KalidoKit - Face, Pose, and Hand Tracking Kinematics
![]()
Kalidokit is a blendshape and kinematics solver for Mediapipe/Tensorflow.js face, eyes, pose, and hand tracking models, compatible with Facemesh, Blazepose, Handpose, and Holistic. It takes predicted 3D landmarks and calculates simple euler rotations and blendshape face values.
As the core to Vtuber web apps, Kalidoface and Kalidoface 3D, KalidoKit is designed specifically for rigging 3D VRM models and Live2D avatars!


Install
Via NPM
npm install kalidokit
import * as Kalidokit from "kalidokit";
// or only import the class you need
import { Face, Pose, Hand } from "kalidokit";
Via CDN
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/kalidokit.umd.js"></script>
Methods
Kalidokit is composed of 3 classes for Face, Pose, and Hand calculations. They accept landmark outputs from models like Facemesh, Blazepose, Handpose, and Holistic.
// Accepts an array(468 or 478 with iris tracking) of vectors
Kalidokit.Face.solve(facelandmarkArray, {
runtime: "tfjs", // `mediapipe` or `tfjs`
video: HTMLVideoElement,
imageSize: { height: 0, width: 0 },
smoothBlink: false, // smooth left and right eye blink delays
blinkSettings: [0.25, 0.75], // adjust upper and lower bound blink sensitivity
});
// Accepts arrays(33) of Pose keypoints and 3D Pose keypoints
Kalidokit.Pose.solve(poseWorld3DArray, poseLandmarkArray, {
runtime: "tfjs", // `mediapipe` or `tfjs`
video: HTMLVideoElement,
imageSize: { height: 0, width: 0 },
enableLegs: true,
});
// Accepts array(21) of hand landmark vectors; specify 'Right' or 'Left' side
Kalidokit.Hand.solve(handLandmarkArray, "Right");
// Using exported classes directly
Face.solve(facelandmarkArray);
Pose.solve(poseWorld3DArray, poseLandmarkArray);
Hand.solve(handLandmarkArray, "Right");
Additional Utils
// Stabilizes left/right blink delays + wink by providing blenshapes and head rotation
Kalidokit.Face.stabilizeBlink(
{ r: 0, l: 1 }, // left and right eye blendshape values
headRotationY, // head rotation in radians
{
noWink = false, // disables winking
maxRot = 0.5 // max head rotation in radians before interpolating obscured eyes
});
// The internal vector math class
Kalidokit.Vector();
Remixable VRM Template with KalidoKit
Quick-start your Vtuber app with this simple remixable example on Glitch. Face, full-body, and hand tracking in under 350 lines of javascript. This demo uses Mediapipe Holistic for body tracking, Three.js + Three-VRM for rendering models, and KalidoKit for the kinematic calculations. This demo uses a minimal amount of easing to smooth animations, but feel free to make it your own!

Basic Usage
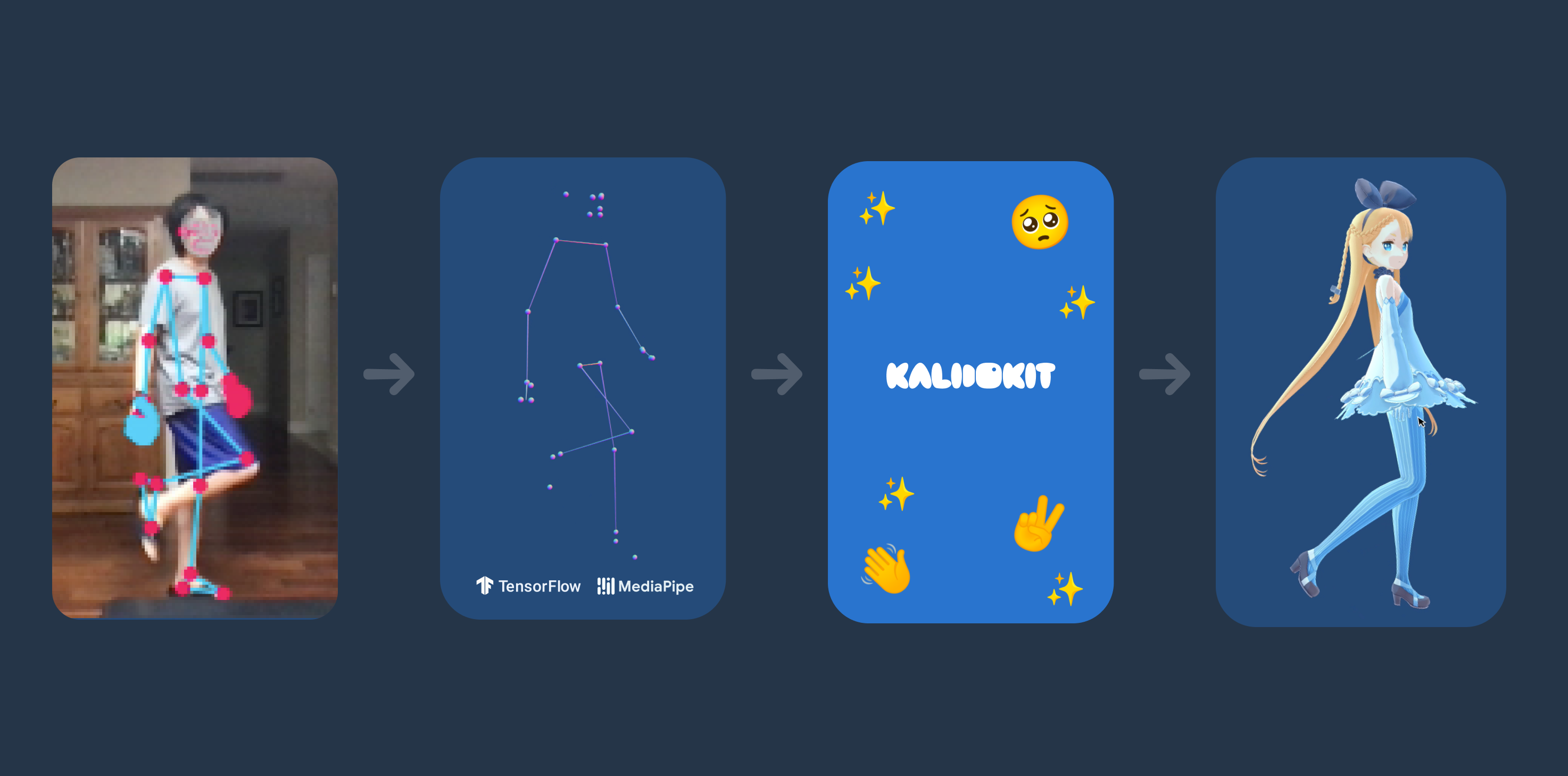
The implementation may vary depending on what pose and face detection model you choose to use, but the principle is still the same. This example uses Mediapipe Holistic which concisely combines them together.
import * as Kalidokit from 'kalidokit'
import '@mediapipe/holistic/holistic';
import '@mediapipe/camera_utils/camera_utils';
let holistic = new Holistic({locateFile: (file) => {
return `https://cdn.jsdelivr.net/npm/@mediapipe/[email protected]/${file}`;
}});
holistic.onResults(results=>{
// do something with prediction results
// landmark names may change depending on TFJS/Mediapipe model version
let facelm = results.faceLandmarks;
let poselm = results.poseLandmarks;
let poselm3D = results.ea;
let rightHandlm = results.rightHandLandmarks;
let leftHandlm = results.leftHandLandmarks;
let faceRig = Kalidokit.Face.solve(facelm,{runtime:'mediapipe',video:HTMLVideoElement})
let poseRig = Kalidokit.Pose.solve(poselm3d,poselm,{runtime:'mediapipe',video:HTMLVideoElement})
let rightHandRig = Kalidokit.Hand.solve(rightHandlm,"Right")
let leftHandRig = Kalidokit.Hand.solve(leftHandlm,"Left")
};
});
// use Mediapipe's webcam utils to send video to holistic every frame
const camera = new Camera(HTMLVideoElement, {
onFrame: async () => {
await holistic.send({image: HTMLVideoElement});
},
width: 640,
height: 480
});
camera.start();
Slight differences with Mediapipe and Tensorflow.js
Due to slight differences in the results from Mediapipe and Tensorflow.js, it is recommended to specify which runtime version you are using as well as the video input/image size as a reference.
Kalidokit.Pose.solve(poselm3D,poselm,{
runtime:'tfjs', // default is 'mediapipe'
video: HTMLVideoElement,// specify an html video or manually set image size
imageSize:{
width: 640,
height: 480,
};
})
Kalidokit.Face.solve(facelm,{
runtime:'mediapipe', // default is 'tfjs'
video: HTMLVideoElement,// specify an html video or manually set image size
imageSize:{
width: 640,
height: 480,
};
})
Outputs
Below are the expected results from KalidoKit solvers.
// Kalidokit.Face.solve()
// Head rotations in radians
// Degrees and normalized rotations also available
{
eye: {l: 1,r: 1},
mouth: {
x: 0,
y: 0,
shape: {A:0, E:0, I:0, O:0, U:0}
},
head: {
x: 0,
y: 0,
z: 0,
width: 0.3,
height: 0.6,
position: {x: 0.5, y: 0.5, z: 0}
},
brow: 0,
pupil: {x: 0, y: 0}
}
// Kalidokit.Pose.solve()
// Joint rotations in radians, leg calculators are a WIP
{
RightUpperArm: {x: 0, y: 0, z: -1.25},
LeftUpperArm: {x: 0, y: 0, z: 1.25},
RightLowerArm: {x: 0, y: 0, z: 0},
LeftLowerArm: {x: 0, y: 0, z: 0},
LeftUpperLeg: {x: 0, y: 0, z: 0},
RightUpperLeg: {x: 0, y: 0, z: 0},
RightLowerLeg: {x: 0, y: 0, z: 0},
LeftLowerLeg: {x: 0, y: 0, z: 0},
LeftHand: {x: 0, y: 0, z: 0},
RightHand: {x: 0, y: 0, z: 0},
Spine: {x: 0, y: 0, z: 0},
Hips: {
worldPosition: {x: 0, y: 0, z: 0},
position: {x: 0, y: 0, z: 0},
rotation: {x: 0, y: 0, z: 0},
}
}
// Kalidokit.Hand.solve()
// Joint rotations in radians
// only wrist and thumb have 3 degrees of freedom
// all other finger joints move in the Z axis only
{
RightWrist: {x: -0.13, y: -0.07, z: -1.04},
RightRingProximal: {x: 0, y: 0, z: -0.13},
RightRingIntermediate: {x: 0, y: 0, z: -0.4},
RightRingDistal: {x: 0, y: 0, z: -0.04},
RightIndexProximal: {x: 0, y: 0, z: -0.24},
RightIndexIntermediate: {x: 0, y: 0, z: -0.25},
RightIndexDistal: {x: 0, y: 0, z: -0.06},
RightMiddleProximal: {x: 0, y: 0, z: -0.09},
RightMiddleIntermediate: {x: 0, y: 0, z: -0.44},
RightMiddleDistal: {x: 0, y: 0, z: -0.06},
RightThumbProximal: {x: -0.23, y: -0.33, z: -0.12},
RightThumbIntermediate: {x: -0.2, y: -0.19, z: -0.01},
RightThumbDistal: {x: -0.2, y: 0.002, z: 0.15},
RightLittleProximal: {x: 0, y: 0, z: -0.09},
RightLittleIntermediate: {x: 0, y: 0, z: -0.22},
RightLittleDistal: {x: 0, y: 0, z: -0.1}
}
Community Showcase
If you'd like to share a creative use of KalidoKit, we would love to hear about it! Feel free to also use our Twitter hashtag, #kalidokit.


Open to Contributions
The current library is a work in progress and contributions to improve it are very welcome. Our goal is to make character face and pose animation even more accessible to creatives regardless of skill level!

 535 Nov 15, 2022
535 Nov 15, 2022
 91 Dec 14, 2022
91 Dec 14, 2022
 2 Oct 12, 2022
2 Oct 12, 2022
 10 Oct 19, 2022
10 Oct 19, 2022
 264 Jan 09, 2023
264 Jan 09, 2023
 2 Jul 17, 2022
2 Jul 17, 2022
 2 Aug 11, 2022
2 Aug 11, 2022
 0 Apr 19, 2022
0 Apr 19, 2022
 84 Jan 03, 2023
84 Jan 03, 2023
 29 Jan 05, 2023
29 Jan 05, 2023
 1 Jan 04, 2022
1 Jan 04, 2022
 6 Sep 17, 2022
6 Sep 17, 2022
 72 Dec 16, 2022
72 Dec 16, 2022
 5 Aug 14, 2022
5 Aug 14, 2022
 77 Dec 29, 2022
77 Dec 29, 2022
 8 Jun 10, 2022
8 Jun 10, 2022
 12 Dec 02, 2022
12 Dec 02, 2022
 24 Nov 11, 2022
24 Nov 11, 2022
 27 Sep 24, 2022
27 Sep 24, 2022
 6 Nov 14, 2022
6 Nov 14, 2022