当前位置:网站首页>5-minute NLP: text to text transfer transformer (T5) unified text to text task model
5-minute NLP: text to text transfer transformer (T5) unified text to text task model
2022-04-23 16:35:00 【deephub】
This article will explain the following terms :T5,C4,Unified Text-to-Text Tasks
Transfer learning in NLP The effectiveness in comes from the model of pre training rich unmarked text data with self-monitoring tasks , For example, language modeling or filling in missing words . After pre training , You can fine tune the model on smaller labeled datasets , Generally better performance than training with tagged data alone . Transfer learning is such as GPT,Bert,XLNet,Roberta,Albert and Reformer As proved by the model .
Text-To-Text Transfer Transformer (T5)
The paper “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”(2019 Published in ) Put forward a large-scale empirical survey , It shows which transfer learning technology is the most effective , And apply these insights to create new ones called Text-To-Text Transfer Transformer (T5) Model .
An important part of migration learning is unlabeled data sets for pre training , This should not only be of high quality and diversity , And there should be a lot of . Previous pre training data sets did not meet all three criteria , because :
- Wikipedia High quality of text , But the style is uniform , The purpose suitable for us is relatively small
- come from Common Crawl Web The captured text is huge , Highly diverse , But the quality is relatively low .
So a new data set is developed in this paper : Colossal Clean Crawled Corpus (C4), This is a Common Crawl Of “ clean ” edition , Two orders of magnitude larger than Wikipedia .
stay C4 Pre trained T5 Models can be used in many NLP Get the most advanced results on the benchmark , And flexible enough , Several downstream tasks can be fine tuned .
Unify text to text format
Use T5, all NLP Tasks can be converted into a unified text to text format , The input and output of the task is always a text string .
The framework provides consistent training objectives , For pre training and fine tuning . Whatever the task , The models all have maximum likelihood targets . If you want to specify what kind of tasks the model should , You need to identify the target of the task before sending it to the model . Added to the original input sequence as a specific text prefix .
This framework allows for any NLP Use the same model on the task 、 Loss functions and hyperparameters , For example, machine translation 、 Document summary 、 Q & A and classification tasks .

Compare different models and training strategies
T5 The paper provides a variety of model architectures , Pre training objectives , Data sets , Comparison of training strategy and scale level . The baseline model for comparison is the standard encoder decoder Transformer.
- Model architecture : Although some about NLP The work of transfer learning has been considered Transformer Architectural variants of , But the original encoder - The decoder form works perfectly in experiments with text to text frames .
- Pre training objectives : Most denoising target training models will reconstruct randomly damaged text , stay T5 Similar operations are also performed in the settings of . therefore , It is suggested to use unsupervised pre training to increase computational efficiency , For example, the deprivation goal of filling the gap .
- Unlabeled dataset : Training of in domain data may be beneficial , However, pre training of small data sets may lead to harmful over fitting , Especially when the data set is small enough , Repeat several times during pre training . This has prompted people to use things like C4 Such a large and diverse data set to complete the task of general language understanding .
- Training strategy : Fine tune after training tasks , It can produce a good performance improvement for unsupervised pre training .
- Scale horizontal scaling : Various strategies using additional computing are compared , Include more data , Larger models , And use the integration of the model . Each method can improve the performance , But train a smaller model with more data , It's often better than training a larger model with fewer steps .
It turns out that , The text method is successfully applied to the generation task ( for example , Abstract abstract ), Classification task ( For example, natural language inference ), Even the return mission , It has considerable performance for task specific architecture and state .
The final T5 Model
Combined with experimental insights , The author uses different dimensions ( As many as 110 One hundred million parameters ) Training models , And achieve the most advanced results in many benchmarks . These models are in C4 Pre trained on the dataset , Then before fine tuning individual tasks , Pre training on multi task mix .
The biggest model is GLUE, SuperGLUE, SQuAD, and CNN/Daily Mail When the test reaches the most advanced results .
summary
In this paper , It introduces Text-To-Text Transfer Transformer (T5) Models and Colossal Clean Crawled Corpus (C4) Data sets . At the same time, examples of different tasks are introduced , This is called the unified text to text task , And see the qualitative experimental results of performance with different model architectures and training strategies .
If you're interested in this , You can try the following work by yourself :
- understand T5 Subsequent improvements to the model , Such as T5v1.1( With some architectural adjustments T5 Improved version ),MT5( Multilingual T5 Model ) and BYT5( Pre trained on byte sequences T5 Model, not token Sequence )
- You can see Hugging Face Of T5 Implement and fine tune
https://www.overfit.cn/post/a0e9aaeaabf04087a278aea6f06d14d6
author :Fabio Chiusano
版权声明
本文为[deephub]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231624506733.html
边栏推荐
- On the security of key passing and digital signature
- Oracle data pump usage
- Flask如何在内存中缓存数据?
- The most detailed knapsack problem!!!
- 第十天 异常机制
- 第九天 static 抽象类 接口
- 299. 猜数字游戏
- PHP 零基础入门笔记(13):数组相关函数
- Hyperbdr cloud disaster recovery v3 Version 2.1 release supports more cloud platforms and adds monitoring and alarm functions
- Jour (9) de ramassage de MATLAB
猜你喜欢
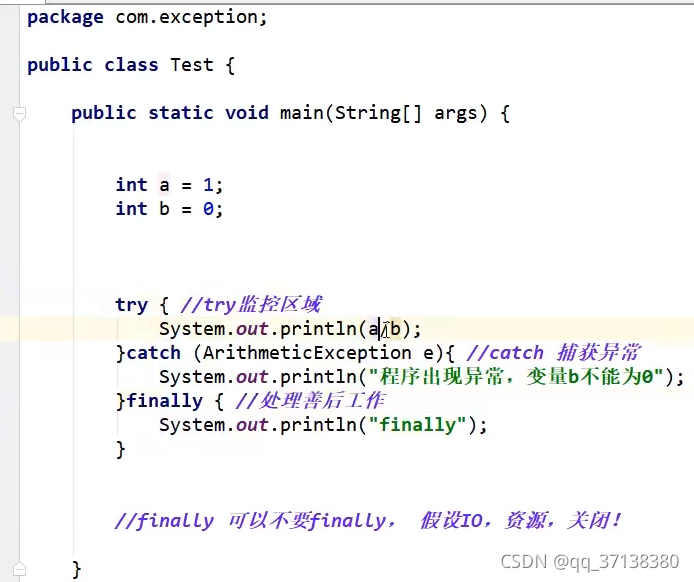
Day 10 abnormal mechanism
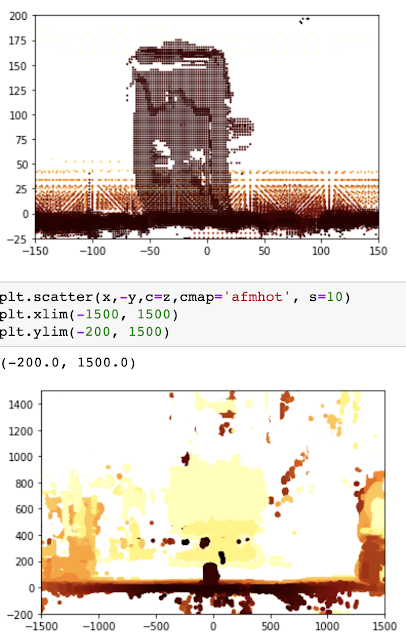
OAK-D树莓派点云项目【附详细代码】

Sail soft segmentation solution: take only one character (required field) of a string
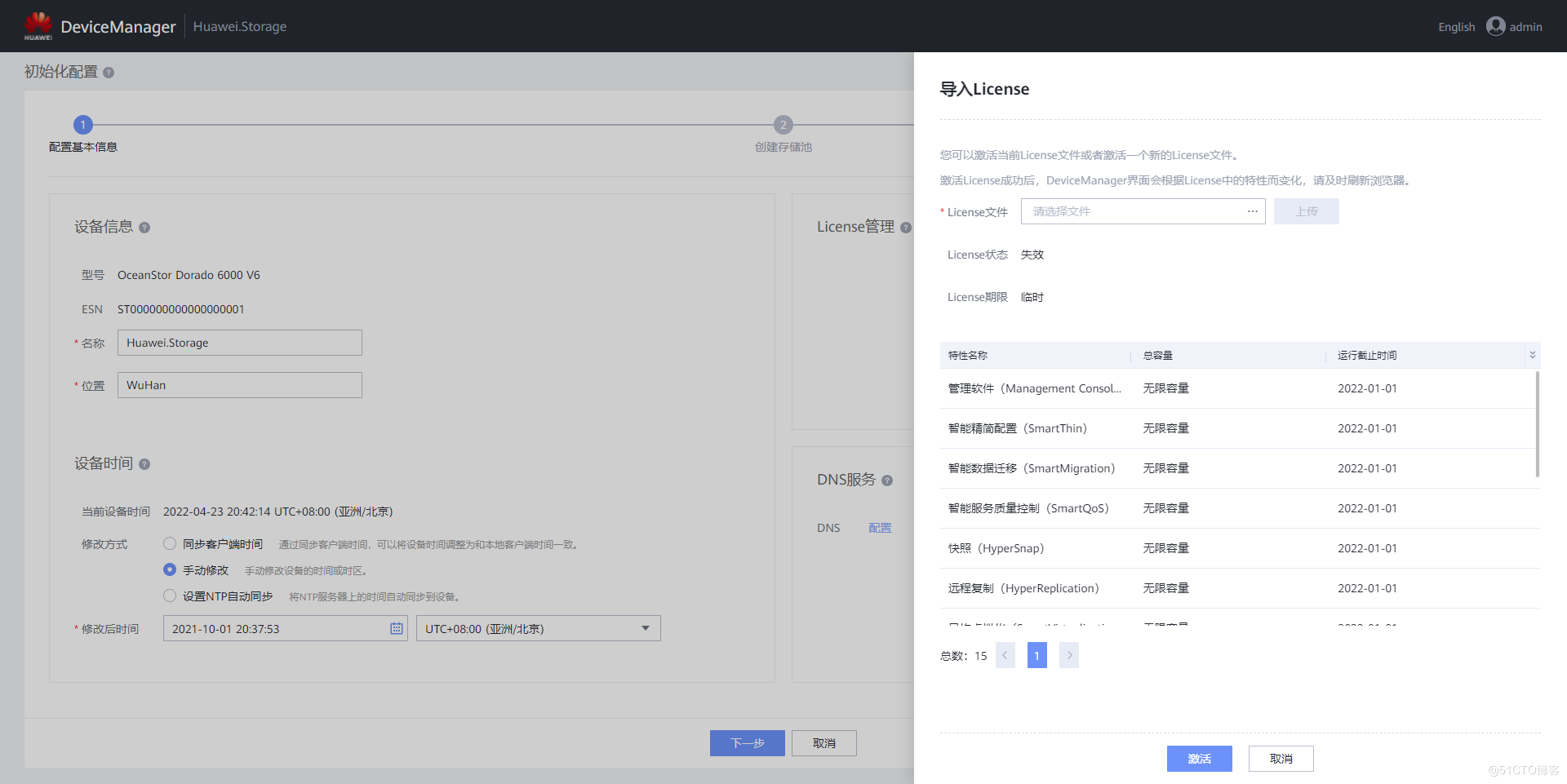
G008-HWY-CC-ESTOR-04 华为 Dorado V6 存储仿真器配置
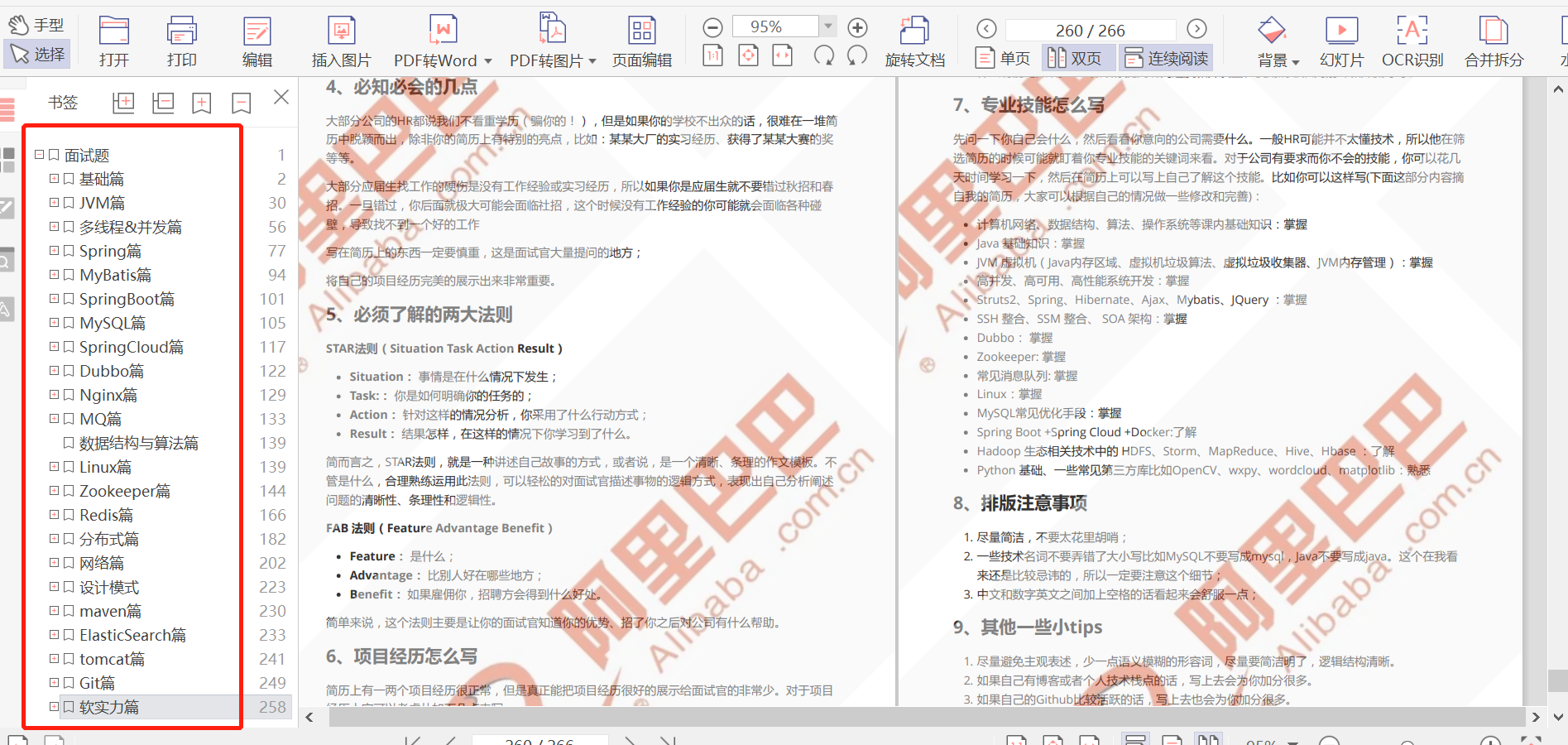
阿里研发三面,面试官一套组合拳让我当场懵逼
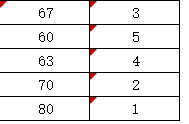
Set cell filling and ranking method according to the size of the value in the soft report
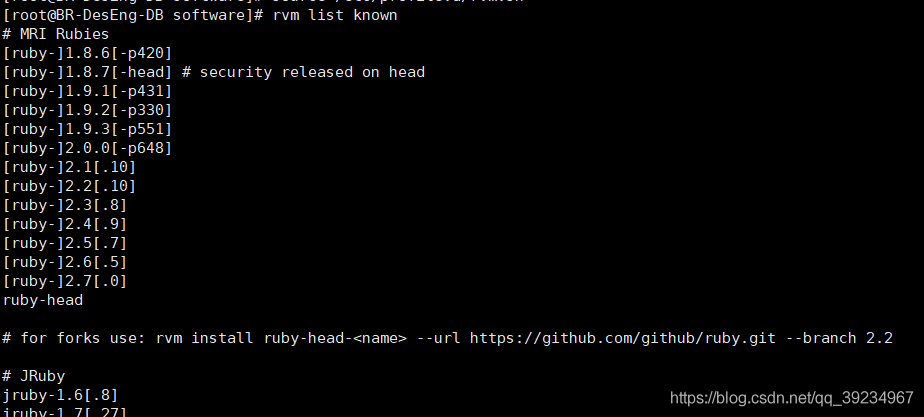
Install redis and deploy redis high availability cluster
JIRA screenshot
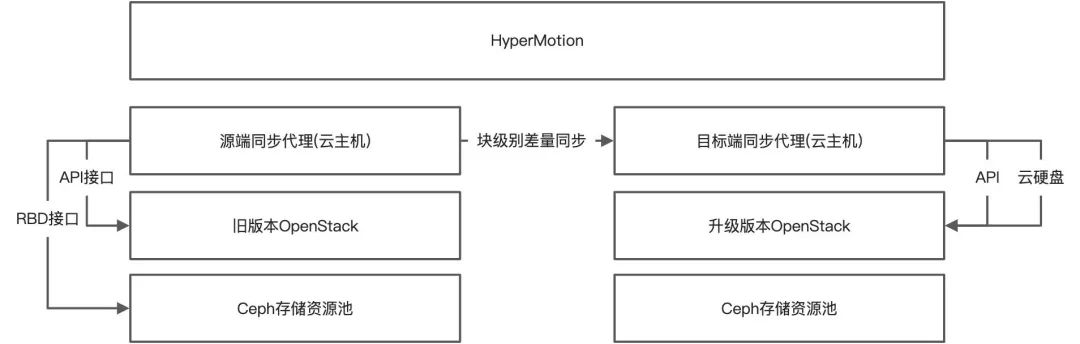
How to upgrade openstack across versions
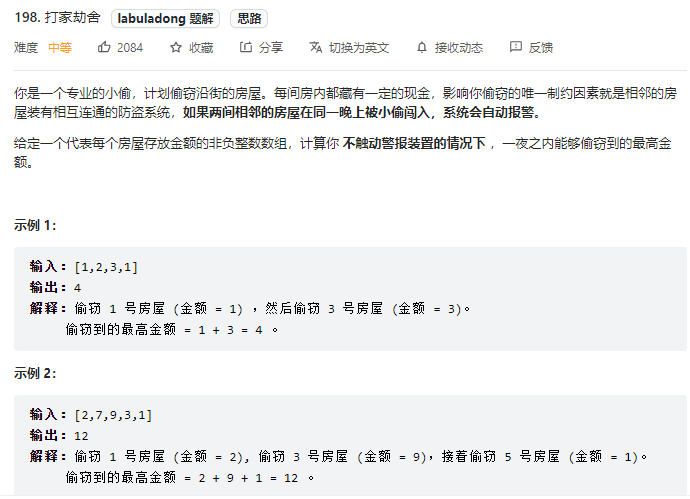
Force buckle - 198 raid homes and plunder houses

随机推荐
04 Lua 运算符
第九天 static 抽象类 接口
G008-hwy-cc-estor-04 Huawei Dorado V6 storage simulator configuration
Gartner predicts that the scale of cloud migration will increase significantly; What are the advantages of cloud migration?
Best practice of cloud migration in education industry: Haiyun Jiexun uses hypermotion cloud migration products to implement progressive migration for a university in Beijing, with a success rate of 1
如何进行应用安全测试(AST)
Cartoon: what are IAAs, PAAS, SaaS?
Gartner 發布新興技術研究:深入洞悉元宇宙
英语 | Day15、16 x 句句真研每日一句(从句断开、修饰)
05 Lua 控制结构
Countdown 1 day ~ 2022 online conference of cloud disaster tolerance products is about to begin
通过Feign在服务之间传递header请求头信息
JSP learning 3
Query the data from 2013 to 2021, and only query the data from 2020. The solution to this problem is carried out
About background image gradient()!
MySQL personal learning summary
众昂矿业:萤石浮选工艺
深度学习100例 | 第41天-卷积神经网络(CNN):UrbanSound8K音频分类(语音识别)
RecyclerView advanced use - to realize drag and drop function of imitation Alipay menu edit page
Grbl learning (II)