当前位置:网站首页>清华大学 | WebFace260M:百万级深度人脸识别的基准(TPAMI2022)
清华大学 | WebFace260M:百万级深度人脸识别的基准(TPAMI2022)
2022-04-23 21:44:00 【智源社区】
论文标题:WebFace260M: A Benchmark for Million-Scale Deep Face Recognition
论文链接:https://arxiv.org/abs/2204.10149
作者单位:清华大学 & 芯翌科技 & 帝国理工学院
人脸基准使研究界能够训练和评估高性能的人脸识别系统。在本文中,我们提供了一个新的百万级识别基准,包含未经处理的 4M 身份/260M 人脸 (WebFace260M) 和清洁的 2M 身份/42M 人脸 (WebFace42M) 训练数据,以及精心设计的时间约束评估协议。首先,我们收集了 4M 的名单并从 Internet 下载了 260M 的面孔。然后,设计了一种自动利用自我训练 (CAST) 的清洗管道来净化巨大的 WebFace260M,它是高效且可扩展的。据我们所知,清理后的 WebFace42M 是最大的公共人脸识别训练集,我们希望缩小学术界和工业界之间的数据差距。参考实际部署,构建了推理时间约束下的人脸识(FRUITS)协议和一个新的具有丰富属性的测试集。此外,我们收集了一个大规模的蒙面人脸子集,用于 COVID-19 下的生物特征评估。为了对人脸匹配器进行综合评估,分别在标准、蒙面和无偏设置下执行三个识别任务。借助这个基准,我们深入研究了百万级的人脸识别问题。开发了一个分布式框架来有效地训练人脸识别模型而不篡改性能。在 WebFace42M 的支持下,我们在具有挑战性的 IJB-C 集上降低了 40% 的失败率,并在 NIST-FRVT 的 430 个条目中排名第三。与公共训练集相比,即使是 10% 的数据 (WebFace4M) 也显示出卓越的性能。此外,在 FRUITS-100/500/1000 毫秒协议下建立了全面的基线。提议的基准在标准、蒙面和无偏见的人脸识别场景中显示出巨大的潜力。

版权声明
本文为[智源社区]所创,转载请带上原文链接,感谢
https://hub.baai.ac.cn/views/16625
边栏推荐
- Question brushing plan - depth first search (II)
- [leetcode refers to the two numbers of offer 57. And S (simple)]
- Some thoughts on super in pytorch, combined with code
- ERP function_ Financial management_ Basic concepts of Finance
- Keywords static, extern + global and local variables
- 小米手机全球已舍弃“MI”品牌,全面改用“xiaomi”全称品牌
- Centos7 builds MySQL master-slave replication from scratch (avoid stepping on the pit)
- Pipes and xargs
- Norm normalization in tensorflow and pytorch of records
- Sharpness difference (SD) calculation method of image reconstruction and generation domain index
猜你喜欢
airbase 初步分析
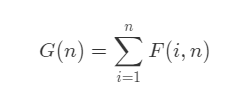
Problem brushing plan -- dynamic programming (III)
Rust更适合经验较少的程序员?

DW basic course (II)
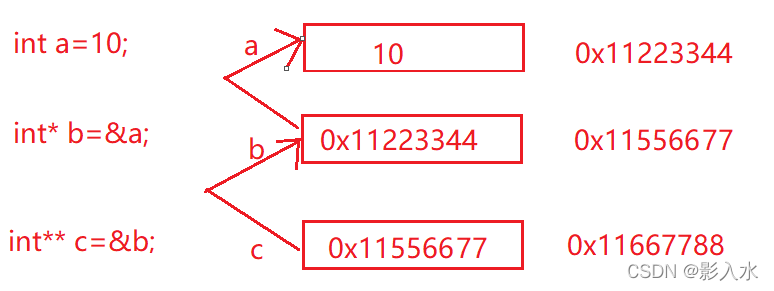
Deep analysis of C language pointer (Part I)
Is rust more suitable for less experienced programmers?

在线Excel转CSV工具

wait、waitpid
Chrome 94 introduces the controversial idle detection API, which apple and Mozilla oppose
![[leetcode refers to offer 52. The first common node of two linked lists (simple)]](/img/bc/cd9c6ec29ecfef74940200e196aed3.png)
[leetcode refers to offer 52. The first common node of two linked lists (simple)]
随机推荐
Flomo software recommendation
Norm normalization in tensorflow and pytorch of records
DeNO 1.13.2 release
[leetcode refers to offer 27. Image of binary tree (simple)]
Question brushing plan - depth first search (II)
Fastdfs mind map
ubutnu20安裝CenterNet
Preliminary analysis of Airbase
[leetcode refers to the substructure of offer 26. Tree (medium)]
Amazon and epic will be settled, and the Microsoft application mall will be opened to third parties
Sqlserver edits data in the query interface (similar to Oracle's edit and ROWID)
【SDU Chart Team - Core】SVG属性类设计之枚举
Correction of date conversion format error after Oracle adds a row total
How to use the project that created SVN for the first time
Arm architecture assembly instructions, registers and some problems
Factory mode
How to play the guiding role of testing strategy
Automatic heap dump using MBean
Ubuntu 20 installing centernet
ros功能包内自定义消息引用失败