当前位置:网站首页>How to check if the online query suddenly slows down
How to check if the online query suddenly slows down
2022-08-11 00:21:00 【Wandering about the cat】
目录
Update the same data in parallel
系统架构
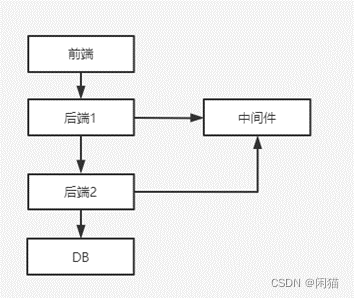
- 网络
- Competition for middleware
- The backend service itself is slow
- 竞争DB本身
- DB查询慢
网络层面
网络丢包,重传
If dual data centers are involved,Or multi-center office scenarios,就会有这种情况.
可以长时间ping测试丢包情况.
网卡满 比如大字段
使用dstatCommand to test network congestion
网络链路变长
Involves system integration,old system involved,This type of problem can be caused if the link length is called.
如果有catThis type of distributed link tracking system,可以看,Otherwise, it's not very easy to do
受到IO影响
如果数据库服务 There may be disks caused by backup servicesIO,CPU,内存被大量占用,导致查询变慢.The essence is that other services are occupied“主服务”资源导致.
If the backend service writes files in large batches, it will cause the diskIO抢占,cause slow operation
核查:
- 使用top检查CPU,memory consuming process
- 如果是后端服务,Query the memory usage of threads,top -Hp PID
- 用linux dstat验证IO读写情况
CPU/MEM
CPU和内存 It is usually caused by other services being occupied
服务
资源抢占
比如redis锁,DB连接 等.If this type of concurrency is high, a large number of threads will be in a waiting state.
检查:
- jstack 输出java栈
- jmap dump快照,使用jvisualvm,jprofiler,mat等工具分析
FullGc
频繁FullGCIt will cause service lag,CPU占有率升高
检查:
- 用jstat -gcutil pid 查看gc数量和时间
- 使用dump文件分析 可能的内存泄露
数据库
没有走索引
As the database grows,If it happens that a query condition does not go through the index,查询会比较慢.
检查:
- 查看慢sql
- 查看执行计划explain
Update the same data in parallel
常见的秒杀场景:数据库并发执行update,更新同一行的动作会被其他已经持有锁的会话堵住,并且需要要进行判断会不会由于自己的加入导致死锁
数据分布不均
a=11,10条数据
a=21,10W数据,Queries are naturally different
Inappropriate query
select *** from tt limit 10000000,10;
This kind needs to be found first10000000条,然后往后找10条
调整为:
select * from tt where id >= 10 limit 10;
表设计有问题
varchar(2000) text
调整:
- 纵向拆分,将varchar 2000 This field is split into another table
innodb 刷脏页
InnoDB引擎采用Write Ahead Log(WAL)策略,即事务提交时,先写日志(redo log),再写磁盘.为了提高IO效率,在写日志的时候会先写buffer,然后集中flush buffer pool 到磁盘. 这个过程 We call it dirtying pages.
这个过程中就有可能导致平时执行很快的SQL突然变慢.
边栏推荐
- YOLOv5的Tricks | 【Trick13】YOLOv5的detect.py脚本的解析与简化
- 池化技术有多牛?来,告诉你阿里的Druid为啥如此牛逼!
- EN 12467纤维水泥平板产品—CE认证
- 镜头之滤光片---关于日夜两用双通滤光片
- How to easily obtain the citation format of references?
- 线上突然查询变慢怎么核查
- 13. Content Negotiation
- C# JObject解析JSON数据
- SAS data processing technology (1)
- Web-based meal ordering system in epidemic quarantine area
猜你喜欢

![[Excel知识技能] 将文本型数字转换为数值格式](/img/7e/16a068025ec2639b343436c7f5b245.png)
![[Data Visualization] Chart Design Principles](/img/f3/691dd58d1e334f9f62efa23e27ec76.png)



随机推荐
有哪些可以投稿软件工程/系统软件/程序设计语言类外文期刊、会议?
Promise in detail
10. Notes on receiving parameters
只会懒汉式和饿汉式 你还不懂单例模式!
小程序onPageNotFound的坑
Difference Between Image Recognition and Semantic Segmentation
Is there a way out in the testing industry if it is purely business testing?
YOLOv5的Tricks | 【Trick10】从PyTorch Hub加载YOLOv5
百战RHCE(第四十八战:运维工程师必会技-Ansible学习3-构建Ansible清单)
CF1286E-Fedya the Potter Strikes Back【KMP,RMQ】
【C语言】探索数据的存储(整形篇)
两个链表的第一个公共节点——LeetCode
Part of the reserve bank is out of date
力扣------值相等的最小索引
Kunpeng compilation and debugging and basic knowledge of native development tools
In 22 years, the salary of programmers nationwide in January was released, only to know that there are so many with annual salary of more than 400,000?
SQL注入基础
14. Thymeleaf
The Missing Semester of Your CS Education
云原生-FRP内网穿透(详解)使用云服务器将内网集群服务暴露至公网(二)