当前位置:网站首页>Spark 算子之coalesce与repartition
Spark 算子之coalesce与repartition
2022-04-23 15:45:00 【逆风飞翔的小叔】
前言
我们知道,Spark在执行任务的时候,可以并行执行,可以将数据分散到不同的分区进行处理,但是在实际使用过程中,比如在某些场景下,一开始数据量大,给的分区是4个,但是到了数据处理快结束的时候,希望分区缩减,减少资源开销,这就涉及到分区的动态调整,就要使用到Spark提供的coalesce与repartition这两个算子了;
coalesce
函数签名
def coalesce( numPartitions: Int , shuffle: Boolean = false ,partitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[T] = null): RDD[T]
函数说明
根据数据量 缩减分区 ,用于大数据集过滤后,提高小数据集的执行效率,当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少 分区的个数,减小任务调度成本;
案例演示
创建一个集合,将数据保存到3个分区文件中
import org.apache.spark.{SparkConf, SparkContext}
object Coalesce_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
//一开始设定3个分区
val rdd = sc.makeRDD(List(1,2,3,4,5,6),3)
rdd.saveAsTextFile("E:\\output")
sc.stop()
}
}运行上面的代码,可以看到在本地的目录下,生成了3个文件
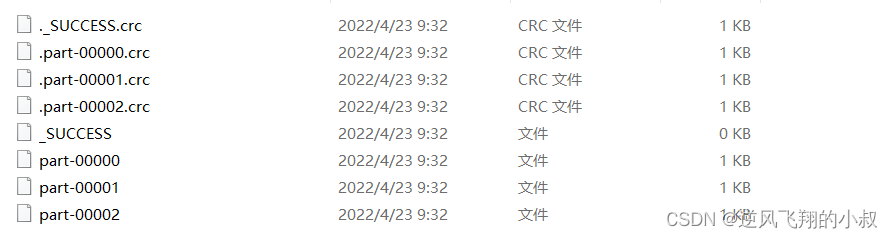
这时候我们希望缩减分区,缩减分区后,生成的文件个数也会相应减少
import org.apache.spark.{SparkConf, SparkContext}
object Coalesce_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
//一开始设定3个分区
val rdd = sc.makeRDD(List(1,2,3,4,5,6),3)
rdd.saveAsTextFile("E:\\output")
rdd.coalesce(2,true)
sc.stop()
}
}再次运行上面的程序,可以看到这次只生成了2个文件
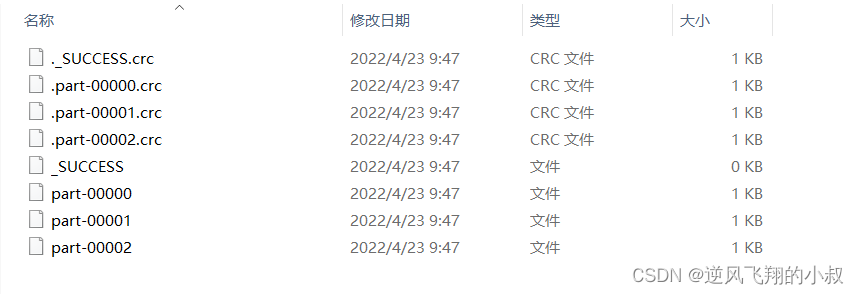
通过这种方式就达到了缩减分区的目的;
repartition
和coalesce相反,repartition 可以达到扩大分区的目的
函数签名
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
函数说明
该操作内部其实执行的是 coalesce 操作,参数 shuffle 的默认值为 true 。无论是将分区数多的 RDD 转换为分区数少的 RDD ,还是将分区数少的 RDD 转换为分区数多的 RDD , repartition 操作都可以完成,因为无论如何都会经 shuffle 过程;
案例演示
创建一个集合,使用2个分区保存文件到本地
import org.apache.spark.{SparkConf, SparkContext}
object Repartition_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
//一开始设定3个分区
val rdd = sc.makeRDD(List(1,2,3,4,5,6),2)
rdd.saveAsTextFile("E:\\output")
sc.stop()
}
}运行上面的代码,可以看到在本地生成了2个文件
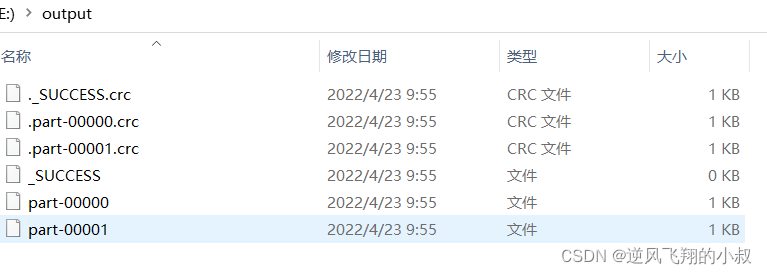
这时候,我们希望扩大分区,提升任务的并行处理能力,使用 repartition
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Repartition_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1,2,3,4,5,6), 2)
// coalesce算子可以扩大分区的,但是如果不进行shuffle操作,是没有意义,不起作用。
// 所以如果想要实现扩大分区的效果,需要使用shuffle操作
// spark提供了一个简化的操作
// 缩减分区:coalesce,如果想要数据均衡,可以采用shuffle
// 扩大分区:repartition, 底层代码调用的就是coalesce,而且肯定采用shuffle
//val newRDD: RDD[Int] = rdd.coalesce(3, true)
val newRDD: RDD[Int] = rdd.repartition(3)
newRDD.saveAsTextFile("E:\\output")
sc.stop()
}
}再次运行上面的代码,这时候可以看到在本来文件目录下生成了3个文件
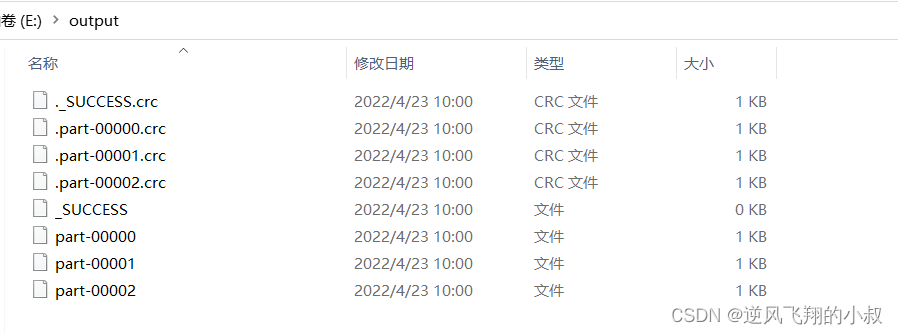
版权声明
本文为[逆风飞翔的小叔]所创,转载请带上原文链接,感谢
https://blog.csdn.net/congge_study/article/details/124359288
边栏推荐
猜你喜欢
MySQL Cluster Mode and application scenario

建设星际计算网络的愿景
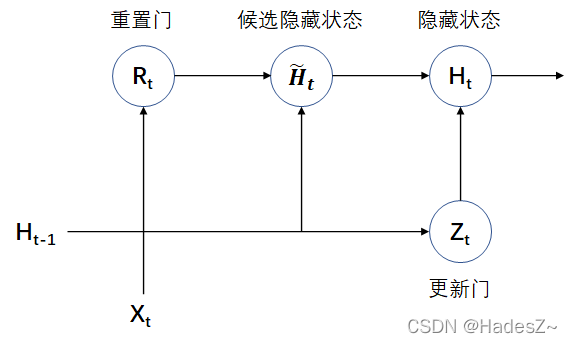
时序模型:门控循环单元网络(GRU)
IronPDF for . NET 2022.4.5455
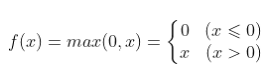
Advantages, disadvantages and selection of activation function
Today's sleep quality record 76 points

Do we media make money now? After reading this article, you will understand
C language --- string + memory function
Recommended search common evaluation indicators
MySQL集群模式與應用場景
随机推荐
WPS brand was upgraded to focus on China. The other two domestic software were banned from going abroad with a low profile
PHP classes and objects
Explanation of redis database (IV) master-slave replication, sentinel and cluster
One brush 314 sword finger offer 09 Implement queue (E) with two stacks
Demonstration meeting on startup and implementation scheme of swarm intelligence autonomous operation smart farm project
IronPDF for . NET 2022.4.5455
What if the server is poisoned? How does the server prevent virus intrusion?
What is CNAs certification? What are the software evaluation centers recognized by CNAs?
c语言---指针进阶
通过 PDO ODBC 将 PHP 连接到 MySQL
布隆过滤器在亿级流量电商系统的应用
字符串排序
Codejock Suite Pro v20.3.0
Deeply learn the skills of parameter adjustment
The El tree implementation only displays a certain level of check boxes and selects radio
String sorting
MySQL optimistic lock to solve concurrency conflict
Modèle de Cluster MySQL et scénario d'application
单体架构系统重新架构
Cookie&Session