当前位置:网站首页>入门:人脸专集2 | 人脸关键点检测汇总(文末有相关文章链接)
入门:人脸专集2 | 人脸关键点检测汇总(文末有相关文章链接)
2022-08-10 17:56:00 【计算机视觉研究院】
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
今天应该是“计算机视觉研究院”人脸专集的第2期,我们主要涉及目标检测与识别,主要在人脸领域做更多的详解。
接下来,我们针对人脸配准该领域详细讲解一次,今日主要涉及的就是人脸关键点检测,这个基础是人脸分析的基础,也是最重要的步骤之一。



往期回顾:
简 要
在人脸部分和轮廓周围的基准人脸关键点位置捕获了由于头部移动和面部表情造成的刚性和非刚性面部变形。
因此,它们对于各种面部分析任务非常重要。多年来,许多人脸关键点检测算法都是为了自动检测这些关键点而发展起来的,今天,我们对它们进行了广泛的综述。

今天所要讲解的,将人脸关键点检测算法分为三大类:整体方法、约束局部模型(CLM)方法和基于回归的方法。他们利用面部外观和形状信息的方式不同,整体方法显式地建立模型来表示全局的面部外观和形状信息;CLMs显式地利用全局形状模型,但构建局部外观模型;基于回归的方法隐式捕获人脸形状和外观信息。
对于每一类算法,我们今天就讨论它们的基本理论以及它们的不同之处。在不同的面部表情、头部姿势和遮挡情况下,还比较了它们在受控数据集和基准数据集上的性能。根据这些评价,我们指出了它们各自的优缺点,最后还单独回顾最新的基于深度学习的算法。
背 景
人脸在视觉传达中起着重要的作用。通过观察脸部,人类可以自动提取许多非语言信息,如人类的身份、意图和情感。
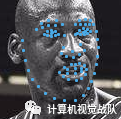
在计算机视觉中,为了自动提取这些人脸信息,基准的人脸关键点(下图)的定位通常是一个关键步骤,许多面部分析方法都是建立在对这些关键点的准确检测的基础上的。

例如,面部表情识别和头部姿态估计算法可能严重依赖于关键点位置提供的面部形状信息。眼睛周围的面部关键点可以提供瞳孔中心位置的初步猜测,用于眼睛检测和眼睛凝视跟踪。对于人脸识别,二维图像上的关键点位置通常与三维头部模型相结合,以“正面化”人脸,并帮助减少显着的变化,以提高识别精度。通过面部关键点位置获取的面部信息可以为人机交互、娱乐、安全监视和医疗应用提供重要信息。
人脸关键点检测算法的目的是自动识别面部关键点在面部图像或视频中的位置。这些关键点要么是描述人脸部件的独特位置(例如眼角)的优势点,要么是将这些优势点与人脸部件和轮廓连接起来的插值点。形式上,给定一个以i表示的面部图像,一个检测算法预测d的关键点:x={x1,y1,x2,y2,...,xd,yd}的位置,其中x和y是面部图像关键点的坐标。
Holistic methods
1
整体方法显式地利用整体面部外观信息以及全局面部形状进行面部关键点检测(下图)。接下来,我先介绍经典的整体方法:主动外观模型(AAM);然后,介绍它的几个扩展。
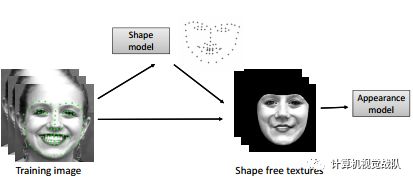
AAM
由Taylor和Cootes引入了主动外观模型(AAM)。它是一种统计模型,用少量的系数拟合人脸图像,控制人脸的外观和形状的变化。在建模过程中,AAM建立了基于主成分分析(PCA)的全局人脸形状模型和整体人脸外观模型。
在检测过程中,它通过将学习到的外观和形状模型与测试图像进行拟合来识别关键点位置。

图A 学习形状变化

图B 学习外观变化
基于学习的拟合方法的分析拟合方法

相比于解析拟合方法,用梯度下降算法求解Hissian矩阵和Jacobian矩阵,基于学习的拟合方法采用常量线性或非线性回归函数逼近最陡下降方向。因此,基于学习的拟合方法通常是快速的,但它们可能不准确。
分析方法不需要训练图像,而拟合方法需要训练图像。基于学习的拟合方法通常使用第三PCA来学习形状系数和外观系数之间的联合相关性,从而进一步减少未知系数的数量,而解析拟合方法通常不这样做。但是,对于解析拟合方法,外形系数和形状系数之间的相互作用可以嵌入到联合拟合目标函数中。形状系数与外观系数之间的相关性可以减少参数的个数,这种学到的相关性可能不能很好地推广到不同的图像。用联合拟合目标函数进行形状系数和外观系数联合估计可以得到更准确的结果。
其他拓展

特征表示
传统的AAM方法还有其他扩展。一个特别的方向是改进特征表示。众所周知,AAM模型泛化能力有限,难以拟合不可见的人脸变化(如:跨对象、光照、部分遮挡等)。
这一限制部分是由于使用原始像素强度作为特征。为了解决这个问题,一些算法使用了更鲁棒的图像特征。例如,不使用原始像素强度,而是使用小波特征来建模面部外观。另外,仅利用局部外观信息来提高对局部遮挡和光照的鲁棒性;采用高斯混合模型的Gabor小波对局部图像进行建模,实现了局部点的快速搜索。这两种方法都提高了传统AAM方法的性能。
2
Constrained local methods
如下图所示,约束局部模型(CLM)方法根据全局面部形状模式以及每个关键点周围独立的局部外观信息推断出关键点位置x,与整体外观相比,该方法更容易捕获,并且对光照和遮挡更有鲁棒性。
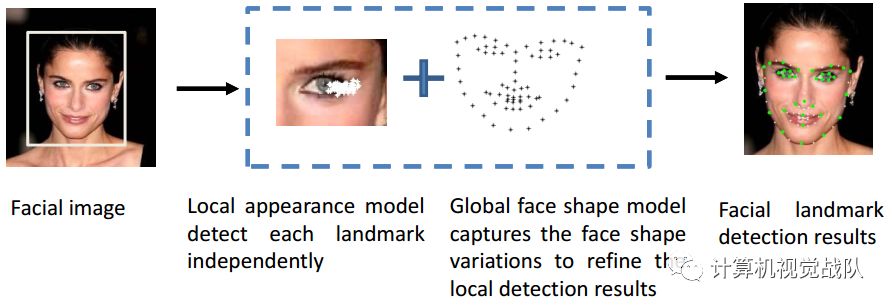
局部外观模型

与局部外观模型相关的问题有几个。首先,存在准确性-鲁棒性权衡。例如,大的局部块更鲁棒,而对于精确的关键点定位则不太准确。一个小块,更独特的外观信息,将导致更准确的检测结果。
为了解决这个问题,一些算法(Ren, S., Cao, X., Wei, Y., Sun, J.: Face alignment at 3000 fps via regressing local binary features. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1685–1692 (2014))将大块和小块结合起来进行估计,并在迭代过程中调整块的大小或搜索区域。其次,在基于分类器的方法和基于回归的方法之间,还不清楚应该遵循哪种方法?
基于回归的方法的一个优点是,它只需要计算特征和预测几个样本块在测试中的位移向量。它比基于分类的扫描感兴趣区域内所有像素位置的方法更有效。经验表明,GentleBoost回归模型作为基于回归的外观模型优于GentleBoost分类器作为基于分类器的局部外观模型。
Regression-based methods
3
基于回归的方法直接从图像外观到关键点位置的映射学习。与整体方法和约束局部模型方法不同的是,它们通常不显式地建立任何全局人脸模型。相反,面部形状约束可以隐式嵌入。通常,基于回归的方法可分为直接回归法、级联回归法和深度学习回归法。直接回归方法在没有初始化的情况下,在一次迭代中对关键点进行预测,而级联回归方法则进行级联预测,通常需要初始的关键点位置。基于深度学习的方法要么遵循直接回归,要么遵循级联回归。由于它们使用了独特的深度学习方法,我们之后会分别讨论。
级联回归方法


与执行一步预测的直接回归方法相比,级联回归方法从对面部关键点位置(例如均值脸)的初始猜测开始,并通过不同阶段学习的不同回归函数逐步更新关键点位置(如上图)。
具体而言,在训练中,在每个阶段,应用回归模型来学习形状索引图像外观(例如,根据当前估计的关键点位置提取的局部外观)到形状更新之间的映射。从早期开始的学习模型将用于更新下一阶段的训练数据。在测试期间,学习到的回归模型依次应用于跨迭代更新形状。

今天就先到这里,下次我们继续接着"人脸关键点"相关知识进行展开讲解。接下来给大家展示一些比较成功的案例。




THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
我们开创“计算机视觉协会”知识星球两年有余,也得到很多同学的认可,最近我们又开启了知识星球的运营。我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606


边栏推荐
猜你喜欢


随机推荐
三星Galaxy Watch5产品图片流出 非Pro表款亦有蓝宝石加持
awk if else if else
验算移位距离和假设的通用性
img转base64
Toronto Research Chemicals BTK甜味剂配方丨D-Abequose
pyspark列合并为一行
一小时搞定 简单VBA编程 Excel宏编程快速扫盲
Xilinx FPGA收发器参考时钟设计应用
zabbix配置触发器
施工企业数字化转型解决方案设计思路
AVFrame相关api内存管理
Kong自定义插件初体验
Scala中使用 Jackson API 进行JSON序列化和反序列化
Scala中使用 Jackson API 进行JSON序列化和反序列化
Product Description丨MobPush fast integration method on Android side
Word里表格跨页时自动断开,表格后留有空白部分,未布满整页,如何操作让表格上下页均匀布满?
开发模式对测试的影响
机器人控制器编程实践指导书旧版-实践五 数字舵机(执行器)
go语言的性能基准测试、性能优化测试和性能调优
EasyGBS连接mysql数据库提示“can’t connect to mysql server”,如何解决?