当前位置:网站首页>Kubernetes应用发布思路分析
Kubernetes应用发布思路分析
2022-08-11 11:25:00 【51CTO】
2022.8.11心血来潮,写下了这篇内容,以下内容均来自个人理解,无摘抄,有不对的地方还请指出。
对于一个应用在kubernetes的发布,对于新人来说,常常会考虑不周到,束手无策,那么如何能够成为经验丰富的大牛呢?看如下(对于单体服务发布的思路):
1、应用镜像文件的制作(具体怎么制作这里就不多赘述了)。
2、应用是有状态的还是无状态的?具体要采用kubernetes哪种资源类型来进行部署。(这个是需要考虑的)
3、服务端口怎么暴露?(采用service还是ingress)
4、需要考虑应用数据文件、日志文件的持久化(这里就暂时不考虑,根据需求添加pv即可)
以上思路仅是单体服务发布思路。
那么想一下,生产场景(应用怎么部署呢?)
对于生产场景,App应用之间是存在耦合性的。怎么说呢?我就拿Java服务来举例子吧,因为目前来说Java项目还是占大头的(哈哈,因为目前我们公司的业务基本上都是java写的)。好,那我们来看项目发布需要考虑到的问题:
1、一般采用Java服务,都会采用自动注册和自动发现,那么对于这类服务,开发人员开发期间采用最多的就是Nacos、Eureka、Consul。具体这些服务我就不分析了。以我们公司为例,用的其实是Nacos。那么大家想一下,对于这类服务我们需要以单体服务发布思路来考虑吗?
首先:
(1)我们考虑一下镜像文件的制作,目前官网已经有现成的镜像文件,并且已经十分成熟,我们直接拿着用就行了。
(2)nacos应用是有状态的还是无状态的?具体要采用kubernetes哪种资源类型来进行部署?
可能大家还不知道什么是有状态服务什么是无状态服务,这里我给大家简单明了的说一下:
无状态服务不会在本地存储持久化数据,多个服务实例对于同一个用户请求的响应结果是完全一致的,这种多服务实例之间是没有依赖关系。
有状态服务需要在本地存储持久化数据,典型的是分布式数据库的应用,分布式节点实例之间有依赖的拓扑关系。比如:主从关系。如果K8S停止分布式集群中任一实例pod,就可能会导致数据丢失或者集群的crash。
那么我们现在知道了,nacos应用是无状态服务,所以我们就可以考虑具体要采用kubernetes哪种资源类型来进行部署。关于k8s资源类型需要大家做详细了解和学习啦,这里我就直接给出答案,建议:使用Statefulset管理有状态服务、Deployment来管理无状态服务。
(3)服务端口怎么暴露?在k8s中一般采用service和ingress进行端口暴露,service是基于IP端口暴露,ingress是基于域名暴露,然后代理到对应的service上。
2、服务发现和注册组件以及部署上去了,那么接下来就是SpringCloud中的Api网关服务了,微服务之间要通信,那就一定离不开网关这个桥梁。具体它的部署方式其实和nacos一样。参考上面即可。
3、接下来就是中间件服务的部署了,中间件服务大家应该都是比较了解的,比如:MySQL、MongoDB、Redis、ES、RabbitMQ等。
对于这类服务,我们就需要考虑它的数据存放问题。我们必须要保证数据的安全性、可用性(毕竟数据至上)。
对于数据存放的问题,在生产环境建议大家针对数据存放问题单独做一套数据存储集群,使用nfs或者ceph技术为k8s集群提供数据存储。
那么大家可能要问了?我为什么要花大价钱单独再弄一套存储呢?这个和K8s的功能息息相关,容我慢慢道来,假设:你有1M3N的集群环境,现在数据库调度到了N1机器,数据在N1做的存储(因为现在用的是单独创建的PV),现在机器突然down机,容器发生漂移,这时候它还能使用到N1机器存储的数据吗?这显然不可以。所以对于高可用就不贴合实际了。好,那么数据存储问题就聊到这里。
通过上面的学习,这里我们也应该知道这类中间件服务属于有状态服务,具体怎么部署,大家还得努努力学习。
然后我们还需要考虑的是服务端口怎么暴露,个人理解:对于这类中间件服务非必要不暴露端口,一般采用k8s内部FQDN进行通信即可。如果有特殊需求,可以采用端口暴露,上层可以使用一些安全审计、防火墙等一些设备(因为数据安全太重要了)。
4、接下来就是业务部署了。业务又分前端和后端。
(1)我们先来聊一下后端。我们需要考虑到:1.后端业务怎么连接中间件服务进行通信(这个问题显然也不是我们需要考虑的,嘿嘿,一般是在业务部署前,我们会把中间件通信地址给开发人员)。2.后端业务如何与网关通信,这一点很重要(这个问题显然也不是我们需要考虑的,我们只是一个执行者)。3.后端业务如何自动注册到Nacos(哈哈,这个问题显然不是我们考虑的,这是开发人员应该做的)。
那么对于后端业务进行容器化,我们应该怎么做呢?首先,业务开发完毕后,开发人员会把jar包给你,这个时候开发人员工作就已经完成了。我们需要做什么呢?第一步:我们需要将这些jar包使用dockerfile做成镜像。第二步:考虑日志是否要持久化存储,一般情况下是不需要的,因为我们后期可以使用EFK这种日志收集系统进行日志收集存储。第三步:考虑这类服务是有状态还是无状态,想必大家应该也知道了,无状态服务。第四步:端口暴露问题,可以直接告诉大家这类服务不需要进行端口暴露,因为之后客户访问前端,前端代理的gateway,然后gateway转发到对应后端服务上。
(2)接下来聊一下前端。这里就以vue项目为例。我们仅需要配置一个nginx,访问来过来的请求转发到gateway api网关上即可。无状态服务。端口暴露使用service + ingress方式进行暴露。
5、业务上线后,可以根据需求,部署集群、容器监控系统(prometheus技术栈)、日志收集系统(ELK Stack)、链路监控(skywalking)等。
好,那么到此为止,整套业务就完美上线了,当然,在部署期间肯定会有大大小小的坑等着我们运维工程师去排查。
这种方式对于显然对于业务量比较大的场合下是不合适的。那么延伸出去就又有了自动化应用交付场景(GitOps)。
那么想一下,生产场景(自动化应用交付场景怎么做呢?)
这里我先对架构做一个假想。如下:
Gitlab -> jenkins -> harbor -> 测试集群 -> 生产集群
这里我简述一下,开发人员推送代码到Gitlab仓库,jenkins检测仓库代码发生更新,然后拉取代码进行编译、构建镜像,构建好的镜像推送到harbor镜像仓库中,然后构建服务发布到测试环境的k8s集群中,测试没问题后,我们运维人员,点击确认发布到生产环境的k8s集群中。这是理想状态,也不难实现。
目前已经有了十分成熟的技术。自建流水线业务是可以的,不过成本会比较大。当然个人推荐大家可以学习一下KubeSphere技术栈,构建流水线业务还是十分方便的。
边栏推荐
- 智能恒等于推荐系统
- 【学习笔记】尚未用过的图论知识
- 【Study Notes】Unused graph theory knowledge
- Typora表格中常用操作
- LeetCode69:牛顿迭代法和二分法求解x的平方根
- Notes and Recommendations for Using Logs
- 【2022】【论文笔记】基于激光直写氧化石墨烯纸的超薄THz偏转——
- 老生常谈:面试必问“三次握手,四次挥手”这么讲,保证你忘不了
- 【2022】【Thesis Notes】Ultra-thin THz deflection based on laser direct writing graphene oxide paper——
- 文献阅读(185)Co-design
猜你喜欢

使用神经网络进行医学影像识别分析
centos linux 下安装mysql 8.0

天花板级微服务大佬总结出这份451页笔记告诉你微服务就该这么学
宝塔计划任务执行周期设置【秒】为定时单位【或者更小】
小目标绝技 | 用最简单的方式完成Yolov5的小目标检测升级!
The old saying: The interview must ask "Three handshakes, four waves", so you can't forget it
2022-08-10北京华为OD机试真题分享
Bitmap这个“内存刺客”你也要小心
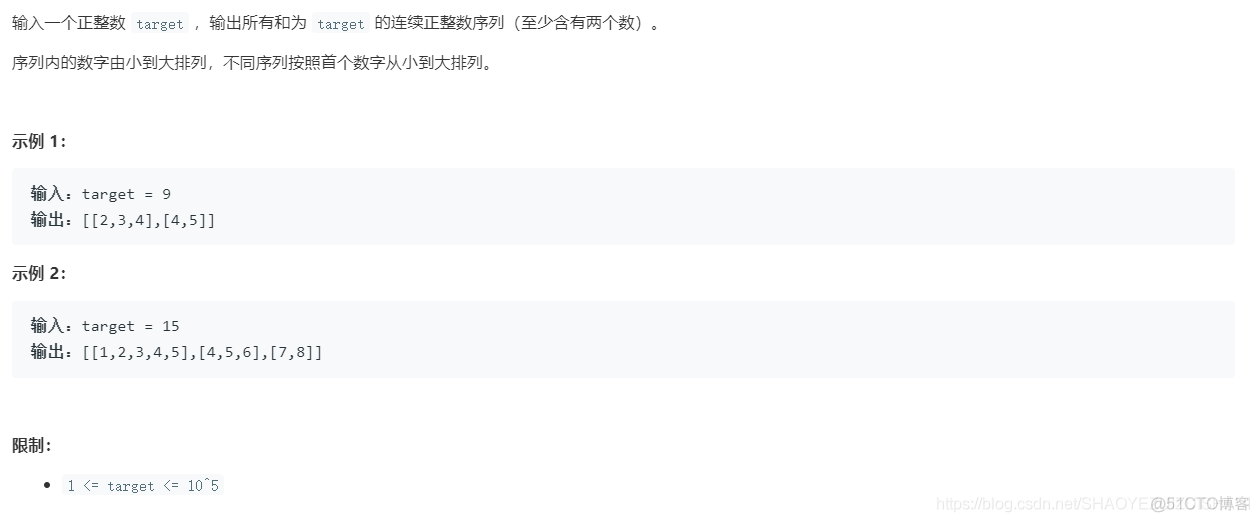
a sequence of consecutive positive numbers with sum s
如何批量下载hugging face模型和数据集文件
随机推荐
六、一起学习Lua 循环
C语言,怪题小谈
LeetCode·每日一题·1417.重新格式化字符串·模拟
五分钟教你内网穿透
【毕业设计】远程智能浇花灌溉系统 - stm32 单片机 嵌入式 物联网
挑战52天背完小猪佩奇(第02天)
LeetCode69:牛顿迭代法和二分法求解x的平方根
Incredible, thanks to this Android interview question, I have won offers from many Internet companies
Hugging Face快速入门(重点讲解模型(Transformers)和数据集部分(Datasets))
go语言学习:并发编程(Sync/GMP/爬虫案例)
【2022】【Thesis Notes】Ultra-thin THz deflection based on laser direct writing graphene oxide paper——
分析 Flink 任务如何超过 YARN 容器内存限制
我用这个操作,代码可读性提升一个档次
一站式PCBA组装加工有哪些环节?
2022-08-10北京华为OD机试真题分享
Neural network visualization has 3 d version of the, the United States to fall!(open source)
CCF大会腾源会专场即将召开,聚焦基础软件与开发语言未来发展
PerfView专题 (第一篇):如何寻找热点函数
Analyzes how Flink task than YARN container memory limit
黑马瑞吉外卖之公共字段自动填充