当前位置:网站首页>对比学习系列(三)-----SimCLR
对比学习系列(三)-----SimCLR
2022-08-11 08:11:00 【陶将】
SimCLR
SimCLR通过隐藏空间的对比损失最大化相同数据在不同增广下的一致性来学习表达。SimCLR框架有四个主要的组件,分别是:数据增广,encode网络,projection head网络和对比学习函数。
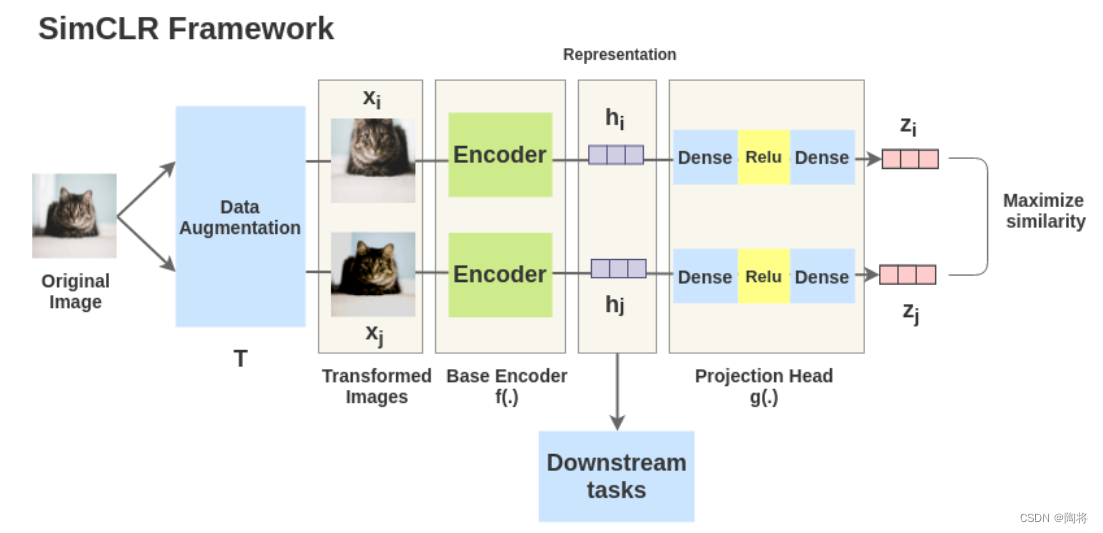
对于数据 x x x,从同一个数据增广族中抽取两个独立的数据增广算子( t ∼ T t \sim T t∼T和 t ′ ∼ T {t}' \sim T t′∼T),以获得两个相关的视图 x ^ i \hat{x}_{i} x^i和 x ^ j \hat{x}_{j} x^j, x ^ i \hat{x}_{i} x^i和 x ^ j \hat{x}_{j} x^j是一对正样本,然后一个神经网络编码器 f ( ⋅ ) f\left( \cdot \right) f(⋅)从增广的数据中提取特征 h i = f ( x ^ i ) , h j = f ( x ^ j ) , h_{i}=f\left( \hat{x}_{i} \right), h_{j}=f\left( \hat{x}_{j} \right), hi=f(x^i),hj=f(x^j),。再然后一个小的神经网络project head g ( ⋅ ) g\left( \cdot \right) g(⋅)将特征映射到对比损失的空间。project head采用带有一个隐含层的MLP获取 z i = g ( h i ) = W ( 2 ) σ ( W ( 1 ) h i ) z_{i} = g\left( h_{i} \right) = W^{\left( 2 \right)} \sigma \left( W^{\left( 1 \right)} h_{i}\right) zi=g(hi)=W(2)σ(W(1)hi)。
对于包含一对正样本 x ^ i \hat{x}_{i} x^i和 x ^ j \hat{x}_{j} x^j的集合 { x ^ k } \{ \hat{x}_{k} \} { x^k},对比预测任务目的是对于给定的 x ^ i \hat{x}_{i} x^i在 { x ^ } k ≠ i \{ \hat{x} \}_{k \neq i} { x^}k=i中识别出 x ^ j \hat{x}_{j} x^j。随机挑选 N N N个样本组成一个minibatch,这个minibatch中则有 2 N 2N 2N个数据样本,将其他 2 ( N − 1 ) 2\left( N - 1\right) 2(N−1)个扩增的样本作为这个minibatch中的负样本,设 s i m ( u , v ) = u T v / ∥ u ∥ ∥ v ∥ sim\left( u, v\right) = u^{T}v / \| u\| \| v\| sim(u,v)=uTv/∥u∥∥v∥表示 l 2 l_{2} l2正则化后你的 u u u和 v v v的点积,那么对一对正样本 ( i , j ) \left( i, j \right) (i,j),损失函数如下定义:
l i , j = − l o g e x p ( s i m ( z i , z j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] e x p ( s i m ( z i , z k ) / τ ) l_{i,j} = - log \frac{exp\left( sim \left( z_{i}, z_{j}\right) / \tau \right)}{\sum_{k=1}^{2N} \mathbb{1}_{[ k \neq i]} exp\left( sim \left( z_{i}, z_{k}\right) / \tau \right)} li,j=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
最后的损失函数计算一个minibatch中的所有的正样本对,包括 ( i , j ) \left( i, j \right) (i,j)和 ( j , i ) \left( j,i \right) (j,i)。下面是SimCLR的伪代码。从伪代码中可以看出,编码器 f ( ⋅ ) f\left( \cdot \right) f(⋅)和project head g ( ⋅ ) g\left( \cdot \right) g(⋅) 在训练时都会被更新参数,但是只有编码器 f ( ⋅ ) f\left( \cdot \right) f(⋅)用于下游任务。
simCLR不采用memory bank的形式进行训练,而是加大batchsize,bacth size为8192,对于每一个正样本,将会有16382张负样本实例。增大batch size其实相当于每个minibatch时动态生成一个memory bank。论文中发现使用标准的SGD/Momentum,大batch size训练时是不稳定的,论文中采用LARS优化器。
参考
边栏推荐
猜你喜欢

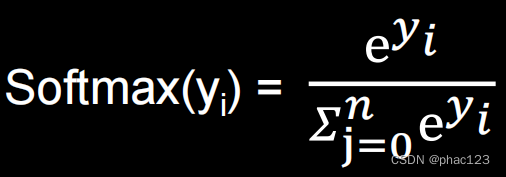
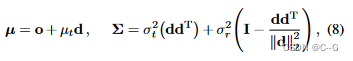


随机推荐
go sqlx 包
你有对象类,我有结构体,Go lang1.18入门精炼教程,由白丁入鸿儒,go lang结构体(struct)的使用EP06
Swagger简单使用
string类接口介绍及应用
【C语言】每日一题,求水仙花数,求变种水仙花数
The softmax function is used in TF;
麒麟V10系统打包Qt免安装包程序
C语言-结构体
Use tf.argmax in Tensorflow to return the index of the maximum value of the tensor along the specified dimension
Kotlin算法入门求自由落体
分门别类输入输出,Go lang1.18入门精炼教程,由白丁入鸿儒,go lang基本数据类型和输入输出EP03
1071 Small Gamble (15 points)
通过记账,了解当月收支情况
leetcode: 69. Square root of x
Four states of Activity
Analysys and the Alliance of Small and Medium Banks jointly released the Hainan Digital Economy Index, so stay tuned!
C语言操作符详解
JRS303-Data Verification
Item 2 - Annual Income Judgment
2.1-梯度下降