当前位置:网站首页>re正则表达式
re正则表达式
2022-04-23 17:58:00 【name_qgy】
re正则表达式
正则表达式是一个特殊的字符序列,能帮助用户检查一个字符串是否与某种模式匹配,从而达成快速检索或替换某个模式、规则的文本。等同于Word中的查找和替换功能。
import re
text='178,168,123456,9537,123456'
print(re.findall('123456',text))
#Out:
['123456', '123456']
1 认识正则表达式
| 正则字符 | 描 述 |
|---|---|
| . | 匹配除"\n"之外的任何单个字符。范围最广。要匹配包括’\n’在内的任意字符,可使用’[.\n]'模式 |
| \d | 匹配一个数字字符,等价于[0-9] |
| \D | 匹配一个非数字字符,等价于[^0-9] |
| \s | 匹配任意空白字符,包括空格、制表符、换页符等,等价于[\f\n\r\t\v] |
| \S | 匹配非空白字符,等价于[^\f\n\r\t\v] |
| \w | 匹配包括下划线的任意单词数字字符,等价于[A-Za-z0-9_] |
| \W | 匹配任意非单词、数字、下划线字符,等价于[^A-Za-z0-9_] |
| 正则字符 | 描 述 |
|---|---|
| [Pp]ython | 匹配Python或python |
| rub[ye] | 匹配ruby或rube |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任意数字,等价于[0123456789] |
| [a-z] | 匹配任意小写字母 |
| [A-Z] | 匹配任意大写字母 |
| [a-zA-Z0-9] | 匹配任意字母及数字 |
| [^aeiou] | 匹配除aeiou字母之外的所有字符 |
| [^0-9] | 匹配除数字之外的所有字符 |
import re
text='身高:180,体重:130,学号:123456,密码:9537'
print(re.findall(r'\d',text))
print(re.findall(r'\S',text))
print(re.findall(r'\w',text))
print(re.findall(r'[1-5]',text))
print(re.findall(r'[高重]',text))
#Out:
['1', '7', '8', '1', '6', '8', '1', '2', '3', '4', '5', '6', '9', '5', '3', '7']
['身', '高', ':', '1', '7', '8', ',', '体', '重', ':', '1', '6', '8', ',', '学', '号', ':', '1', '2', '3', '4', '5', '6', ',', '密', '码', ':', '9', '5', '3', '7']
['身', '高', '1', '7', '8', '体', '重', '1', '6', '8', '学', '号', '1', '2', '3', '4', '5', '6', '密', '码', '9', '5', '3', '7']
['1', '1', '1', '2', '3', '4', '5', '5', '3']
['高', '重']
| 正则字符 | 描 述 |
|---|---|
| * | 0或多个 |
| + | 1或多个 |
| ? | 0或1个 |
| {2} | 2个 |
| {2,5} | 2-5个 |
| {2,} | 至少2个 |
| {,5} | 至多5个 |
text = "my telephone number is 15951817010,and my hometown's telephone \
number is 13863417300,my landline number is 0634-5608603."
print(re.findall(r'\d{4}-\d{7}(?#找座机号码)', text))
#Out:
['0634-5608603']
| 组合的正则范例 | 描 述 |
|---|---|
| \d{6}[a-z]{6} | 两个子模式拼在一起组成一个大模式,匹配6个数字加6个小写字母 |
| \d{6}|[a-z]{6} | 用竖线表示前后两个模式有一个匹配即可,匹配6个数字或者6个小写字母 |
| (abc){3} | 用小括号表示分组,分组后可以以组为单位应用量词,匹配abcabcabc |
| \X | 匹配第X个匹配到的组 |
| (?#…) | 注释 |
###\X
text="aabbcc ddfgkk oaddww aaaaaa ababcc"
print(re.findall(r'(\w{2})(\1)',text))
print(re.findall(r'(\w{2})(\1)(\2)',text))
#Out:
[('aa', 'aa'), ('ab', 'ab')]
[('aa', 'aa', 'aa')]
###(?#...)
text = "my telephone number is 15951817010,and my hometown's telephone \
number is 13863417300,my landline number is 0634-5608603."
print(re.findall(r'\d{4}-\d{7}(?#找座机号码)', text))
#Out:
['0634-5608603']
| 正则字符 | 描 述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果存在换行,就只匹配到换行前的结束字符串 |
| \b | 匹配单词边界,也就是单词和空格间的位置。例如:er\b 可以匹配never中的er,但不能匹配verb中的er |
| \B | 匹配非单词边界。例如:er\B可以匹配verb中的er,但不能匹配never中的er |
| (?=…) | 匹配的内容在…之前 |
| (?!..) | 匹配的内容不在…之前 |
| (?<=…) | 匹配的内容在…之后 |
| (?<!..) | 匹配的内容不在…之后 |
###(?=...)
text="height:180,weight:63,student_num:2020802178,key:hello_world"
print(re.findall(r'\w+(?=:2020802178)',text))
#Out:
['student_num']
###(?<=...)
print(re.findall(r'(?<=key:)\w+',text))
#Out:
['hello_world']
正则表达式的内容博大精深,可以先掌握基础的框架,知道有哪些东西,必要时再深入的去探索,我觉得这是学习新知识、了解新事物的比较高效的学习方法。就像是学习一门新的学科,不需要将该学科的经典书目一字不漏地背锅,仅需掌握核心的内容,在脑海中形成网络,当需要用到这张网的某一处时再去细究他。
2 re模块
python的re模块,包括8个方法:
- re.search():查找符合模式的字符,只返回第一个,返回Match对象
- re.match():和search一样,但要求必须从字符串开头匹配,返回Match对象
- re.findall():返回所有匹配的字符串列表
- re.finditer():返回一个迭代器,其中包含所有的匹配,也就是Match对象
- re.sub():替换匹配的字符串,返回替换完成的文本
- re.subn():替换匹配的字符串,返回替换完成的文本和替换的次数
- re.split():用匹配表达式的字符串做分隔符分割原字符串
- re.compile():把正则表达式编译成一个对象,方便后面使用
以上8个方法按照功能不同可以划分为4列,分别是查找,替换,分割和编译。
2.1 查找,有4个方法:search、match、findall、finditer
2.1.1 search - 只返回1个
import re
text = "abc,Abc,aBC,abc"
print(re.search(r'abc',text))
#Out:
<re.Match object; span=(0, 3), match='abc'>
search方法是返回了一个Match对象,且仅返回了一个值,span=(0,3) 的意思是匹配到了第1-3个字符,如何从Match对象中拿到匹配的值呢,需要用到group方法。
import re
text = "abc,Abc,aBC,abc"
m = re.search(r'abc', text)
print(m.group())
#Out:
abc
group方法在不给定参数的情况下返回值是匹配的结果。
如果将匹配的值进行分组,就可以通过group方法传入第几组的参数,输出的结果是第几组匹配的结果。
text = "name:qgy,score:99;name:myt,score:98"
m = re.search(r'(name):(\w{3})',text)
print(m.group())
print(m.group(1))
print(m.group(2))
print(m.groups())
#Out:
name:qgy
name
qgy
('name', 'qgy')
在此补充一个知识点,查找的这四个方法有三个参数,之前的部分仅用到了前两个,就以re.search()方法为例,
re.search(pattern,string,flags=0)
第一个参数pattern是指匹配的模式,第二个参数string是指要匹配的字符串,flags是标志位,用于控制正则表达式的匹配方式,如:是否区分大小写、多行匹配等。
text = "aBc,Abc,aBC,abc"
m = re.search(r'abc', text, flags=re.I)
print(m.group())
#Out:
aBc
上方正则中,我想要匹配的是abc,text中不存在abc,匹配的结果是aBc。
也就是说,re.I的作用是不区分大小写。
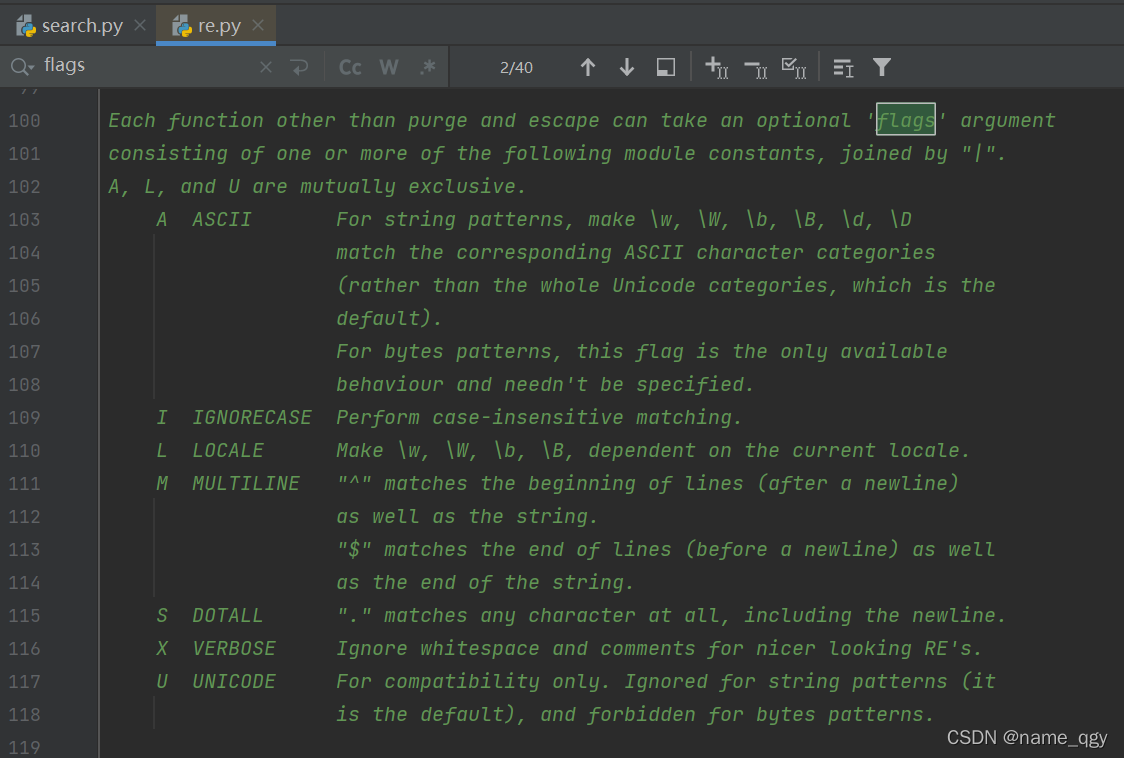
想要查找flags有哪些,可以按住ctrl键点一下自己脚本中的re出现的位置,就会弹出re.py文件,在该文件下按住ctrl+F,弹出查找框,输入flags就能看到flags有哪些参数了。
2.1.2 match - 也是只返回1个,但是从头开始匹配
text = "xaBc,Abc,aBC,abc"
m = re.match(r'abc', text, flags=re.I)
n = re.search(r'^abc',text,flags=re.I)
print(m)
print(n)
#Out:
None
None
上方代码中,我将aBc前添加了x,使用match方法,匹配text开始的字符,如果开始的字符不符合正则表达式,匹配就会失败,返回的结果为None。
re.match(r’‘,text) 等价于 re.search(r’^',text)
说实话,match没啥用,设计这个match给人画蛇添足的感觉,用search就足够了
2.1.3 findall - 返回所有匹配的字符串
text = "name:qgy,score:99;name:myt,score:98"
m = re.findall(r'(name):(\w{3})',text)
print(m)
#Out:
[('name', 'qgy'), ('name', 'myt')]
findall方法返回一个列表,匹配时如果有分组的话,列表中每一个值会用()括起来,不同的组之间用 ‘,’ 分割。
2.1.4 finditer - 返回Match迭代器
text = "name:qgy,score:99;name:myt,score:98"
m = re.finditer(r'(name):(\w{3})',text)
print(m)
for i in m:
print(i)
#Out:
<callable_iterator object at 0x00000224C3D5A460>
<re.Match object; span=(0, 8), match='name:qgy'>
<re.Match object; span=(18, 26), match='name:myt'>
finditer是返回一个迭代器,迭代器是啥我不懂,我估计我也用不着,就暂时不花时间精力去整理了。这一块就春秋笔法一笔带过了。
查找功能的4个方法中,search、match和finditer都是返回一个Match对象,可以掌握最基础的findall和search,找全部就用findall,找一个用search。
2.2 替换,有2个方法:sub、subn
替换的这两个方法与前面查找的四个方法仅有一处不同,多了个参数,即需要指明想要替换的字符是什么。
2.2.1 sub - 是英语单词substitute的英文缩写
text="abc,aBc,ABc,xyz,opq"
result=re.sub(r'abc','xyz',text,flags=re.I)
print(result)
#Out:
xyz,xyz,xyz,xyz,opq
2.2.2 subn - 替换完成后告诉我有几个字符被替换掉了
text="abc,aBc,ABc,xyz,opq"
result=re.subn(r'abc','xyz',text,flags=re.I)
print(result)
#Out:
('xyz,xyz,xyz,xyz,opq', 3)
2.3 分割
split方法是将某个字符串按照一定的规则拆分成一些些小字符串。
split有什么用呢?举个例子,我有一个序列,我用限制性内切酶对该序列进行酶切,将原来的序列切割成一些小片段,想要知道切割后小片段的序列信息,就可以通过split方法来实现。
MobI = "GATC"
text = "ATCGATCGGTTTAAGATCCTTCG"
result = re.split(MobI, text, flags=re.I)
print(result)
#Out:
['ATC', 'GGTTTAA', 'CTTCG']
2.4 编译
compile方法是将一个正则表达式作为一个可以传达的对象,将该对象传到别的方法里也就可以用它,去做search、findall等等。
为什么要有编译呢,利用编译方法的好处是提高效率,如果一个正则表达式要重复使用成千上百次,每次匹配都要手动输入一遍岂不是非常麻烦,有了编译的结果,重复使用时就直接调用了。
re_telephone=re.compile(r'\d{4}-\d{3,8}')
text1="Xiao ming's telephone number is 0634-4854481"
text2="Xiao hone's telephone number is 0531-145488454"
text3="Xiao gang's telephone number is 0452-567188155"
print(re_telephone.search(text1).group())
print(re_telephone.search(text2).group())
print(re_telephone.search(text3).group())
#Out:
0634-4854481
0531-14548845
0452-56718815
版权声明
本文为[name_qgy]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_50637636/article/details/124277690
边栏推荐
- Vite configure proxy proxy to solve cross domain
- Thirteen documents in software engineering
- 2022 Jiangxi Photovoltaic Exhibition, China Distributed Photovoltaic Exhibition, Nanchang Solar Energy Utilization Exhibition
- ES6 face test questions (reference documents)
- Classification of cifar100 data set based on convolutional neural network
- 2022江西储能技术展会,中国电池展,动力电池展,燃料电池展
- Examination question bank and online simulation examination of the third batch (main person in charge) of special operation certificate of safety officer a certificate in Guangdong Province in 2022
- Listen for click events other than an element
- Data stream encryption and decryption of C
- cartographer_ There is no problem compiling node, but running the bug that hangs directly
猜你喜欢

On the problem of V-IF display and hiding

C#的随机数生成
Auto. JS custom dialog box

JS parsing and execution process
Applet learning notes (I)
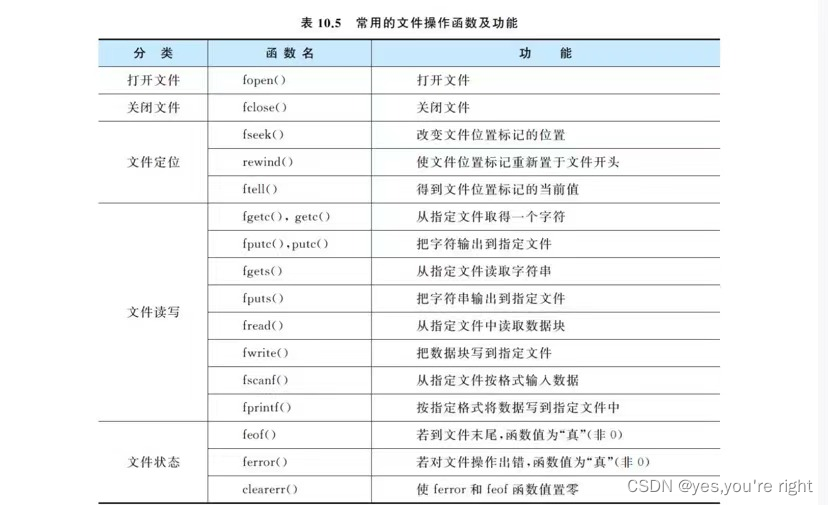
Using files to save data (C language)
Anchor location - how to set the distance between the anchor and the top of the page. The anchor is located and offset from the top
YOLOv4剪枝【附代码】

Nat Commun|在生物科学领域应用深度学习的当前进展和开放挑战

Implementation of image recognition code based on VGg convolutional neural network
随机推荐
Summary of common server error codes
2022年流动式起重机司机国家题库模拟考试平台操作
2022 judgment questions and answers for operation of refrigeration and air conditioning equipment
Gets the time range of the current week
This point in JS
20222 return to the workplace
Remember using Ali Font Icon Library for the first time
Gaode map search, drag and drop query address
2022 Jiangxi Photovoltaic Exhibition, China distributed Photovoltaic Exhibition, Nanchang solar energy utilization Exhibition
Tensorflow tensor introduction
Clion installation tutorial
I/O多路复用及其相关详解
Welcome to the markdown editor
31. Next arrangement
.104History
String function in MySQL
Nat commun | current progress and open challenges of applied deep learning in Bioscience
Write a regular
JS interview question: FN call. call. call. Call (FN2) parsing
Element calculation distance and event object