当前位置:网站首页>[in-depth good article] detailed explanation of Flink SQL streaming batch integration technology (I)
[in-depth good article] detailed explanation of Flink SQL streaming batch integration technology (I)
2022-04-23 09:02:00 【Big data Institute】
Continuous output Stay tuned
Big data architecture Integration of lake and warehouse Stream batch integration offline + Real time data warehouse
Various big data solutions Various big data new technology practices
Continuous output Stay tuned
【 Collector's Edition 】 Data warehouse platform 、 Recommend system architecture selection and solution ⽅ case _ Blog of big data Institute -CSDN Blog Continuous output Please pay attention to the big data architecture Integration of lake and warehouse Stream batch integration offline + Various big data solutions for real-time data warehouse Various big data new technology practices continue to be exported Stay tuned https://blog.csdn.net/dajiangtai007/article/details/124042191?spm=1001.2014.3001.5501【 Collector's Edition 】⼤ Data center architecture and solution ⽅ case _ Blog of big data Institute -CSDN Blog _ Data center structure Continuous output Please pay attention to the big data architecture Integration of lake and warehouse Stream batch integration offline + Various big data solutions for real-time data warehouse Various big data new technology practices continue to be exported Stay tuned
https://blog.csdn.net/dajiangtai007/article/details/123692199?spm=1001.2014.3001.5501 new ⼀ generation USDP Open source Suite , Substitutable CDH Free big data suite platform and architecture selection _ Blog of big data Institute -CSDN Blog Continuous output Please pay attention to the big data architecture Integration of lake and warehouse Stream batch integration offline + Various big data solutions for real-time data warehouse Various big data new technology practices continue to be exported Stay tuned
https://blog.csdn.net/dajiangtai007/article/details/123525688?spm=1001.2014.3001.5501⼤ Data platform infrastructure and solutions ⽅ case _ Blog of big data Institute -CSDN Blog Continuous output Please pay attention to the big data architecture Integration of lake and warehouse Stream batch integration offline + Various big data solutions for real-time data warehouse Various big data new technology practices
https://blog.csdn.net/dajiangtai007/article/details/123473705?spm=1001.2014.3001.5501
【 The depth of the piece 】Flink SQL Flow batch ⼀ Detailed explanation of integrated technology ( One )
Catalog
The first 1 Chapter Flow batch system ⼀ nucleus ⼼ Concept
1.1 Flink Flow batch system ⼀ thought
1.1.1 Bounded flow and unbounded flow
1.1.2 Flink First generation architecture and problems
1.2.3 Flow batch system ⼀ Architecture improvement
1.3 Flink Flow batch system ⼀ nucleus ⼼ Concept
1.3.1 Relational algebra and stream processing
1.3.2 Understand dynamic tables and continuous queries
1.3.3 Detailed explanation of dynamic table
【 Next 】Flink SQL Flow batch ⼀ Detailed explanation of integrated technology ( Two )
The first 1 Chapter Flow batch system ⼀ nucleus ⼼ Concept
1.1 Flink Flow batch system ⼀ thought
1.1.1 Bounded flow and By incident
as everyone knows , stay Flink Batch processing is stream processing ⼀ A special case , Here's the picture :
1.1.2 Flink First generation architecture and problems
for fear of The batch and Stream processing Maintain two sets of code , Flink Community ⼀ Just trying to 【 Batch processing is stream processing ⼀ A special case 】 Under the guidance of the idea, from the underlying architecture layer ⾯ Realize flow batch system ⼀, The upper level passes through SQL Of ⽀ Hold the line ⼀ Programming model , But the whole process is tortuous , The initial architecture is as follows :
The upper layer of the above architecture SQL⽀ Not holding well , There are also many problems at the bottom :
1、 from Flink⽤ Household ⻆ degree
(1) When developing , Flink SQL⽀ Not holding well , Two at the bottom API Chin in ⾏ choice , what ⾄ Maintain two sets of code
(2) Different semantics 、 Different connector⽀ a 、 Different error recovery strategies …
(3)Table API Will also be affected by different underlying API、 Different connector And so on
2、 from Flink developer ⻆ degree
(1) Different translation processes , Different calculations ⼦ Realization 、 Different Task Of board ⾏…
(2) Code is hard to repeat ⽤
(3) Two alone ⽴ The technology stack needs more ⼈⼒ Function development slows down 、 Performance improvement becomes difficult , bug More
1.2.3 Flow batch system ⼀ Architecture improvement
o ⾥⼀ it is always Flink Faithfulness ⽤ Users and contributors ,⼀ Degrees are maintained internally ⼀ set ⾃⼰ Of Flink Yan ⽣ edition , It's called Blink, The main improvement is the flow batch system ⼀.
Bink The original idea was : Since the batch is flow ⼀ A special case , Whether it can be or not? ...?

Blink I'm doing it myself DataSet Of ⼯ do , stay Blink Donate to Apache Flink after , The community is ⼒ For Table API and SQL Integrate Blink Query optimizer and runtime. The first ⼀ Step , We will flink-table A single module reconstructs multiple ⼩ modular ( FLIP-32). This is for Java and Scala API modular 、 Optimizer 、 as well as runtime The module says , With ⼀ A clearer hierarchy and well-defined interface ⼝. 
Then , The community has expanded Blink Of planner To implement the new optimizer ⼝, So now there are two plug-in query processors to execute ⾏ Table API and SQL: 1.9 Former Flink Processor and new based on Blink The processor of . be based on Blink Our query processor provides better SQL coverage ( 1.9 complete ⽀ a TPC-H, TPC-DS Of ⽀ Hold on ⼀ Versions of the plan ) And through more ⼴ Extensive query optimization ( Cost based execution ⾏ Plan selection and more optimization rules )、 Improved code ⽣ Mechanism 、 And tuned calculations ⼦ Implementation to improve the performance of batch query . besides , be based on Blink The query processor also provides stronger ⼤ Stream processing can ⼒, Include ⼀ Some of the new features the community has been waiting for ( Such as dimension table Join, TopN, duplicate removal ) And aggregation scenarios to alleviate the optimization of data skew , And more built-in ⽤ Function of .
therefore , Flink from 1.9 Start Architecture ⻓ Like this ⼦:

1.2 Flink layered API
Although the current batch system ⼀ after ⼤ Home can pick ⽤SQL To do stream batch development , however Flink There are still different levels of API For developers to choose flexibly :

(1) The lowest level of abstraction only provides stateful flow , It passes through Process Function Embedded ⼊ To DataStream API in , So that it can be used for some specific operations ⾏ The underlying abstraction , It allows the ⽤ You can ⾃ Deal with it in a proper way ⾃⼀ Events of one or more data streams , And make ⽤⼀ To the fault-tolerant state . besides ,⽤ The user can register the event time and handle the time callback , from ⽽ Enables programs to handle complex calculations .
(2) actually ,⼤ Most should ⽤ You don't need the above underlying abstraction ,⽽ It's for nuclear ⼼API( Core APIs) Into the ⾏ Programming ,⽐ Such as DataStream API( Bounded or ⽆ Boundary flow data ) as well as DataSet API( Bounded data sets ). these API It provides a way for data processing ⽤ The building blocks of ,⽐ Such as by ⽤ Various forms of user-defined transformation ( transformations), Connect ( joins), polymerization ( aggregations), window ⼝ operation ( windows) wait . DataSet API Provides additional support for bounded data sets ⽀ a , For example, loops and iterations . these API The data type processed is in the form of class ( classes) The form of ⾃ Programming language ⾔ Indicated by .
(3)Table API Take the table as the center ⼼ Declarative programming , The tables may change dynamically ( When expressing flow data ). Table API follow ( Extended ) relational model : Table has ⼆ Dimensional data structure ( schema)( Similar to a table in a relational database ), meanwhile API To provide for ⽐ Relatively simple operation , for example select、 project、 join、 group-by、 aggregate etc. . Table API The program declaratively defines what logical operations should be performed ⾏,⽽ Not exactly how these operation codes look . Even though Table API There are many types of ⽤ Household ⾃ Defined function ( UDF) Into the ⾏ Expand , It is still not as good as nuclear ⼼API More expressive ⼒, But make ⽤ But it is more concise ( Less code ). besides ,Table API The program is running ⾏ Before, it will go through the built-in optimizer ⾏ Optimize .
(4) You can watch with DataStream/DataSet Between ⽆ Sewing switch , To allow the program to Table API And DataStream as well as DataSet Mix to make ⽤.
(5)Flink The most ⾼ The abstraction of hierarchy is SQL, be based on Apache Calcite Realization . this ⼀ Layer abstraction can be used in grammar and expression ⼒ Upper and Table API similar , But with SQL The formal expression of the query expression . SQL Abstract and Table API Close interaction , meanwhile SQL The query can be directly in Table API Execute on the defined table ⾏.
Be careful : Flink1.12 Previous version , Table API and SQL In the active development stage , There is no stream batch system ⼀ All features of , So make ⽤ You need to be careful when you
Be careful : from Flink1.12 Start , Table API and SQL It's already mature , Can be in ⽣ Put... On production ⼼ send ⽤
The picture below is Flink Table API/SQL The hold of ⾏ The process :

1.3 Flink Flow batch system ⼀ nucleus ⼼ Concept
1.3.1 Relational algebra and stream processing
Flink Provided by the upper layer Table API and SQL It's Liupi system ⼀ Of , namely ⽆ On stream processing (⽆ Boundary flow ) Batch processing (⽆ Boundary flow ), Table API and SQL All have the same meaning . We all know SQL For relational models and batch processing ⽽ Design , therefore SQL Query on stream processing ⽐ More difficult to achieve and understand , This section starts with the... Of stream processing ⼏ A special concept ⼊⼿ To help ⼤ Home understands Flink How to execute on stream processing ⾏SQL Of .
Relational algebra ( It mainly refers to the tables in the relational database ) and SQL, It's mainly for batch processing , This and stream processing one day ⽣ The estrangement of .
1.3.2 Understand dynamic tables and continuous queries
In order to make ⽤ Relational algebra (Table API/SQL), Flink lead ⼊ Dynamic table (Dynamic Tables) The concept of .
Because of stream processing ⾯ The right data is ⽆ Bounded data flow , This is the same as what we are familiar with in a relational database “ surface ” Completely different , therefore ⼀ One idea is to convert the data stream into Table, Then hold ⾏SQL operation , however SQL The hold of ⾏ The result is not ⼀ Become unchangeable ,⽽ It is constantly updated with the arrival of new data .
With the arrival of new data , Constantly update the previous results , The resulting table , stay Flink Table API Concept ⾥, It's called “ Dynamic table ”( Dynamic Tables).
Dynamic tables are Flink The flow of data Table API and SQL ⽀ Hold the nuclear ⼼ Concept . And static data representing batch data The watch is different , Dynamic tables change over time . Dynamic tables can be like static batch tables ⼀ Sample injection ⾏ Inquire about , Inquire about ⼀ Move The state table will produce ⽣ Keep searching ( Continuous Query). Continuous queries never end ⽌, And will ⽣ Become another ⼀ Dynamic tables . Inquire about ( Query) The dynamic result table will be updated continuously , To reflect its dynamic output ⼊ Changes on the table .
The figure above shows the execution of... On the data flow ⾏ Transformation diagram of data flow and dynamic table in relational query , The main steps are as follows :
1. Convert data flow to dynamic table
2. Advance on the dynamic table ⾏ Continuous query , and ⽣ Into a new dynamic table
3. ⽣ Convert to dynamic data stream
1.3.3 Detailed explanation of dynamic table
1、 Define dynamic tables
this ⾥ With ⼀ Here are schema Click event flow query to help ⼤ Scientists understand the concepts of dynamic tables and continuous queries :
In order to hold ⾏ Relationship query ,⾸ First you have to convert the data flow into a dynamic table . Click stream is shown on the left of the figure below , On the right is the dynamic table , All new events on the stream will correspond to... On the dynamic table insert operation ( except insert There are other models , after ⾯ Let's talk about it again ):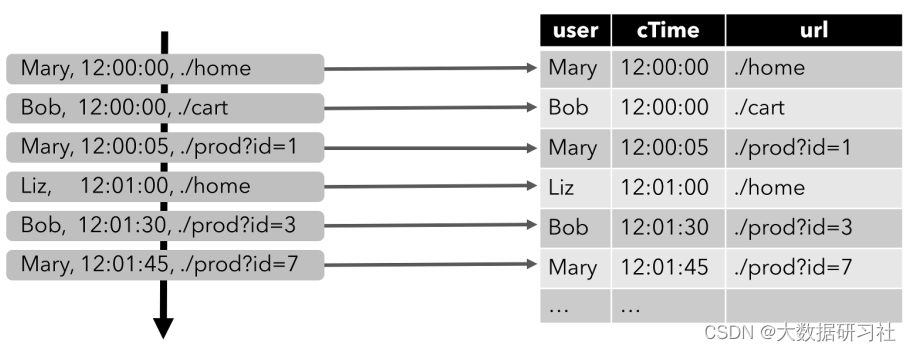
2、 Continuous query
Next , We execute on the dynamic table ⾏ Continuous query ⽣ become ⼀ A new dynamic table ( Result sheet ), Continuous query will not stop ⽌, It will lose according to ⼊ With the arrival of new data, constantly query, calculate and update the result table ( Multi mode , after ⾯ speak ).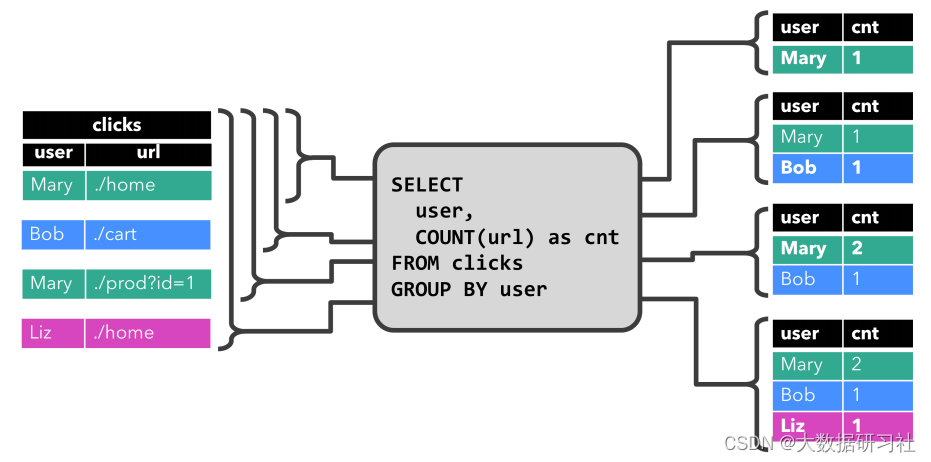
In the diagram above , We are click Dynamic table execution ⾏ 了 group by count Aggregate query , Over time , The dynamic result table on the right follows the left measurement ⼊ Table the change of each data ⽽ change .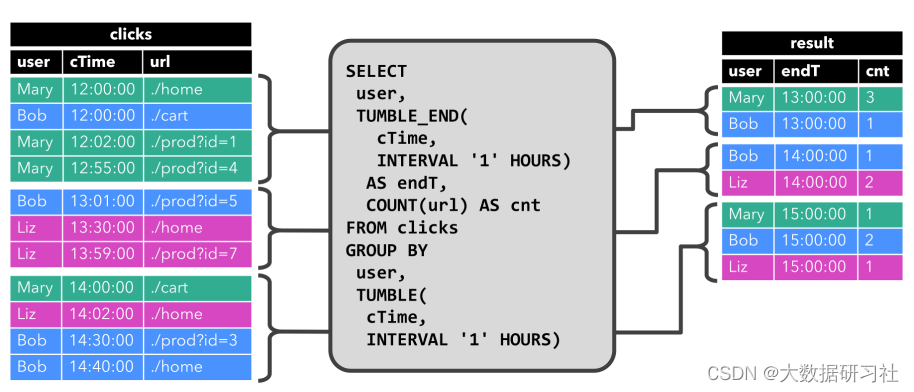
The picture above is a little complicated ⼀ some , group by count polymerization , Plus ⼊ 了 ⼀ A rolling window ⼝, Statistics 1⼩ Roll the window ⼝ Each inside ⽤ Number of visits by users . Over time , The dynamic result table on the right follows the left measurement ⼊ Table of changes in ⽽ change , But every window ⼝ The result is ⽴ Of , And the calculation is in each window ⼝ Triggered at the end .
3、 Convert dynamic table to data flow
With regular database tables ⼀ sample , Dynamic tables can be inserted by ⼊( Insert)、 to update ( Update) And delete ( Delete) change , Into the ⾏ Continuous modification . Convert a dynamic table to a stream or write it to ⼊ External system , These need to be improved ⾏ Ed code . Flink Of Table API and SQL ⽀ Hold three ⽅ More improvement of dynamic table ⾏ code :
1) Just append the stream (Append-only stream, namely insert-only)
Only by inserting ⼊INSERT Change to modify the dynamic table , It can be converted directly to “ Just add ” flow . The data sent out in this flow is each new data in the dynamic table ⼀ Events .
2) Withdrawal flow (Retract stream)
insert ⼊、 to update 、 Delete all ⽀ The held dynamic table will be converted to the withdrawal stream .
The withdrawal flow contains two types of messages : add to ( Add) Messages and withdrawals ( Retract) news .
Dynamic tables can be used to INSERT Encoded as add news 、 DELETE Encoded as retract news 、 UPDATE The code is changed ⾏( Before change ) Of retract After messages and updates ⾏( new ⾏) Of add news , Convert to retract flow .
The following figure shows how to convert a dynamic table to Retract The process of flow :

3) Update insert ⼊ flow (Upsert flow )
Upsert Flows contain two types of messages : Upsert News and delete news . Convert to upsert Dynamic table of flows , Need to have only ⼀ Key ( key).
By way of INSERT and UPDATE Change the code to upsert news , take DELETE Change the code to DELETE news , Can have only ⼀ key ( Unique Key) Dynamic table to stream .
The following figure shows how to convert a dynamic table to upsert The process of flow :

4、 Query restrictions
Yes ⽆ Bound data flows into ⾏ Continuous queries will have ⼀ Some restrictions , There are mainly the following two ⽅⾯:
(1) state ⼤⼩ Limit
⽆ Continuous queries on bounded data streams need to be run ⾏ Weeks or weeks ⽉ what ⾄ more ⻓, therefore , The amount of data processed by continuous queries may be very large ⼤. for example , front ⾯ Calculation ⽤ Example of user visits ⼦ in , Need to maintain ⽤ Count status of user visits , If only registered ⽤ The user's status will not be too ⼤, If for each ⾮ register ⽤ Account allocation only ⼀ Of ⽤ Account name , Just maintenance ⾮ often ⼤ The state of , Over time, it may cause the query to fail .

(2) Calculate update cost limit
Some queries only add or update ⼀ One lost ⼊ Record , It also needs to be recalculated and updated ⼤ Partially issued results ⾏. Such queries are not suitable for continuous queries ⾏. For example, next ⾯ That example ⼦, It is based on the last ⼀ The time of each click is ⽤ Account calculation ⼀ individual RANK. ⼀ Dan clicks Table received new ⾏,⽤ Household lastAction Will update and calculate the new ranking . however , Because of two ⾏ Cannot have the same ranking , All the lower ranking ⾏ It also needs to be updated .

【 Next 】Flink SQL Flow batch ⼀ Detailed explanation of integrated technology ( Two )
Continuous output Stay tuned
Big data architecture Integration of lake and warehouse Stream batch integration offline + Real time data warehouse
Various big data solutions Various big data new technology practices
Continuous output Stay tuned
版权声明
本文为[Big data Institute]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230723184733.html
边栏推荐
- Is Zhongyan futures safe and reliable?
- 求简单类型的矩阵和
- 在sqli-liabs学习SQL注入之旅(第十一关~第二十关)
- Use of Arthas in JVM tools
- Strength comparison vulnerability of PHP based on hash algorithm
- Illegal character in scheme name at index 0:
- Flink同时读取mysql与pgsql程序会卡住且没有日志
- Latex mathematical formula
- Idea is configured to connect to the remote database mysql, or Navicat fails to connect to the remote database (solved)
- Common errors of VMware building es8
猜你喜欢

Bk3633 specification

Introduction to GUI programming swing

Harbor enterprise image management system

Production practice elk

深度学习框架中的自动微分及高阶导数

Learn SQL injection in sqli liabs (Level 11 ~ level 20)

Share the office and improve the settled experience

Multi view depth estimation by fusing single view depth probability with multi view geometry

資源打包關系依賴樹

1099 establish binary search tree (30 points)
随机推荐
Arbre de dépendance de l'emballage des ressources
L2-3 浪漫侧影 (25 分)
Flash project cross domain interception and DBM database learning [Baotou cultural and creative website development]
MySQL查询两张表属性值非重复的数据
Trc20 fund collection solution based on thinkphp5 version
Go language self-study series | golang structure as function parameter
Valgrind and kcache grind use run analysis
Flink reads MySQL and PgSQL at the same time, and the program will get stuck without logs
Illegal character in scheme name at index 0:
Introduction to matlab
js 原型链的深入
Judgment on heap (25 points) two insertion methods
[58] length of the last word [leetcode]
MYCAT configuration
Research purpose, construction goal, construction significance, technological innovation, technological effect
Notes on xctf questions
K210 learning notes (II) serial communication between k210 and stm32
OneFlow学习笔记:从Functor到OpExprInterpreter
[boutique] using dynamic agent to realize unified transaction management II
Whether the same binary search tree (25 points)