当前位置:网站首页>Machine learning (VI) -- Bayesian classifier
Machine learning (VI) -- Bayesian classifier
2022-04-23 09:04:00 【A large piece of meat floss】
Bayesian classifier is the general name of a class of classification algorithms , Are based on Bayesian theorem
One 、 Preliminary knowledge — Bayesian decision theory
1. The formula
\qquad Bayesian decision theory is the basic method of implementing decision under the framework of probability . For classification tasks , In the ideal case where all relevant probabilities are known , Bayesian decision theory considers how to select the optimal category marker based on probability and misjudgment loss .
\qquad Suppose there is N Output categories , Expressed as y y y={ c 1 , c 2 , c 3 . . . . . c N c_1,c_2,c_3.....c_N c1,c2,c3.....cN}
\qquad λ i j \lambda_{ij} λij It means that a real belongs to c j c_j cj The samples were misclassified as c i c_i ci Loss incurred .
\qquad Then the sample x x x Classified as c i c_i ci The expected loss incurred , In the sample x x x Upper “ Conditional risk ” by :
The above formula can be understood as :


To achieve the correct classification , You need to minimize the expected loss , The above is the expected loss of a single sample , Then the overall loss expectation is :
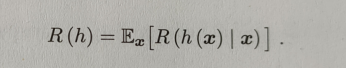
\qquad According to the above formula, we can know , If conditional risk is minimized for each sample , Then the overall risk R ( h ) R(h) R(h), It will also be minimized . This produces Bayesian criteria : To minimize the overall risk , Just select the one on each sample that makes the conditional risk R ( c ∣ x ) R(c|x) R(c∣x) The smallest category mark .

h ∗ h^* h∗ It's called Bayesian optimal classifier .
2. Minimize classification error rate
Miscalculation of loss λ i j \lambda_{ij} λij, Set to 0/1 Loss function :

At this point, conditional risk :

The origin of the above formula :

Therefore, the Bayesian optimal classifier to minimize the classification error rate is :

For each sample x x x, Selection can make a posteriori probability P ( c ∣ x ) P(c|x) P(c∣x) Maximum category tag
3. Posterior probability
\qquad From the above explanation , It is required to minimize the risk of decision-making , First, we need to obtain a posterior probability P ( c ∣ x ) . P(c|x). P(c∣x).
\qquad From this perspective , The task of machine learning is to estimate the posterior probability as accurately as possible based on the limited training sample set P ( c ∣ x ) P(c|x) P(c∣x), Depending on the generation strategy , It is divided into two models :
Discriminant model
Generative model
The so-called discriminant model , Direct modeling a posteriori probability P ( c ∣ x ) . P(c|x). P(c∣x).
The so-called generative model ,: For joint probability distribution P ( c , x ) P(c,x) P(c,x) modeling , Then we get the posterior probability P ( c ∣ x ) . P(c|x). P(c∣x).
Generative model :

Based on Bayesian theorem, it can be written as :

among : P ( c ∣ x ) : after Examination General rate P(c|x): Posterior probability P(c∣x): after Examination General rate
P ( c ) : First Examination General rate P(c): Prior probability P(c): First Examination General rate
P ( x ∣ c ) : like however General rate P(x|c): Likelihood probability P(x∣c): like however General rate
Two 、 Maximum likelihood estimation
According to Bayes theorem :

Find the maximum a posteriori probability P ( c ∣ x ) P(c|x) P(c∣x) To find the maximum likelihood P ( x ∣ c ) P(x|c) P(x∣c).
\qquad Let the training set be D D D
\qquad The first c c c The label of the class is θ c \theta_c θc
\qquad Ji Youdi c The collection of tags of class is D c D_c Dc( Personal understanding D c : D_c: Dc: It refers to which features in the set can be combined to get θ c \theta_c θc Class sample )
\qquad Suppose these samples are independent and identically distributed , The parameter θ c \theta_c θc For datasets D c D_c Dc The likelihood of :
The above formula is the continuous multiplication operation , Easy to cause underflow , We usually use logarithmic likelihood :


3、 ... and 、 Naive Bayes classifier
1. Definition
Naive Bayes classifier uses “ Assumption of independence of attribute condition ”: For known categories , Suppose all the attributes are independent of each other .
According to the assumption of attribute conditional independence , Rewritable Bayesian rule :
That is to maximize :
Make D c D_c Dc Represents a training set D D D pass the civil examinations c Set of class samples , A priori probability can be calculated according to the properties of independent identically distributed P ( c ) P(c) P(c):
Make D c , x i D_{c,x_i} Dc,xi Express D c D_c Dc In the first place i i i The value of each attribute is x i x_i xi A collection of samples , Then the conditional probability P ( x i ∣ c ) P(x_i|c) P(xi∣c):
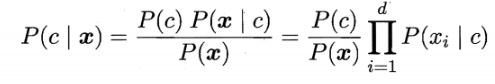



2. Calculation case
In order to avoid the information carried by other attributes being erased by attribute values that do not appear in the training set , When estimating the probability, we usually have to “ smooth “, Commonly used ” Laprado correction “.
Four 、 Semi naive Bayesian classifier
In a real task , It can not meet the attribute conditions assumed by naive Bayes , That is, it is difficult to establish .
Thus, the semi naive Bayesian classifier is generated
\qquad The basic idea of semi naive Bayesian classifier : Due consideration should be given to the interdependent information among some attributes , Joint probability calculation is not required , And it doesn't completely ignore the strong attribute dependency .
\qquad ” Independent estimation “(One-Dependent Estimation ,ODE) It is the most commonly used strategy of semi naive Bayesian classifier , That is, it is assumed that each attribute depends on at most one other attribute outside the category , namely

Different approaches , Different dependent classifiers can be generated :
SPORT
TAN
AODE
5、 ... and 、 Bayesian networks
Bayesian network engraving draws the dependencies between all attributes .
Bayesian networks , It's called “ Faith net ”;
In a real task , Bayesian networks are unknown , We need to find the most appropriate Bayesian network according to the training set .
“ Score search ” Is a common way to solve this problem .
\qquad But reality , It is a problem to find the optimal Bayesian network structure from the training set NP Difficult problem , Difficult to solve quickly .
\qquad There are two common strategies that can solve the approximate solution in a limited time :
\qquad The first one is : The law of greed , For example, starting from a certain network structure , Adjust one edge at a time , Until the value of the scoring function no longer decreases ;
\qquad The second kind : Reduce the search space by imposing constraints on the network structure , For example, the network structure is limited to a tree structure .
5、 ... and 、EM Algorithm
\qquad In the previous discussion , We have always assumed that the values of all attribute variables of the training sample have been observed , The training sample is “ complete ” Of .
\qquad But in practical application, we often encounter “ Incomplete ” Training sample , For example, because the root of watermelon has fallen off , It can't be seen that “ Curl up ” still “ Be stiff ”, Of the training sample “ roots ” Unknown attribute variable value , In this kind of existence ” Not observed “ In the case of variables , Can we still estimate the model parameters ?
For the phenomenon of unknown attribute variables , We can use EM Algorithm
EM The algorithm is a powerful tool to estimate the hidden variables of parameters .
Compared with the previous formula , More Z Z Z( Implicit variable set )

EM The basic idea of algorithm : If parameter θ \theta θ It is known that , Then the optimal hidden variable can be inferred from the training data Z Z Z Value (E Step ); conversely , if Z Z Z It is known that , The parameters can be easily adjusted θ \theta θ Make maximum likelihood estimation .
6、 ... and 、 Learning materials
版权声明
本文为[A large piece of meat floss]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230903190675.html
边栏推荐
- First principle mind map
- L2-024 tribe (25 points) (and check the collection)
- dataBinding中使用include
- Talent Plan 学习营初体验:交流+坚持 开源协作课程学习的不二路径
- LeetCode396. Rotate array
- web页面如何渲染
- [Luke V0] verification environment 2 - Verification Environment components
- Research purpose, construction goal, construction significance, technological innovation, technological effect
- LLVM之父Chris Lattner:编译器的黄金时代
- 【原创】使用System.Text.Json对Json字符串进行格式化
猜你喜欢

Arbre de dépendance de l'emballage des ressources

BK3633 规格书

Please arrange star trek in advance to break through the new playing method of chain tour, and the market heat continues to rise
资源打包关系依赖树

Data visualization: use Excel to make radar chart

调包求得每个样本的k个邻居

LeetCode_DFS_中等_1254. 统计封闭岛屿的数目

GoLand debug go use - white record

2021 Li Hongyi's adaptive learning rate of machine learning

ATSS(CVPR2020)
随机推荐
Illegal character in scheme name at index 0:
Download and install bashdb
Get trustedinstaller permission
Number theory to find the sum of factors of a ^ B (A and B are 1e12 levels)
L2-024 部落 (25 分)(并查集)
Flink reads MySQL and PgSQL at the same time, and the program will get stuck without logs
Thread scheduling (priority)
Complete binary search tree (30 points)
Colorui solves the problem of blocking content in bottom navigation
OneFlow学习笔记:从Functor到OpExprInterpreter
PLC的点表(寄存器地址和点表定义)破解探测方案--方便工业互联网数据采集
L2-022 rearrange linked list (25 points) (map + structure simulation)
Multi view depth estimation by fusing single view depth probability with multi view geometry
资源打包关系依赖树
是否同一棵二叉搜索树 (25 分)
Restore binary tree (25 points)
政务中台研究目的建设目标,建设意义,技术创新点,技术效果
MySQL小练习(仅适合初学者,非初学者勿进)
Project upload part
ONEFLOW learning notes: from functor to opexprinter