当前位置:网站首页>Coalesce and repartition of spark operators
Coalesce and repartition of spark operators
2022-04-23 15:48:00 【Uncle flying against the wind】
Preface
We know ,Spark In carrying out the task , It can be executed in parallel , Data can be distributed to different partitions for processing , But in actual use , For example, in some scenarios , At first, there was a large amount of data , The partition given is 4 individual , But at the end of data processing , Want partition reduction , Reduce resource overhead , This involves the dynamic adjustment of partitions , It's about to use Spark Provided coalesce And repartition These two operators ;
coalesce
Function signature
def coalesce( numPartitions: Int , shuffle: Boolean = false ,partitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[T] = null): RDD[T]
Function description
According to the amount of data Reduce partitions , Used after big data set filtering , Improve the execution efficiency of small data sets , When spark In the program , When there are too many small tasks , Can pass coalesce Method , Shrink merge partition , Reduce Number of partitions , Reduce the cost of task scheduling ;
Case presentation
Create a collection , Save data to 3 In a partition file
import org.apache.spark.{SparkConf, SparkContext}
object Coalesce_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// In the beginning, set 3 Zones
val rdd = sc.makeRDD(List(1,2,3,4,5,6),3)
rdd.saveAsTextFile("E:\\output")
sc.stop()
}
}Run the above code , You can see in the local directory , Generated 3 File
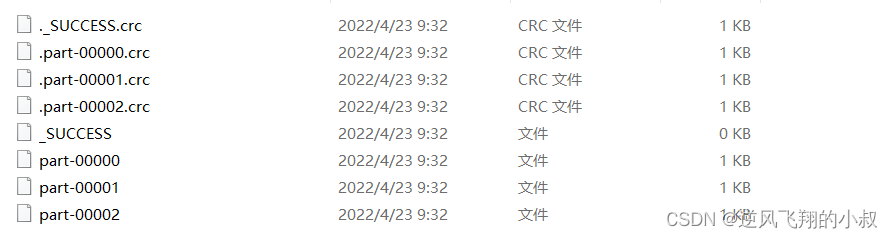
At this time, we want to reduce the partition , After reducing the partition , The number of files generated will be reduced accordingly
import org.apache.spark.{SparkConf, SparkContext}
object Coalesce_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// In the beginning, set 3 Zones
val rdd = sc.makeRDD(List(1,2,3,4,5,6),3)
rdd.saveAsTextFile("E:\\output")
rdd.coalesce(2,true)
sc.stop()
}
}Run the above program again , You can see that only 2 File
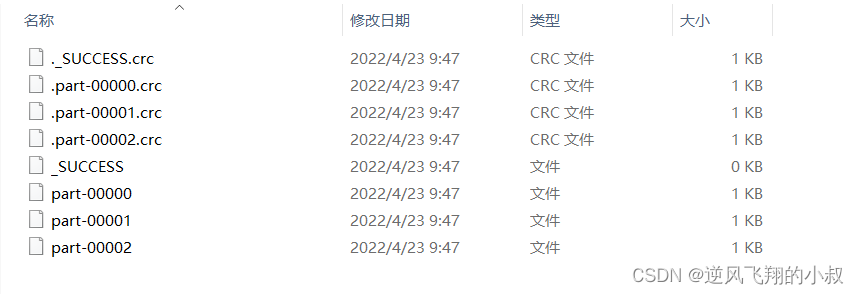
In this way, the purpose of reducing partitions is achieved ;
repartition
and coalesce contrary ,repartition It can achieve the purpose of expanding partitions
Function signature
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
Function description
This operation actually performs coalesce operation , Parameters shuffle The default value is true . Regardless of the number of partitions RDD Convert to less partitions RDD , Or the one with fewer partitions RDD Convert to a with a large number of partitions RDD , repartition All operations can be completed , Because it will go through shuffle The process ;
Case presentation
Create a collection , Use 2 Save files to local partition
import org.apache.spark.{SparkConf, SparkContext}
object Repartition_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// In the beginning, set 3 Zones
val rdd = sc.makeRDD(List(1,2,3,4,5,6),2)
rdd.saveAsTextFile("E:\\output")
sc.stop()
}
}Run the above code , You can see that it is generated locally 2 File
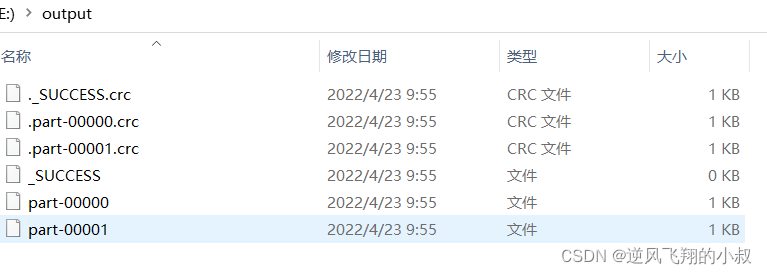
Now , We hope to expand the zoning , Improve the parallel processing ability of tasks , Use repartition
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Repartition_Test {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1,2,3,4,5,6), 2)
// coalesce The operator can expand the partition , But if not shuffle operation , It doesn't make sense , It doesn't work .
// So if you want to achieve the effect of expanding partitions , Need to use shuffle operation
// spark Provides a simplified operation
// Reduce partitions :coalesce, If you want data balance , May adopt shuffle
// Expansion of zoning :repartition, What the underlying code calls is coalesce, And definitely use shuffle
//val newRDD: RDD[Int] = rdd.coalesce(3, true)
val newRDD: RDD[Int] = rdd.repartition(3)
newRDD.saveAsTextFile("E:\\output")
sc.stop()
}
}Run the above code again , At this time, you can see that... Is generated in the original file directory 3 File
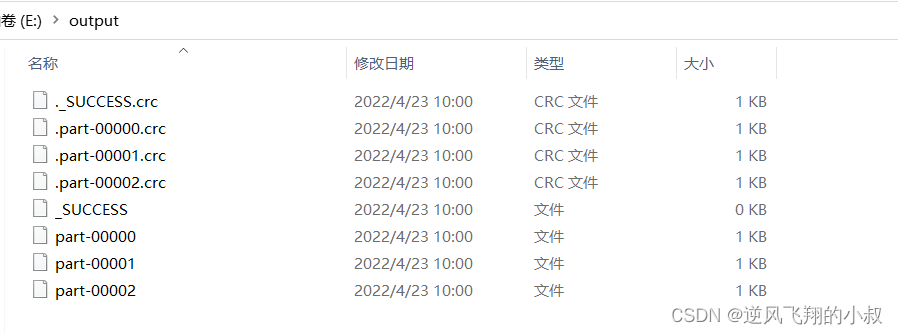
版权声明
本文为[Uncle flying against the wind]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231544587369.html
边栏推荐
- [split of recursive number] n points K, split of limited range
- 幂等性的处理
- MySQL optimistic lock to solve concurrency conflict
- C#,贝尔数(Bell Number)的计算方法与源程序
- Fastjon2 here he is, the performance is significantly improved, and he can fight for another ten years
- Upgrade MySQL 5.1 to 5.611
- Date date calculation in shell script
- The length of the last word of the string
- [section 5 if and for]
- 北京某信护网蓝队面试题目
猜你喜欢
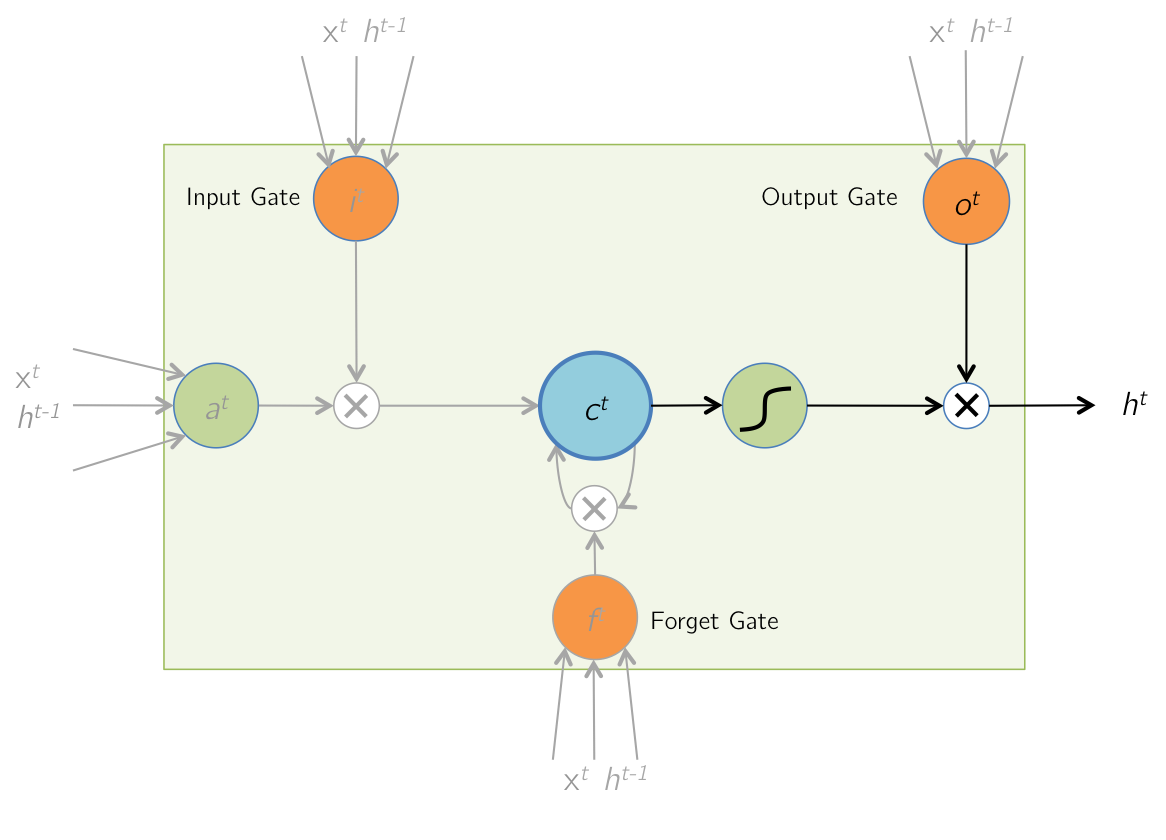
Temporal model: long-term and short-term memory network (LSTM)
糖尿病眼底病变综述概要记录

建设星际计算网络的愿景
【AI周报】英伟达用AI设计芯片;不完美的Transformer要克服自注意力的理论缺陷
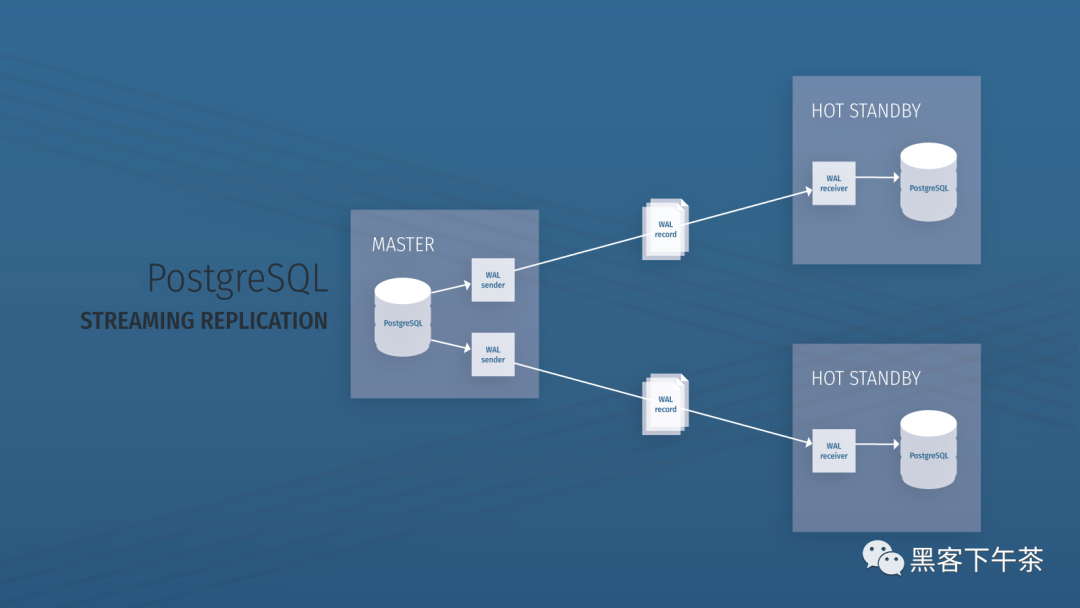
使用 Bitnami PostgreSQL Docker 镜像快速设置流复制集群

How can poor areas without networks have money to build networks?
IronPDF for . NET 2022.4.5455
For examination
Pgpool II 4.3 Chinese Manual - introductory tutorial

腾讯Offer已拿,这99道算法高频面试题别漏了,80%都败在算法上
随机推荐
时序模型:门控循环单元网络(GRU)
gps北斗高精度卫星时间同步系统应用案例
PHP operators
Leetcode-396 rotation function
js正則判斷域名或者IP的端口路徑是否正確
vim指定行注释和解注释
Go concurrency and channel
怎么看基金是不是reits,通过银行购买基金安全吗
IronPDF for . NET 2022.4.5455
字符串排序
为啥禁用外键约束
Import address table analysis (calculated according to the library file name: number of imported functions, function serial number and function name)
shell脚本中的DATE日期计算
New developments: new trends in cooperation between smartmesh and meshbox
Redis master-slave replication process
MySQL optimistic lock to solve concurrency conflict
How do you think the fund is REITs? Is it safe to buy the fund through the bank
C language --- advanced pointer
IronPDF for .NET 2022.4.5455
Implement default page