当前位置:网站首页>Toward a Unified Model
Toward a Unified Model
2022-08-11 06:16:00 【zhSunw】
Learning Multiple Adverse Weather Removal via Two-stage Knowledge Learning and Multi-contrastive Regularization: Toward a Unified Model
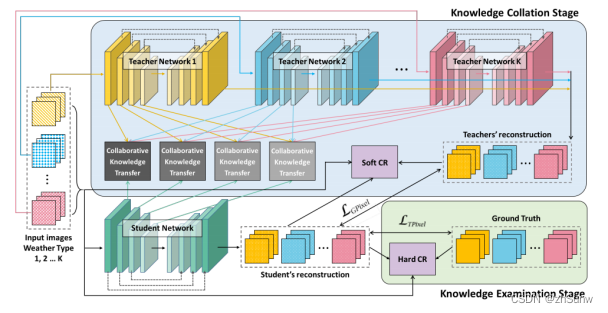
Two-stage Knowledge Learning (Collation-Examination) is designed on the basis of knowledge ledgedistillation and the method of contrastive learning is introduced.
Method
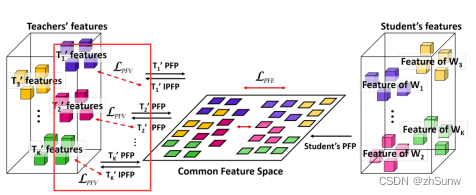
Collaborative Knowledge Transfer (CKT)
Progressive Feature Projector (PFP)
Project the features of the teacher and student networks into a common feature space, and calculate the L1 loss of the two projected features: Q represents the number of coding layers, Ti represents the ith teacher network, and S represents the student network
Projection is achieved by a small network consisting of several convolutional blocks with stride 1 and a ReLU activation function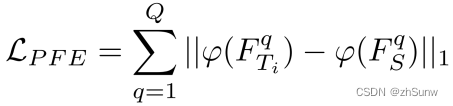
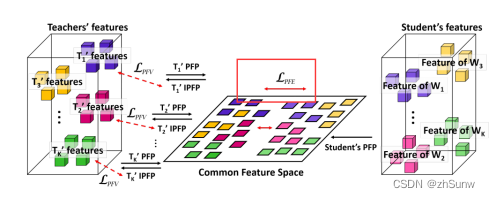
Bidirectional Feature Matching
Project the projected features of the teacher network back to the original input space, and calculate the L1 loss of the two features to ensure the validity of the projection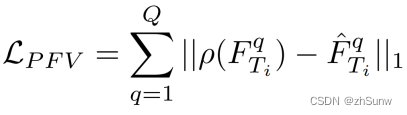
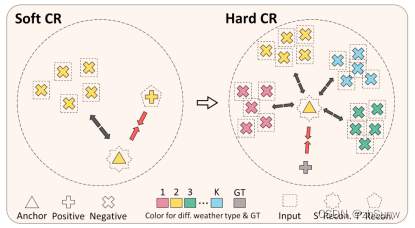
Multi-contrastive Regularization (Two-stage Knowledge Learning)
Contrastive Regularization: v, v+, v- represent predicted samples, positive samples (target samples), and negative samples respectively; Ψ represents the features extracted by VGG-19; R is the number of negative samples.
Soft Contrastive Regularization. (Knowledge Collation (KC).)
Soft: Use teacher's predictions as positive samples to avoid the challenges of early learning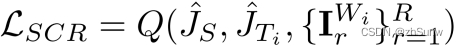
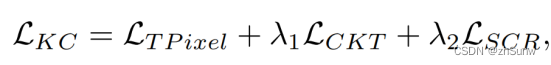
Hard Contrastive Regularization.(Knowledge Examination (KE).)
Hard: Use groundtruth as a positive sample to learn directly after training for a period of time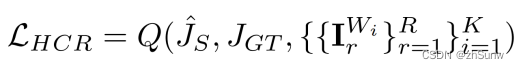
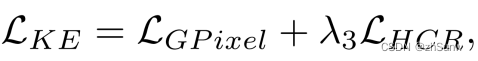
边栏推荐
猜你喜欢




随机推荐
GBase 8a 并行技术
>>技术应用:*aaS服务定义
GBase 8s 执行计划查询分析
>>数据管理:读书笔记|第一章 数据管理
智慧工地 安全帽识别系统
mysql基本概念之索引
NodeRed系列—nodered安装及基本操作
恶劣天气 3D 目标检测数据集收集
《现代密码学》学习笔记——第三章 分组密码 [三]分组密码的运行模式
Androd 基本布局(其一)
CVPR2020:Seeing Through Fog Without Seeing Fog
mysql基本概念之事务
关于安全帽识别系统,你需要知道的选择要点
经纬度距离
内核与用户空间通过字符设备通信
AIDL 简介以及使用
快照读下mvcc实现避免幻读
用正则验证文件名是否合法
IDEA本机连接远程TDengine不成功,终于配置成功
Nodered系列—使用mqtt写入国产数据库tDengine