当前位置:网站首页>注意力模型---Attention Model
注意力模型---Attention Model
2022-08-10 13:36:00 【OPTree412】
注意力模型---Attention Model
1、Soft Attention Mode
1.1 什么是Soft Attention Mode
“Neural machine translation by jointly learning to align and translate”这篇论文提出了soft Attention Model,并将其应用到了机器翻译上面。所谓Soft意思是在求注意力分配概率分布的时候,对于输入句子X中任意一个单词都给出个概率,是个概率分布。
1.1 公式介绍
下面介绍一下理论文中提到的公式
在原版的Seq2Seq和添加了attention机制的Seq2Seq相比,在公式上的差别就是在式子Si中的C有没有i。因为这个i就代表了是不是每一个时间步骤上添加不同的背景向量。
Global Attention Mode其实就是softAttention Mode。在Seq2Seq的Decoder的过程中,每一个时间步的Context vector需要计算Encoder中每一个单词的注意力权重,然后加权得到。
Si代表每个Decoder的隐藏层输出
Ci表示的是背景向量,它可以由Encoder的隐藏层输出状态hj的加权平均数得出,其中状态所加的权就是注意力权重 ai。
**注意力权重 ai**可以看出就是一个softmax,用来归一化隐藏层si-1 与 Encoder的隐藏层输出状态hj的对齐程度评估。
eij是一种对齐模式,也就是注意力函数,这当中有着很多的变体。下面来看看这四种变体都有什么。
2、四种注意力中的打分函数
2.1 加性注意力(additive attention)
加性注意力是最经典的注意力机制 (Bahdanau et al., 2015) ,它使用了全连接层来计算注意力的分配:
其中,Pi表示Decoder的隐藏层输出;q表示Encoder所有的隐藏层输出;V,W,U都是可以训练的参数。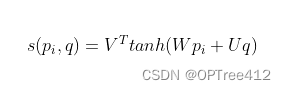
加性模型引入了可学习的参数,将向量 p p p和原始输入向量 q q q 映射到不同的向量空间后进行计算打分,显然相较于加性模型,点积模型具有更好的计算效率。
2.2 点积注意力(multiplicative attention)与双线性注意力(MLB)
乘法注意力(Multiplicative attention)(Luong et al., 2015) 通过计算以下函数而简化了注意力操作,是直接用Decoder的hidden state 点乘所有的Encoder的hidden state。
其中,ht是decoder中前一个隐藏层输出的结果;hs是encoder中所有的hidden state组合成的矩阵。
上面第一个公式有一个缺陷, ht的行数和hs的行数必须是相等的,也就要使得encoder和decoder的隐藏层长度是一样的,这样的条件太苛刻了,当不相等的时候公式便不可行,所以采用在中间加上权重矩阵的做法。
2.3 缩放点积模型
注意力机制不仅能用来处理编码器或前面的隐藏层,它同样还能用来获得其他特征的分布,例如阅读理解任务中作为文本的词嵌入 (Kadlec et al., 2017)。然而,注意力机制并不直接适用于分类任务,因为这些任务并不需要情感分析(sentiment analysis)等额外的信息。在这些模型中,通常我们使用 LSTM 的最终隐藏状态或像最大池化和平均池化那样的聚合函数来表征句子。
其中 q q q是Decoder的隐藏层输出, h h h是encoder中所有的hidden state组合成的矩阵。 D D D为输入向量的维度。
当输入向量的维度比较高的时候,点积模型通常有比较大的方差,从而导致Softmax函数的梯度会比较小。因此,缩放点积模型通过除以一个平方根项来平滑分数数值,也相当于平滑最终的注意力分布,缓解这个问题。
3、注意力变体
3.1 硬性注意力机制
直接从输入句子里面找到某个特定的单词,然后把目标句子单词和这个单词对齐,而其它输入句子中的单词硬性地认为对齐概率为0,这就是Hard Attention Model的思想。Hard AM在图像里证明有用,但是在文本里面用处不大,因为这种单词一一对齐明显要求太高,如果对不齐对后续处理负面影响很大。
3.2 自注意力(Self-Attention)
关键值注意力 (Daniluk et al., 2017) 是最近出现的注意力变体机制,它将形式和函数分开,从而为注意力计算保持分离的向量。它同样在多种文本建模任务 (Liu & Lapata, 2017) 中发挥了很大的作用。
具体来说,关键值注意力将每一个隐藏向量 hi 分离为一个键值 ki 和一个向量 vi:[ki;vi]=hi。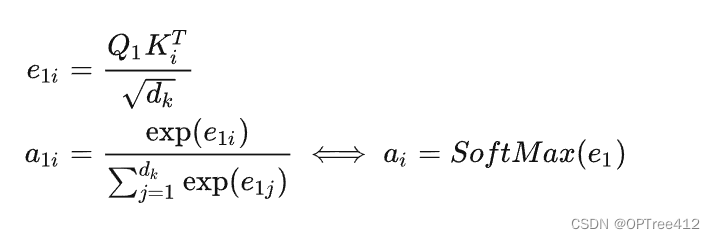

4、Attention 带来的算法改进
Attention机制为机器翻译任务带来了曙光,具体来说,它能够给机器翻译任务带来以下的好处:
- Attention显著地提高了翻译算法的表现。它可以很好地使Decoder网络注意原文中的某些重要区域来得到更好的翻译。
- Attention解决了信息瓶颈问题。原先的Encoder-Decoder网络的中间状态只能存储有限的文本信息,现在它已经从繁重的记忆任务中解放出来了,它只需要完成如何分配注意力的任务即可。
- Attention减轻了梯度消失问题。Attention在网络后方到前方建立了连接的捷径,使得梯度可以更好的传递。
- Attention提供了一些可解释性。通过观察网络运行过程中产生的注意力的分布,我们可以知道网络在输出某句话时都把注意力集中在哪里;而且通过训练网络,我们还得到了一个免费的翻译词典(soft alignment)!还是如下图所示,尽管我们未曾明确地告诉网络两种语言之间的词汇对应关系,但是显然网络依然学习到了一个大体上是正确的词汇对应表。
边栏推荐
- 网络安全——XSS之被我们忽视的Cookie
- Have you guys encountered this problem?MySQL 2.2 and 2.3-SNAPSHOT are like this, it seems to be
- A can make large data clustering method of 2000 times faster, don't poke
- I would like to ask the big guys, how to solve this error when cdc oracle initializes a 3 million table task running
- 【量化交易行情不够快?】一文搞定通过Win10 wsl2 +Ubuntu+redis+pickle实现股票行情极速读写
- 系统的安全和应用(不会点安全的东西你怎么睡得着?)
- 作业
- 每个月工资表在数据库如何存储?求一个设计思路
- Open source SPL wipes out tens of thousands of database intermediate tables
- DNS欺骗-教程详解
猜你喜欢

M²BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
记录几道整型提升的题目
作业8.9 构建TCP协议的服务器
3DS MAX 批量导出文件脚本 MAXScript 带界面
![ArcMAP has a problem of -15 and cannot be accessed [Provide your license server administrator with the following information:Err-15]](/img/da/b49d7ba845c351cefc4efc174de995.png)
ArcMAP has a problem of -15 and cannot be accessed [Provide your license server administrator with the following information:Err-15]
Send a post request at the front desk can't get the data
Stream通过findFirst()查找满足条件的一条数据

Open Office XML 格式里如何描述多段具有不同字体设置的段落

DNS欺骗-教程详解

重要通知 | “移动云杯”算力网络应用创新大赛初赛延期!!
随机推荐
【JS高级】ES5标准规范之创建子对象以及替换this_10
Error: Rule can only have one resource source (provided resource and test + include + exclude)
每个月工资表在数据库如何存储?求一个设计思路
The basic components of Loudi plant cell laboratory construction
YTU 2295: KMP模式匹配 一(串)
递归递推之Fighting_小银考呀考不过四级
BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection 论文笔记
OTA自动化测试解决方案---整体方案介绍
NAACL 2022 | 简单且高效!随机中间层映射指导的知识蒸馏方法
力扣解法汇总640-求解方程
[Study Notes] Persistence of Redis
Network Saboteur
C#实现访问OPC UA服务器
“Oracle 封禁了我的账户”
LeetCode·每日一题·640.求解方程·模拟构造
PHP 判断文件是否有内容,没有内容则复制另一个文件写入
Stream通过findFirst()查找满足条件的一条数据
Cloud Migration Practice of Redis
data product manager
3DS MAX batch export file script MAXScript with interface