当前位置:网站首页>[NLP] HMM hidden Markov + Viterbi word segmentation
[NLP] HMM hidden Markov + Viterbi word segmentation
2022-04-23 14:45:00 【myaijarvis】
【 Reference resources :NLP-HMM Hidden Markov + Viterbi participle , Code + data + Explain _ Bili, Bili _bilibili】 PPT simple , Very good
【 Reference resources :shouxieai/nlp-hmm-word-cut: nlp-hmm-word-cut】
How to explain viterbi Algorithm ? - Lu Sheng's answer - You know
How to explain viterbi Algorithm ? - JustCoder Answer - You know
PPT
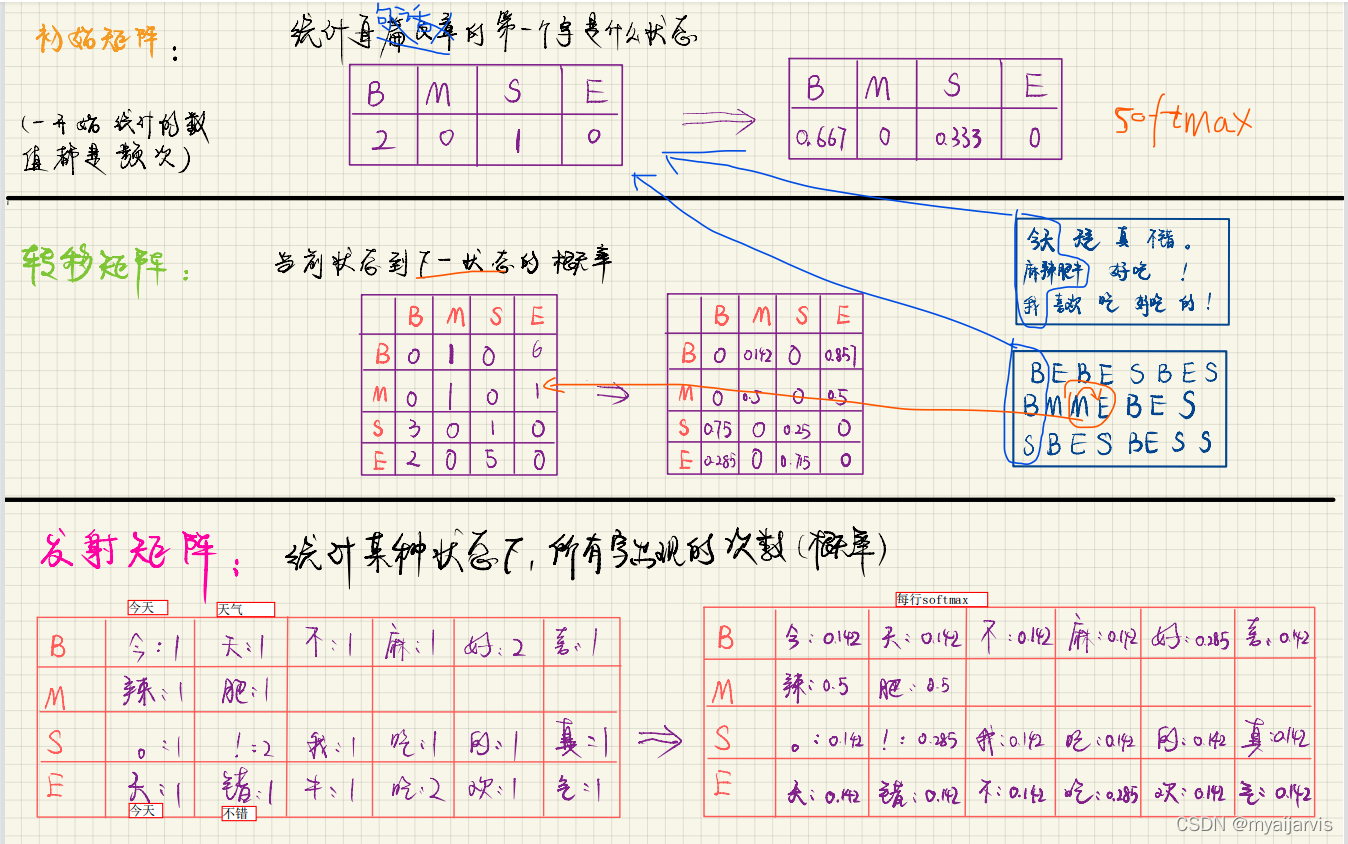
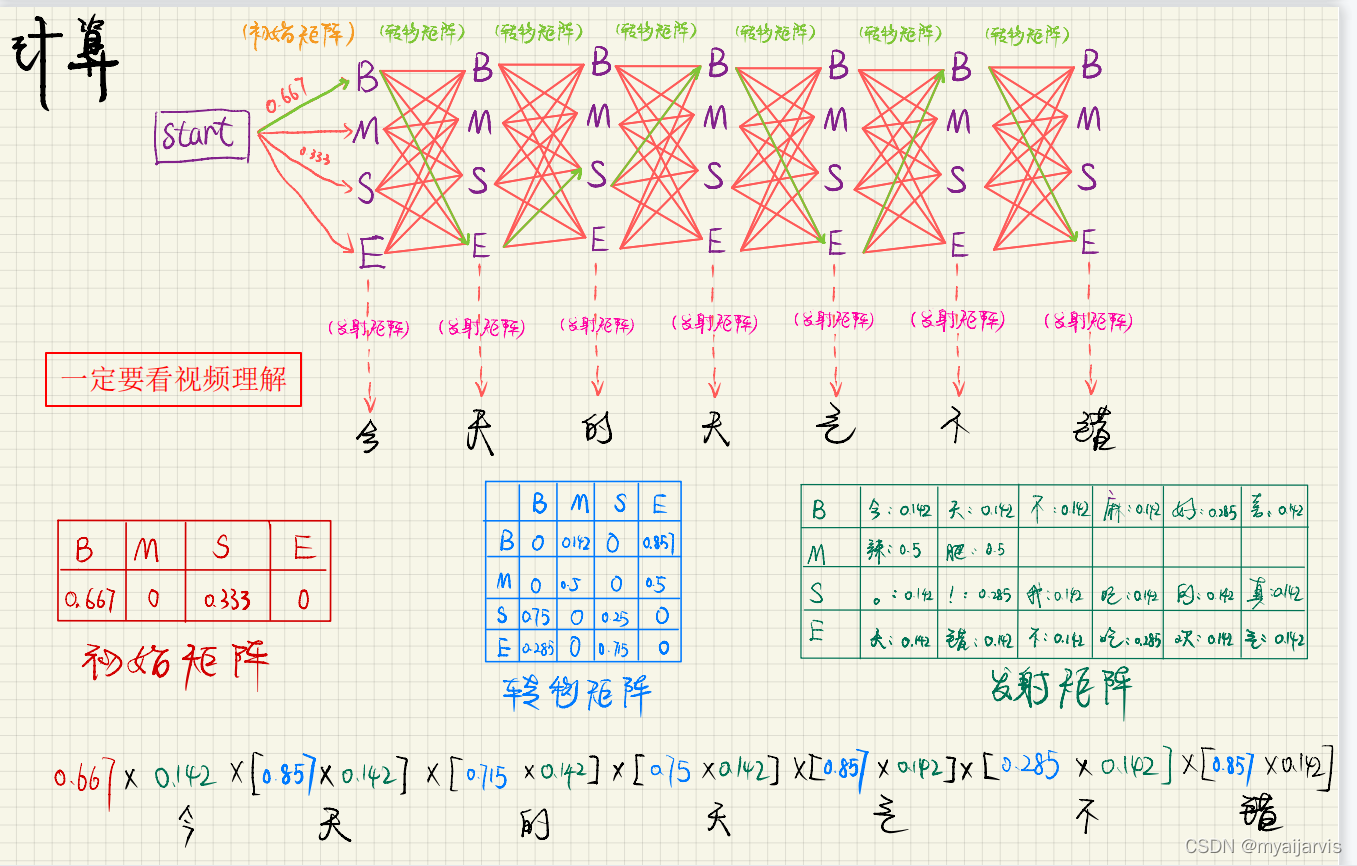
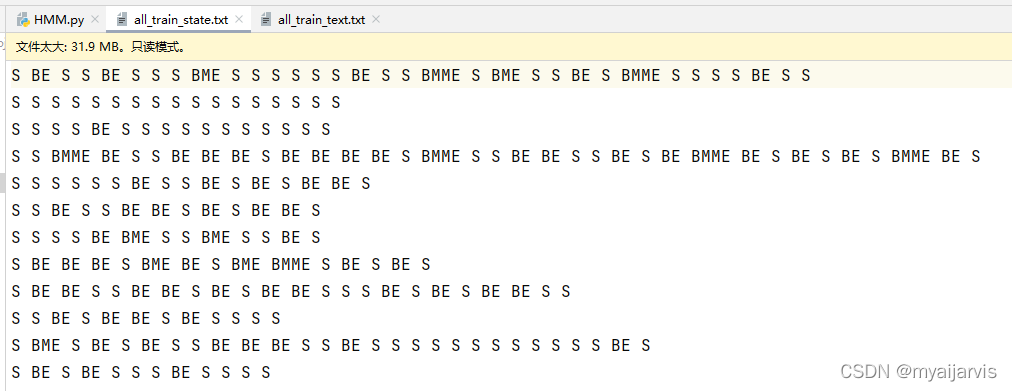
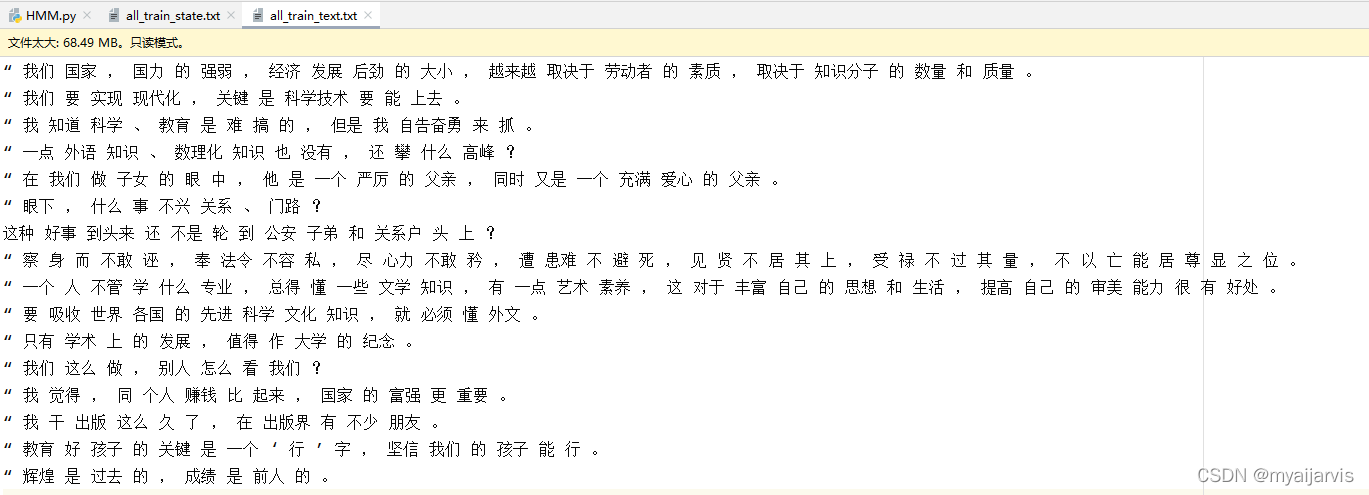
Code
import pickle
from tqdm import tqdm
import numpy as np
import os
def make_label(text_str): # From words to label Transformation , Such as : today ----> BE Spicy fat cattle : ---> BMME Of ---> S
text_len = len(text_str)
if text_len == 1:
return "S"
return "B" + "M" * (text_len - 2) + "E" # Except that it starts with B, It ends with E, It's all in the middle M
# Convert the original corpus into Corresponding status file Such as : I have to go to school today -> BE S BE
def text_to_state(file="all_train_text.txt"): # Convert the original corpus into Corresponding status file
# all_train_text It has been divided into words with spaces
if os.path.exists("all_train_state.txt"): # If the file exists , Just quit
return
all_data = open(file, "r", encoding="utf-8").read().split("\n") # Open the file and slice it to all_data in , all_data It's a list
with open("all_train_state.txt", "w", encoding="utf-8") as f: # Open the written file
for d_index, data in tqdm(enumerate(all_data)): # Line by line Traverse , tqdm Is the progress bar prompt , data It's an article ( a line ), It could be empty
if data: # If data Not empty
state_ = ""
for w in data.split(" "): # At present The article is segmented according to the space , w Is a word in the article
if w: # If w Not empty
state_ = state_ + make_label(w) + " " # Make a single word label
if d_index != len(all_data) - 1: # Don't add... To the last line "\n" Add... To all other lines "\n"
state_ = state_.strip() + "\n" # Take out every line The last space
f.write(state_) # write file , state_ Is a string
# Definition HMM class , In fact, the key is the three matrices
class HMM:
def __init__(self, file_text="all_train_text.txt", file_state="all_train_state.txt"):
self.all_states = open(file_state, "r", encoding="utf-8").read().split("\n")[:200] # Get all status by line
self.all_texts = open(file_text, "r", encoding="utf-8").read().split("\n")[:200] # Get all text by line
self.states_to_index = {
"B": 0, "M": 1, "S": 2, "E": 3} # Define an index for each state , Later, you can get the index according to the status
self.index_to_states = ["B", "M", "S", "E"] # Get the corresponding status according to the index
self.len_states = len(self.states_to_index) # State length : Here is 4
# The most important is the following three matrices
self.init_matrix = np.zeros((self.len_states)) # The initial matrix : 1 * 4 , The corresponding is BMSE
self.transfer_matrix = np.zeros((self.len_states, self.len_states)) # Transition state matrix : 4 * 4 ,
# Emission matrix , The use of 2 level Dictionary nesting
# # Notice that a... Is initialized here total key , Stores the total number of occurrences of the current state , For later normalization, use
self.emit_matrix = {
"B": {
"total": 0}, "M": {
"total": 0}, "S": {
"total": 0}, "E": {
"total": 0}}
# Calculation The initial matrix
def cal_init_matrix(self, state):
self.init_matrix[self.states_to_index[state[0]]] += 1 # BMSE Four kinds of state , The corresponding status appears 1 Time Just +1
# Calculate the transfer matrix
def cal_transfer_matrix(self, states):
sta_join = "".join(states) # State shift Transfer from the current state to the next state , namely from sta1 Each element is transferred to sta2 in
sta1 = sta_join[:-1]
sta2 = sta_join[1:]
for s1, s2 in zip(sta1, sta2): # At the same time through s1 , s2
self.transfer_matrix[self.states_to_index[s1], self.states_to_index[s2]] += 1
# Calculate the emission matrix
def cal_emit_matrix(self, words, states):
for word, state in zip("".join(words), "".join(states)): # The first words and states Put them together and go through , Because there's a space in the middle
self.emit_matrix[state][word] = self.emit_matrix[state].get(word, 0) + 1
self.emit_matrix[state]["total"] += 1 # Note that there is an additional total key , Stores the total number of occurrences of the current state , For later normalization, use
# Normalize the matrix
def normalize(self):
self.init_matrix = self.init_matrix / np.sum(self.init_matrix)
self.transfer_matrix = self.transfer_matrix / np.sum(self.transfer_matrix, axis=1, keepdims=True) # Every line
# here *1000 In order not to make the probability too small , You can also do without this
self.emit_matrix = {
state: {
word: t / word_times["total"] * 1000 for word, t in word_times.items() if word != "total"} for
state, word_times in self.emit_matrix.items()}
# Training begins , In fact, that is 3 The process of solving a matrix
def train(self):
if os.path.exists("three_matrix.pkl"): # If parameters already exist No more training
self.init_matrix, self.transfer_matrix, self.emit_matrix = pickle.load(open("three_matrix.pkl", "rb"))
return
for words, states in tqdm(zip(self.all_texts, self.all_states)): # Read the file by line , call 3 A matrix solving function
words = words.split(" ") # In the document They are segmented according to the space
states = states.split(" ")
self.cal_init_matrix(states[0]) # Calculate three matrices
self.cal_transfer_matrix(states)
self.cal_emit_matrix(words, states)
self.normalize() # After the matrix is solved, it is normalized
pickle.dump([self.init_matrix, self.transfer_matrix, self.emit_matrix], open("three_matrix.pkl", "wb")) # Save parameters
# This implementation is a little difficult
def viterbi_t(text, hmm):
states = hmm.index_to_states
emit_p = hmm.emit_matrix
trans_p = hmm.transfer_matrix
start_p = hmm.init_matrix
V = [{
}]
path = {
}
for y in states:
V[0][y] = start_p[hmm.states_to_index[y]] * emit_p[y].get(text[0], 0)
path[y] = [y]
for t in range(1, len(text)):
V.append({
})
newpath = {
}
# Check whether there is this word in the transmission probability matrix of training
neverSeen = text[t] not in emit_p['S'].keys() and \
text[t] not in emit_p['M'].keys() and \
text[t] not in emit_p['E'].keys() and \
text[t] not in emit_p['B'].keys()
for y in states:
emitP = emit_p[y].get(text[t], 0) if not neverSeen else 1.0 # Set unknown words to separate words
# Choose one of the four paths with the greatest probability
temp = []
for y0 in states:
if V[t - 1][y0] >= 0: # error correction Here is >=
temp.append((V[t - 1][y0] * trans_p[hmm.states_to_index[y0], hmm.states_to_index[y]] * emitP, y0))
(prob, state) = max(temp)
# (prob, state) = max([(V[t - 1][y0] * trans_p[hmm.states_to_index[y0],hmm.states_to_index[y]] * emitP, y0) for y0 in states if V[t - 1][y0] >= 0])
V[t][y] = prob
newpath[y] = path[state] + [y]
path = newpath
(prob, state) = max([(V[len(text) - 1][y], y) for y in states]) # Find the path of the maximum concept
result = "" # Joining together the results
for t, s in zip(text, path[state]):
result += t
if s == "S" or s == "E": # If it is S perhaps E Just add a space after
result += " "
return result
if __name__ == "__main__":
text_to_state()
# text = " Although the procession was silent all the way "
text = " No matter what major a person studies , You have to know something about literature , A little artistic quality , This is for enriching your thoughts and life , It's good to improve your aesthetic ability "
# text = " Peking University, Beijing " # It's not good to involve professional vocabulary , Because there is no relevant corpus in the training text
# debug In contrast ppt It's easier to understand the process
hmm = HMM()
hmm.train()
result = viterbi_t(text, hmm)
print(result)
One people nothing On learning what major , It has to be understand some literature knowledge , Yes One o'clock art Accomplishment , this about Enrich own Of thought and life , Improve own Of taste Ability very Yes benefits
版权声明
本文为[myaijarvis]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231426205752.html
边栏推荐
- Don't you know the usage scenario of the responsibility chain model?
- A blog allows you to learn how to write markdown on vscode
- LM317的直流可调稳压电源Multisim仿真设计(附仿真+论文+参考资料)
- 51单片机+LCD12864液晶显示的俄罗斯方块游戏,Proteus仿真、AD原理图、代码、论文等
- 一篇博客让你学会在vscode上编写markdown
- 8.4 循环神经网络从零实现
- 压缩映射定理
- One of the advanced applications of I / O reuse: non blocking connect -- implemented using select (or poll)
- 【STC8G2K64S4】比较器介绍以及比较器掉电检测示例程序
- Swift:Entry of program、Swift调用OC、@_silgen_name 、 OC 调用Swift、dynamic、String、Substring
猜你喜欢



随机推荐
【Proteus仿真】自动量程(范围<10V)切换数字电压表
First acquaintance with STL
Arduino for esp8266串口功能简介
ASEMI三相整流桥和单相整流桥的详细对比
I thought I could lie down and enter Huawei, but I was confused when I received JD / didi / iqiyi offers one after another
成都控制板设计提供_算是详细了_单片机程序头文件的定义、编写及引用介绍
Raised exception class eaccexviolation with 'access violation at address 45efd5 in module error
Interviewer: let's talk about the process of class loading and the mechanism of class loading (parental delegation mechanism)
LotusDB 设计与实现—1 基本概念
OC to swift conditional compilation, marking, macro, log, version detection, expiration prompt
Usage of BC
【JZ46 把数字翻译成字符串】
Matlab Simulink modeling and design of single-phase AC-AC frequency converter, with MATLAB simulation, PPT and papers
线程同步、生命周期
单片机的函数信号发生器,输出4种波形,频率可调,原理图,仿真和C程序
电子秤称重系统设计,HX711压力传感器,51单片机(Proteus仿真、C程序、原理图、论文等全套资料)
八路抢答器系统51单片机设计【附Proteus仿真、C程序、原理图及PCB文件、元器件清单和论文等】
全连接层的作用是什么?
Model location setting in GIS data processing -cesium
Proteus simulation design of four storey and eight storey elevator control system, 51 single chip microcomputer, with simulation and keil c code