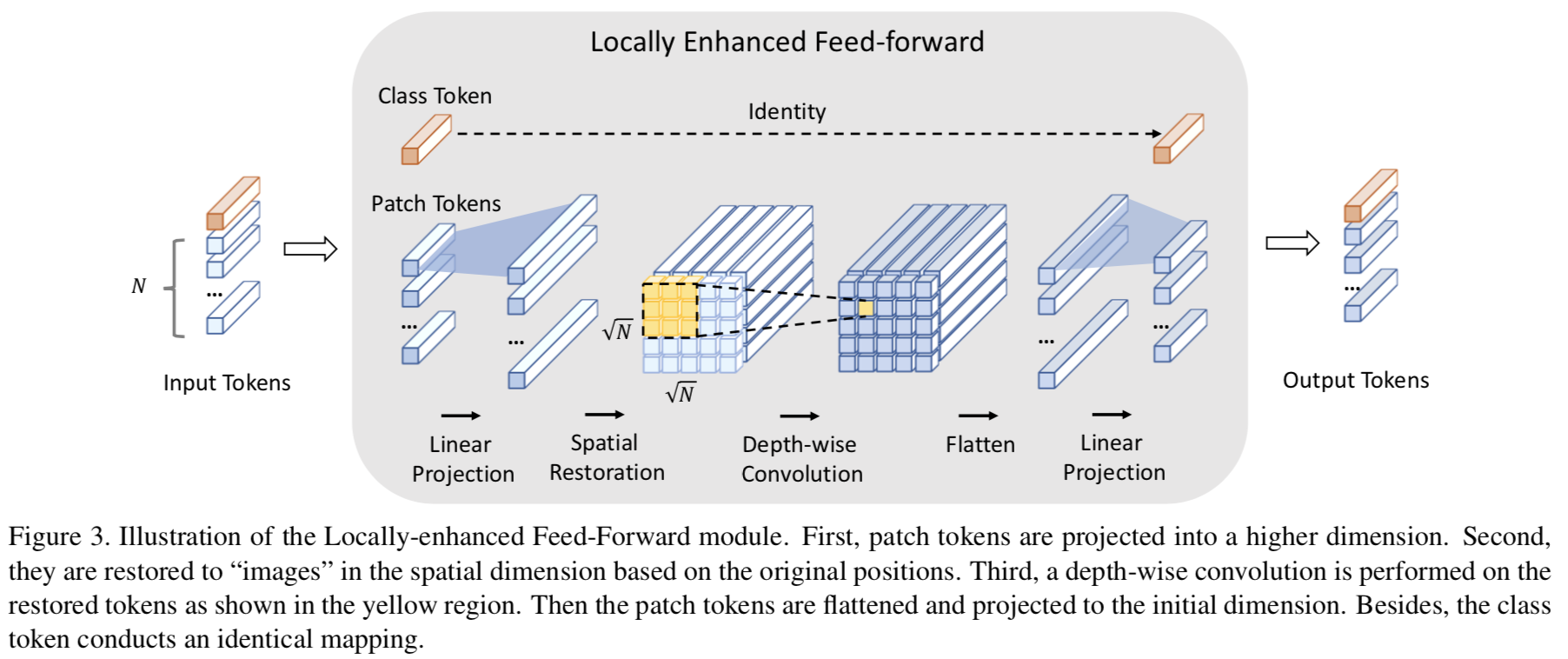
The essence is to self-attention Calculate the output of the module N individual token(vector), Rearrange to N × N \sqrt{N} \times \sqrt{N} N×N Of “image”, Then proceed depth-wise Convolution operation of . After watching CeiT The diagram given by the author , Look again Uformer The diagram given by the author , It's not difficult to understand the meaning :

Each linear layer / After the convolution layer , Using all of these GELU Activation function .
(depth-wise A search on the Internet has , The function is to reduce parameters , Speed up computing )
2.3, Three jump connections
UNet The architecture has jump connections , In this work is to encoder Part of the Transformer The output of is passed to decoder part , But there are many ways to use these jump connections to convey information , The author explores three :
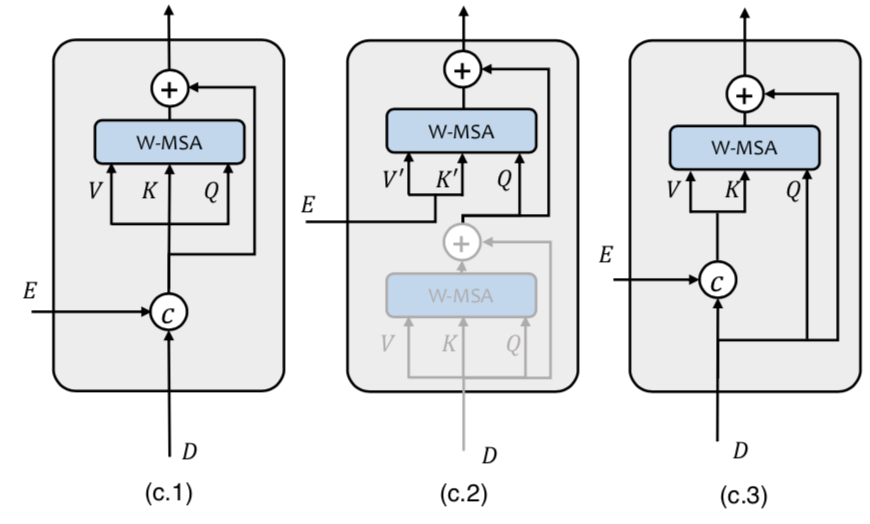
- The first is direct concat To come over ;
- The second is : every last decode stage There is one upsampling and two Transformer block, It means the first to use self-attention, The second use cross attention;
- The third is concat Information as key and value Of cross attention.

The author believes that the three are similar , But the first one is a little better , So the first one is used as Uformer Default Settings .
Uformer The details of architecture design are here , I won't take a closer look at other contents .
3、 ... and 、 Calculate the cost
since LeWin Transformer Medium W-MSA Focus on reducing computing overhead , So naturally, let's look at the complexity of the algorithm :
Given feature map X, Dimension for C×H×W, If it's traditional self-attention, So the complexity is O ( H 2 W 2 C ) O(H^2 W^2 C) O(H2W2C), Is divided into M×M Of patch Do it again self-attention, It is O ( H W M 2 M 4 C ) = O ( M 2 H W C ) O(\frac{HW}{M^2}M^4 C)=O(M^2HWC) O(M2HWM4C)=O(M2HWC), Reduced complexity .
Four 、 experimental result
The author did denoising 、 Go to the rain 、 Deblurring experiment .





版权声明
本文为[umbrellalalalala]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230543451118.html
边栏推荐
- 框架解析2.源码-登录认证
- Pytorch notes - observe dataloader & build lenet with torch to process cifar-10 complete code
- 图解numpy数组矩阵
- Fundamentals of SQL: first knowledge of database and SQL - installation and basic introduction - Alibaba cloud Tianchi
- Pytorch learning record (V): back propagation + gradient based optimizer (SGD, adagrad, rmsporp, Adam)
- Pyqt5 learning (I): Layout Management + signal and slot association + menu bar and toolbar + packaging resource package
- PyQy5学习(四):QAbstractButton+QRadioButton+QCheckBox
- RedHat6之smb服务访问速度慢解决办法记录
- Graphic numpy array matrix
- 基于thymeleaf实现数据库图片展示到浏览器表格
猜你喜欢

In depth source code analysis servlet first program

Graphic numpy array matrix

On traversal of binary tree

Ptorch learning record (XIII): recurrent neural network

线程的底部实现原理—静态代理模式

Contrôle automatique (version Han min)

深入理解去噪论文——FFDNet和CBDNet中noise level与噪声方差之间的关系探索

LDCT图像重建论文——Eformer: Edge Enhancement based Transformer for Medical Image Denoising

你不能访问此共享文件夹,因为你组织的安全策略阻止未经身份验证的来宾访问

Understand the current commonly used encryption technology system (symmetric, asymmetric, information abstract, digital signature, digital certificate, public key system)
随机推荐
EditorConfig
rsync实现文件服务器备份
Linear algebra Chapter 2 - matrices and their operations
Gaussian processes of sklearn
Fundamentals of SQL: first knowledge of database and SQL - installation and basic introduction - Alibaba cloud Tianchi
PyTorch笔记——观察DataLoader&用torch构建LeNet处理CIFAR-10完整代码
JVM family (4) -- memory overflow (OOM)
Pytorch notes - observe dataloader & build lenet with torch to process cifar-10 complete code
delete和truncate
Pytorch学习记录(十):数据预处理+Batch Normalization批处理(BN)
实操—Nacos安装与配置
PreparedStatement防止SQL注入
Remedy after postfix becomes a spam transit station
Opensips (1) -- detailed process of installing opensips
去噪论文阅读——[RIDNet, ICCV19]Real Image Denoising with Feature Attention
JSP syntax and JSTL tag
编程记录——图片旋转函数scipy.ndimage.rotate()的简单使用和效果观察
protected( 被 protected 修饰的成员对于本包和其子类可见)
Multithreading and high concurrency (3) -- synchronized principle
PyTorch笔记——通过搭建ResNet熟悉网络搭建方式(完整代码)