当前位置:网站首页>Project 1 - PM2.5 Forecast
Project 1 - PM2.5 Forecast
2022-08-11 07:51:00 【A big boa constrictor 6666】
文章目录
项目1-PM2.5预测
友情提示
同学们可以前往课程作业区先行动手尝试!!!
项目描述
- The data for this work is the observation data downloaded from the Air Quality Monitoring Network of the Environmental and Environmental Protection Agency, Executive Yuan.
- Hope you all can do it in this work linear regression 预测出 PM2.5 的数值.
数据集介绍
- This operation uses the observation records of Fengyuan Station,分成 train set 跟 test set,train set It is in front of Toyohara Station every month 20 All data for the day.test set It was sampled from the remaining data at Fengyuan Station.
- train.csv: every month ago 20 full profile of the day.
- test.csv : Sampling continuations from the remaining data 10 An hour is a sum,All observations for the first nine hours are considered feature,tenth hour PM2.5 当作 answer.一共取出 240 The pen does not repeat test data,请根据 feature 预测这 240 笔的 PM2.5.
- Data 含有 18 item observation data AMB_TEMP, CH4, CO, NHMC, NO, NO2, NOx, O3, PM10, PM2.5, RAINFALL, RH, SO2, THC, WD_HR, WIND_DIREC, WIND_SPEED, WS_HR.
项目要求
- Please do it manually linear regression,The method is limited to use gradient descent.
- 禁止使用 numpy.linalg.lstsq
数据准备
无
环境配置/安装
!pip install --upgrade pandas
import sys
import pandas as pd
import numpy as np
data = pd.read_csv('work/hw1_data/train.csv', encoding = 'big5')
print(pd.__version__)
1.3.5
预处理
Take the required numeric part,将 ‘RAINFALL’ Fill all fields 0.
The following figure is the full flow chart: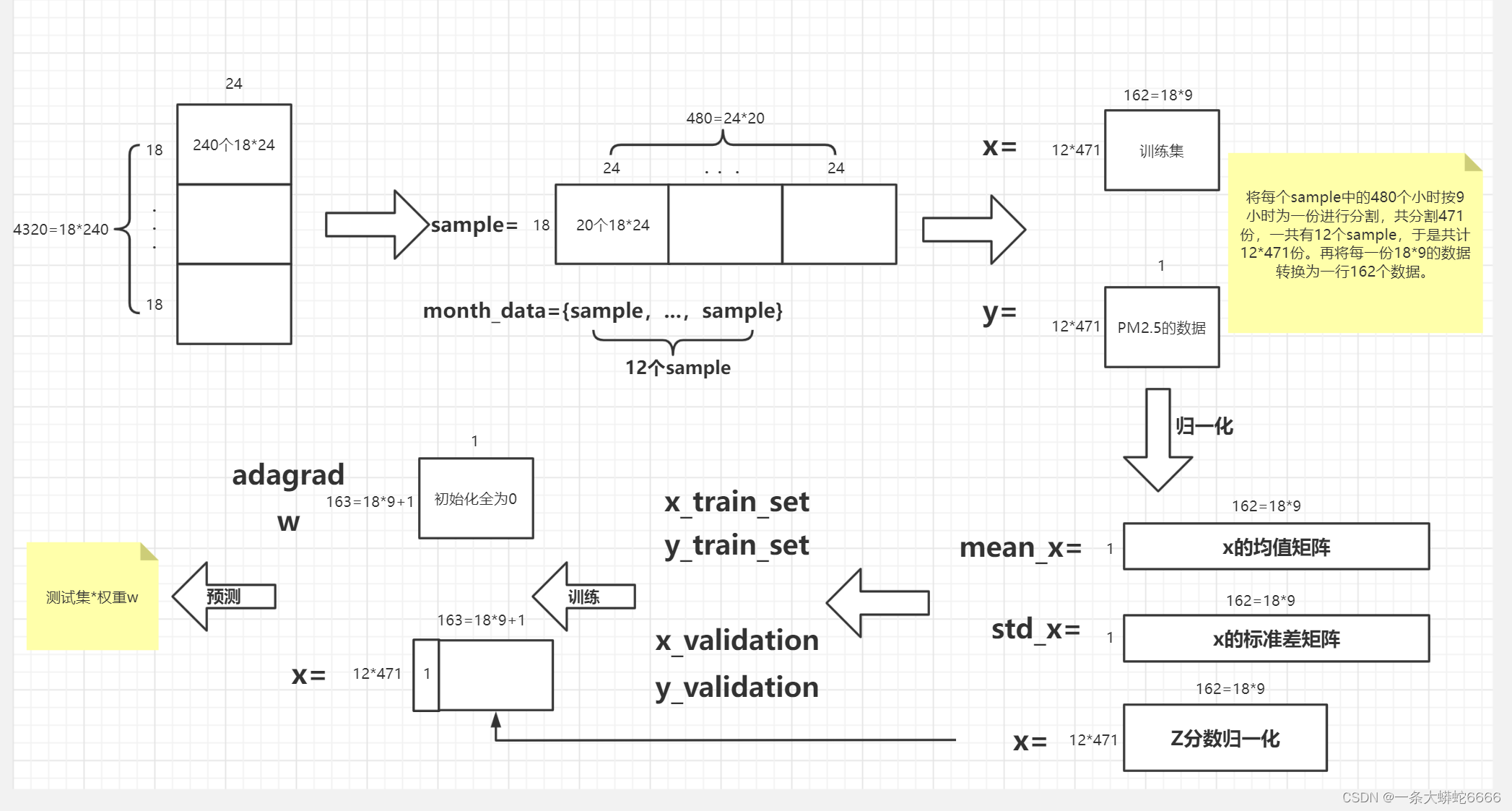
# The data form of the training set is :4320*24,每18行为1天的数据,共计4320/18=240天的数据.每天监测24小时的数据,The column number is the monitoring time at this time.
print(data.head(20))
print(data.shape)
# Remove the invalid data in the first three columns
data = data.iloc[:, 3:]
# Create column named 'NR'的列,The initial value of this column data is assigned0
data[data == 'NR'] = 0
raw_data = data.to_numpy()
日期 測站 測項 0 1 2 3 4 5 6 ... \
0 2014/1/1 Toyhara AMB_TEMP 14 14 14 13 12 12 12 ...
1 2014/1/1 Toyhara CH4 1.8 1.8 1.8 1.8 1.8 1.8 1.8 ...
2 2014/1/1 Toyhara CO 0.51 0.41 0.39 0.37 0.35 0.3 0.37 ...
3 2014/1/1 Toyhara NMHC 0.2 0.15 0.13 0.12 0.11 0.06 0.1 ...
4 2014/1/1 Toyhara NO 0.9 0.6 0.5 1.7 1.8 1.5 1.9 ...
5 2014/1/1 Toyhara NO2 16 9.2 8.2 6.9 6.8 3.8 6.9 ...
6 2014/1/1 Toyhara NOx 17 9.8 8.7 8.6 8.5 5.3 8.8 ...
7 2014/1/1 Toyhara O3 16 30 27 23 24 28 24 ...
8 2014/1/1 Toyhara PM10 56 50 48 35 25 12 4 ...
9 2014/1/1 Toyhara PM2.5 26 39 36 35 31 28 25 ...
10 2014/1/1 Toyhara RAINFALL NR NR NR NR NR NR NR ...
11 2014/1/1 Toyhara RH 77 68 67 74 72 73 74 ...
12 2014/1/1 Toyhara SO2 1.8 2 1.7 1.6 1.9 1.4 1.5 ...
13 2014/1/1 Toyhara THC 2 2 2 1.9 1.9 1.8 1.9 ...
14 2014/1/1 Toyhara WD_HR 37 80 57 76 110 106 101 ...
15 2014/1/1 Toyhara WIND_DIREC 35 79 2.4 55 94 116 106 ...
16 2014/1/1 Toyhara WIND_SPEED 1.4 1.8 1 0.6 1.7 2.5 2.5 ...
17 2014/1/1 Toyhara WS_HR 0.5 0.9 0.6 0.3 0.6 1.9 2 ...
18 2014/1/2 Toyhara AMB_TEMP 16 15 15 14 14 15 16 ...
19 2014/1/2 Toyhara CH4 1.8 1.8 1.8 1.8 1.8 1.8 1.8 ...
14 15 16 17 18 19 20 21 22 23
0 22 22 21 19 17 16 15 15 15 15
1 1.8 1.8 1.8 1.8 1.8 1.8 1.8 1.8 1.8 1.8
2 0.37 0.37 0.47 0.69 0.56 0.45 0.38 0.35 0.36 0.32
3 0.1 0.13 0.14 0.23 0.18 0.12 0.1 0.09 0.1 0.08
4 2.5 2.2 2.5 2.3 2.1 1.9 1.5 1.6 1.8 1.5
5 11 11 22 28 19 12 8.1 7 6.9 6
6 14 13 25 30 21 13 9.7 8.6 8.7 7.5
7 65 64 51 34 33 34 37 38 38 36
8 52 51 66 85 85 63 46 36 42 42
9 36 45 42 49 45 44 41 30 24 13
10 NR NR NR NR NR NR NR NR NR NR
11 47 49 56 67 72 69 70 70 70 69
12 3.9 4.4 9.9 5.1 3.4 2.3 2 1.9 1.9 1.9
13 1.9 1.9 1.9 2.1 2 1.9 1.9 1.9 1.9 1.9
14 307 304 307 124 118 121 113 112 106 110
15 313 305 291 124 119 118 114 108 102 111
16 2.5 2.2 1.4 2.2 2.8 3 2.6 2.7 2.1 2.1
17 2.1 2.1 1.9 1 2.5 2.5 2.8 2.6 2.4 2.3
18 24 24 23 21 20 19 18 18 18 18
19 1.8 1.8 1.8 1.8 1.8 1.8 1.8 1.8 1.8 1.8
[20 rows x 27 columns]
(4320, 27)
提取特征 (1)
The following figure is the full flow chart:
将原始 4320 * 18 The data is reorganized on a monthly basis 12 个 18 (特征) * 480 (小时) 的资料.
# 将原始 240天*18个特征*24小时 The data is reorganized on a monthly basis 12个月(每月20天)*18个特征*480 (小时) 的资料.
month_data = {
}
for month in range(12):
sample = np.empty([18, 480])
for day in range(20):
sample[:, day * 24 : (day + 1) * 24] = raw_data[18 * (20 * month + day) : 18 * (20 * month + day + 1), :]
month_data[month] = sample
提取特征 (2)
The following figure is the full flow chart:
There will be every month 480小时,每 9 Hours form a data,There will be every month 471 个数据,Therefore, the total number of data is 471 * 12 笔,而每笔 数据 有 9 * 18 的 特征 (一小时 18 个 特征 * 9 小时).
对应的 目标 则有 471 * 12 个(第 10 个小时的 PM2.5)
# xis the number of data in the training set12 * 471,,Every piece of data is18(特征数) * 9(小时)
x = np.empty([12 * 471, 18 * 9], dtype = float)
# yis the first in each training set data10小时的PM2.5
y = np.empty([12 * 471, 1], dtype = float)
for month in range(12):
for day in range(20):
for hour in range(24):
# Determine whether the current data is the last one of each month,That is, the first of the month19天的第15个小时.
# reshape(1, -1)Every piece of data is18(特征数) * 9(小时)的数据转换为1行数据
if day == 19 and hour > 14:
continue
x[month * 471 + day * 24 + hour, :] = month_data[month][:,day * 24 + hour : day * 24 + hour + 9].reshape(1, -1) #vector dim:18*9 (9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9 9)
y[month * 471 + day * 24 + hour, 0] = month_data[month][9, day * 24 + hour + 9] #value
print(x)
print(y)
[[14. 14. 14. ... 2. 2. 0.5]
[14. 14. 13. ... 2. 0.5 0.3]
[14. 13. 12. ... 0.5 0.3 0.8]
...
[17. 18. 19. ... 1.1 1.4 1.3]
[18. 19. 18. ... 1.4 1.3 1.6]
[19. 18. 17. ... 1.3 1.6 1.8]]
[[30.]
[41.]
[44.]
...
[17.]
[24.]
[29.]]
归一化
The following figure is the full flow chart:
# axis=0,那么输出矩阵是1行,求每一列的平均;axis=1,输出矩阵是1列,求每一行的平均
# That is to find each column12*471The mean of the pen data,然后输出一行18*9The mean matrix of
mean_x = np.mean(x, axis = 0) #18 * 9
std_x = np.std(x, axis = 0) #18 * 9
# Z-Score Normalization(Z分数归一化)
for i in range(len(x)): #12 * 471
for j in range(len(x[0])): #18 * 9
if std_x[j] != 0:
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]
x
array([[-1.35825331, -1.35883937, -1.359222 , ..., 0.26650729,
0.2656797 , -1.14082131],
[-1.35825331, -1.35883937, -1.51819928, ..., 0.26650729,
-1.13963133, -1.32832904],
[-1.35825331, -1.51789368, -1.67717656, ..., -1.13923451,
-1.32700613, -0.85955971],
...,
[-0.88092053, -0.72262212, -0.56433559, ..., -0.57693779,
-0.29644471, -0.39079039],
[-0.7218096 , -0.56356781, -0.72331287, ..., -0.29578943,
-0.39013211, -0.1095288 ],
[-0.56269867, -0.72262212, -0.88229015, ..., -0.38950555,
-0.10906991, 0.07797893]])
将训练数据分割成 "训练集 "和 “验证集”
This part is a simple demonstration,to generate the training set used for training in the comparison and will not be put into training、Just a validation set for validation.
The following figure is the full flow chart:
# xThe length is the number of lines12*471=5652
print(len(x))
5652
import math
# Math.floor()为向下取整
# 将训练数据分割成 "训练集 "和 "验证集",比例为8:2
x_train_set = x[: math.floor(len(x) * 0.8), :]
y_train_set = y[: math.floor(len(y) * 0.8), :]
x_validation = x[math.floor(len(x) * 0.8): , :]
y_validation = y[math.floor(len(y) * 0.8): , :]
print(x_train_set)
print(y_train_set)
print(x_validation)
print(y_validation)
# 训练集为4521行,测试集为1131行
print(len(x_train_set))
print(len(y_train_set))
print(len(x_validation))
print(len(y_validation))
[[-1.35825331 -1.35883937 -1.359222 ... 0.26650729 0.2656797
-1.14082131]
[-1.35825331 -1.35883937 -1.51819928 ... 0.26650729 -1.13963133
-1.32832904]
[-1.35825331 -1.51789368 -1.67717656 ... -1.13923451 -1.32700613
-0.85955971]
...
[ 0.86929969 0.70886668 0.38952809 ... 1.39110073 0.2656797
-0.39079039]
[ 0.71018876 0.39075806 0.07157353 ... 0.26650729 -0.39013211
-0.39079039]
[ 0.3919669 0.07264944 0.07157353 ... -0.38950555 -0.39013211
-0.85955971]]
[[30.]
[41.]
[44.]
...
[ 7.]
[ 5.]
[14.]]
[[ 0.07374504 0.07264944 0.07157353 ... -0.38950555 -0.85856912
-0.57829812]
[ 0.07374504 0.07264944 0.23055081 ... -0.85808615 -0.57750692
0.54674825]
[ 0.07374504 0.23170375 0.23055081 ... -0.57693779 0.54674191
-0.1095288 ]
...
[-0.88092053 -0.72262212 -0.56433559 ... -0.57693779 -0.29644471
-0.39079039]
[-0.7218096 -0.56356781 -0.72331287 ... -0.29578943 -0.39013211
-0.1095288 ]
[-0.56269867 -0.72262212 -0.88229015 ... -0.38950555 -0.10906991
0.07797893]]
[[13.]
[24.]
[22.]
...
[17.]
[24.]
[29.]]
4521
4521
1131
1131
训练
The following figure is the full flow chart:
because of the existence of the constant term,所以 维度 (dim) Need to add one more column;eps Item is to avoid adagrad 的分母为 0 And the added minimal value.
每一个 维度 (dim) will correspond to their respective gradients, 权重 (w),through iterations (iter_time) 学习.
# x+y的列数
dim = 18 * 9 + 1
w = np.zeros([dim, 1])
x = np.concatenate((np.ones([12 * 471, 1]), x), axis = 1).astype(float)
learning_rate = 100
iter_time = 1000
adagrad = np.zeros([dim, 1])
eps = 0.0000000001
# loss函数使用的是:RMSE(Root Mean Square Error)均方根误差
# 均方根误差是预测值与真实值偏差的平方与观测次数n比值的平方根.
# It measures the deviation between the predicted value and the true value,并且对数据中的异常值较为敏感.
for t in range(iter_time):
loss = np.sqrt(np.sum(np.power(np.dot(x, w) - y, 2))/471/12)
# 每迭代100次,打印出当前的loss值
if(t%100==0):
print(str(t) + ":" + str(loss))
gradient = 2 * np.dot(x.transpose(), np.dot(x, w) - y) #dim*1
adagrad += gradient ** 2
w = w - learning_rate * gradient / np.sqrt(adagrad + eps)
# 保存权重文件w
np.save('work/weight.npy', w)
0:27.071214829194115
100:33.78905859777454
200:19.9137512981971
300:13.531068193689693
400:10.645466158446174
500:9.277353455475065
600:8.518042045956502
700:8.014061987588423
800:7.636756824775692
900:7.336563740371124
array([[ 2.13740269e+01],
[ 3.58888909e+00],
[ 4.56386323e+00],
[ 2.16307023e+00],
....
[-4.23463160e-01],
[ 4.89922051e-01]])
测试
The following figure is the full flow chart:
载入测试数据,And processed in a similar way to training data preprocessing and feature extraction,Make test data form 240 个维度为 18 * 9 + 1 的资料.
testdata = pd.read_csv('work/hw1_data/test.csv', header = None, encoding = 'big5')
test_data = testdata.iloc[:, 2:]
test_data[test_data == 'NR'] = 0
test_data = test_data.to_numpy()
test_x = np.empty([240, 18*9], dtype = float)
for i in range(240):
test_x[i, :] = test_data[18 * i: 18* (i + 1), :].reshape(1, -1)
# Z分数归一化
for i in range(len(test_x)):
for j in range(len(test_x[0])):
if std_x[j] != 0:
test_x[i][j] = (test_x[i][j] - mean_x[j]) / std_x[j]
test_x = np.concatenate((np.ones([240, 1]), test_x), axis = 1).astype(float)
test_x
array([[ 1. , -0.24447681, -0.24545919, ..., -0.67065391,
-1.04594393, 0.07797893],
[ 1. , -1.35825331, -1.51789368, ..., 0.17279117,
-0.10906991, -0.48454426],
[ 1. , 1.5057434 , 1.34508393, ..., -1.32666675,
-1.04594393, -0.57829812],
...,
[ 1. , 0.3919669 , 0.54981237, ..., 0.26650729,
-0.20275731, 1.20302531],
[ 1. , -1.8355861 , -1.8360023 , ..., -1.04551839,
-1.13963133, -1.14082131],
[ 1. , -1.35825331, -1.35883937, ..., 2.98427476,
3.26367657, 1.76554849]])
预测
The following figure is the full flow chart:
有了 权重 and test data can be predicted 目标.
# The original test set*权重w,进行预测
w = np.load('work/weight.npy')
ans_y = np.dot(test_x, w)
array([[ 5.17496040e+00],
[ 1.83062143e+01],
.....
[ 1.43137440e+01],
[ 1.57707266e+01]])
Save the forecast toCSV文件
The following figure is the full flow chart:
import csv
with open('work/submit.csv', mode='w', newline='') as submit_file:
csv_writer = csv.writer(submit_file)
header = ['id', 'value']
print(header)
csv_writer.writerow(header)
for i in range(240):
row = ['id_' + str(i), ans_y[i][0]]
csv_writer.writerow(row)
print(row)
['id', 'value']
['id_0', 5.174960398984726]
['id_1', 18.306214253527884]
['id_2', 20.491218094180542]
['id_3', 11.523942869805353]
['id_4', 26.61605675230616]
['id_5', 20.53134808176122]
['id_6', 21.906551018797376]
['id_7', 31.73646874706883]
['id_8', 13.391674055111736]
['id_9', 64.45646650291955]
['id_10', 20.264568836159466]
['id_11', 15.358576077361217]
['id_12', 68.58947276926725]
['id_13', 48.428113747457196]
['id_14', 18.702333824193207]
['id_15', 10.188595737466706]
['id_16', 30.74036285982042]
['id_17', 71.1322177635511]
['id_18', -4.130517391262453]
['id_19', 18.23569401642868]
['id_20', 38.57892227500775]
['id_21', 71.31151972531332]
['id_22', 7.410348162634064]
['id_23', 18.71795533032141]
['id_24', 14.937250260084582]
['id_25', 36.719736694705325]
['id_26', 17.961697005662696]
['id_27', 75.78946287210537]
['id_28', 12.309310248614484]
['id_29', 56.2953517396496]
['id_30', 25.113160865661484]
['id_31', 4.6102486740940325]
['id_32', 2.483770554515017]
['id_33', 24.759422261321284]
['id_34', 30.48028046559118]
['id_35', 38.463930746426634]
['id_36', 44.20231060933005]
['id_37', 30.086836019866013]
['id_38', 40.4736750157401]
['id_39', 29.22647990231738]
['id_40', 5.606456054343926]
['id_41', 38.666016078789596]
['id_42', 34.610213431877206]
['id_43', 48.38969750738481]
['id_44', 14.75724766694418]
['id_45', 34.46682011087208]
['id_46', 27.48310687418435]
['id_47', 12.000879378154064]
['id_48', 21.378036151603776]
['id_49', 28.54440309166329]
['id_50', 20.16551381841159]
['id_51', 10.796678149746501]
['id_52', 22.171035755750147]
['id_53', 53.44626310935228]
['id_54', 12.219581121610014]
['id_55', 43.30096845517152]
['id_56', 32.182335103285425]
['id_57', 22.567217514570817]
['id_58', 56.739514165547035]
['id_59', 20.745052945295463]
['id_60', 15.02885455747326]
['id_61', 39.8553015903851]
['id_62', 12.975340680728287]
['id_63', 51.74165959283004]
['id_64', 18.783369632539888]
['id_65', 12.348752842777701]
['id_66', 15.633623653541909]
['id_67', -0.058871470685014415]
['id_68', 41.50801107307594]
['id_69', 31.548747530656033]
['id_70', 18.60425115754707]
['id_71', 37.4768197248807]
['id_72', 56.52039065762305]
['id_73', 6.587877193521951]
['id_74', 12.229339737435023]
['id_75', 5.203696404134652]
['id_76', 47.92737510380062]
['id_77', 13.020705685594672]
['id_78', 17.110301693903615]
['id_79', 20.60323453100204]
['id_80', 21.2844815607846]
['id_81', 38.6929352905118]
['id_82', 30.02071667572584]
['id_83', 88.76740666723548]
['id_84', 35.98470023966825]
['id_85', 26.756913553477172]
['id_86', 23.963516843564452]
['id_87', 32.747242828083074]
['id_88', 22.189043755319933]
['id_89', 20.99215885362656]
['id_90', 29.555994316645464]
['id_91', 40.99216886651781]
['id_92', 8.625117809911576]
['id_93', 32.3214718088779]
['id_94', 46.59804436536758]
['id_95', 22.884070826723534]
['id_96', 31.518129728251637]
['id_97', 11.198233479766111]
['id_98', 28.527436642529615]
['id_99', 0.29115068008963196]
['id_100', 17.966961079539693]
['id_101', 27.124163929470143]
['id_102', 11.398232780652853]
['id_103', 16.426426865673516]
['id_104', 23.425261046922163]
['id_105', 40.616082670568396]
['id_106', 25.8641250265604]
['id_107', 5.422736951672383]
['id_108', 10.794921122256119]
['id_109', 72.86213692992126]
['id_110', 48.022837059481404]
['id_111', 15.74680827690301]
['id_112', 24.670410614177968]
['id_113', 12.827793326536716]
['id_114', 10.158057570240517]
['id_115', 27.269223342020993]
['id_116', 29.20873857793244]
['id_117', 8.835339619930764]
['id_118', 20.05108813712979]
['id_119', 20.212333743764248]
['id_120', 79.90600929870556]
['id_121', 18.06161428826361]
['id_122', 30.542809341304327]
['id_123', 25.980792377728037]
['id_124', 5.212577268164774]
['id_125', 30.355697305856207]
['id_126', 7.7683228889146445]
['id_127', 15.328268255393342]
['id_128', 22.666365717697975]
['id_129', 62.74205421109008]
['id_130', 18.950780367988]
['id_131', 19.07635563083853]
['id_132', 61.371574091637115]
['id_133', 15.884562052629704]
['id_134', 13.409418077705558]
['id_135', 0.8487724836112854]
['id_136', 7.8349967173041435]
['id_137', 57.01282901179679]
['id_138', 25.607996751813825]
['id_139', 4.961704729242083]
['id_140', 36.41487903906277]
['id_141', 28.790006721975924]
['id_142', 49.194120961976346]
['id_143', 40.3068698557345]
['id_144', 13.316180593982665]
['id_145', 27.66101187522916]
['id_146', 17.15802752436674]
['id_147', 49.68726256929681]
['id_148', 23.030272291604767]
['id_149', 39.24093652484275]
['id_150', 13.196753889412534]
['id_151', 5.94889370103942]
['id_152', 25.82160897630425]
['id_153', 8.25863421429164]
['id_154', 19.14632051722559]
['id_155', 43.18248652651675]
['id_156', 6.717843578093027]
['id_157', 33.86961524681065]
['id_158', 15.369937846981808]
['id_159', 16.93904497355194]
['id_160', 37.88533679463485]
['id_161', 19.20248454105448]
['id_162', 9.059504715654713]
['id_163', 10.283399610648498]
['id_164', 48.672447125698284]
['id_165', 30.587716213230834]
['id_166', 2.477409897532155]
['id_167', 12.81160393780593]
['id_168', 70.32478980976464]
['id_169', 14.840967694067043]
['id_170', 68.86558756678863]
['id_171', 42.741992444866334]
['id_172', 24.00026154292016]
['id_173', 23.420724860321442]
['id_174', 61.67212443568237]
['id_175', 25.4942028450592]
['id_176', 19.004809786869068]
['id_177', 34.88668288189681]
['id_178', 9.402313398379727]
['id_179', 29.520011314408027]
['id_180', 14.573965885700494]
['id_181', 9.125563143203577]
['id_182', 52.81258399813187]
['id_183', 45.039537994389605]
['id_184', 17.45243467918329]
['id_185', 38.49393527971432]
['id_186', 27.03891909264383]
['id_187', 65.58170967424581]
['id_188', 7.037306380769563]
['id_189', 52.71447713411569]
['id_190', 38.2064593370498]
['id_191', 21.16980105955784]
['id_192', 30.2475568794884]
['id_193', 2.714422989716311]
['id_194', 19.93293258764082]
['id_195', -3.413332337603926]
['id_196', 32.44599940281316]
['id_197', 10.582973029979941]
['id_198', 21.77522570725845]
['id_199', 62.465292065677886]
['id_200', 24.132943687316462]
['id_201', 26.20123964740095]
['id_202', 63.744477234402886]
['id_203', 2.834297774129029]
['id_204', 14.37924698697884]
['id_205', 9.369850731753909]
['id_206', 9.881166613595404]
['id_207', 3.494945358972141]
['id_208', 122.6080493792178]
['id_209', 21.08351301448056]
['id_210', 17.53222059945514]
['id_211', 20.183098344596996]
['id_212', 36.39313221228184]
['id_213', 34.93515120529069]
['id_214', 18.83031266145862]
['id_215', 38.34455552272332]
['id_216', 77.9166341380704]
['id_217', 1.7953235508882321]
['id_218', 13.445827939135775]
['id_219', 36.131155590412135]
['id_220', 15.150403498166302]
['id_221', 12.941848334417905]
['id_222', 113.1252409378639]
['id_223', 15.224604677934368]
['id_224', 14.824025968612045]
['id_225', 59.26735368854045]
['id_226', 10.58369529071846]
['id_227', 20.993062563532174]
['id_228', 9.789365880830378]
['id_229', 4.77118000870598]
['id_230', 47.92780690481291]
['id_231', 12.399438394751055]
['id_232', 48.146476562644125]
['id_233', 40.46638039656413]
['id_234', 16.940590270332937]
['id_235', 41.266544489418735]
['id_236', 69.027892033729]
['id_237', 40.34624924412243]
['id_238', 14.313743982871172]
['id_239', 15.770726634219809]
The above printed part is mainly to see the presentation of the data and results,It's okay to take it off.另外,在自己的 linux 系统,You can replace the hard-coded part of the file with sys.argv 的使用 (可在 终端 Enter the file and file location yourself).
最后,can be adjusted (learning_rate)学习率、iter_time (迭代次数)、How many features to use(Take a few hours,Which characteristic fields to take),甚至是不同的 model to surpass the baseline.
边栏推荐
- Activity的四种启动模式
- TF中的条件语句;where()
- There may be fields that cannot be serialized in the abnormal object of cdc and sqlserver. Is there anyone who can understand it? Help me to answer
- STM32CUBEIDE(11)----输出PWM及修改PWM频率与占空比
- C语言每日一练——Day02:求最小公倍数(3种方法)
- 1096 大美数 (15 分)
- easyrecovery15数据恢复软件收费吗?功能强大吗?
- 3.2-分类-Logistic回归
- 求职简历这样写,轻松搞定面试官
- js根据当天获取前几天的日期
猜你喜欢
1096 big beautiful numbers (15 points)
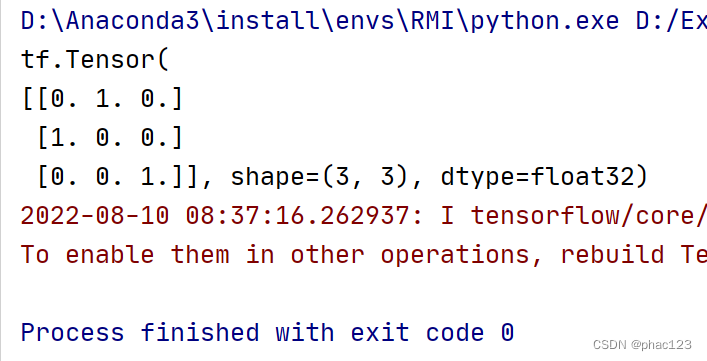
TF中的One-hot
1091 N-Defensive Number (15 points)

Tf中的平方,多次方,开方计算
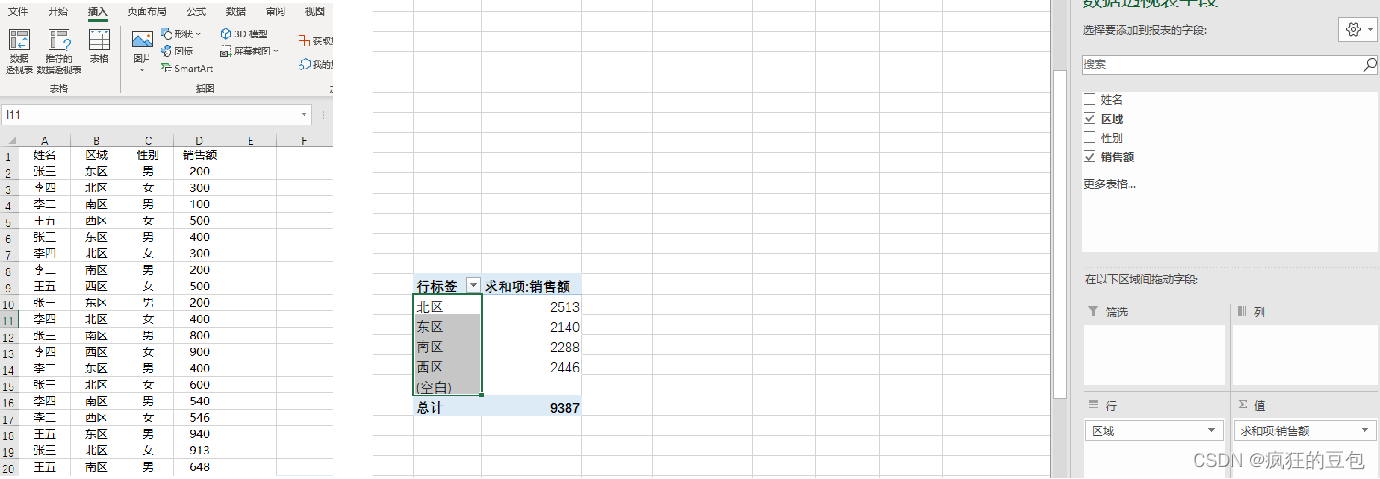
The most complete documentation on Excel's implementation of grouped summation
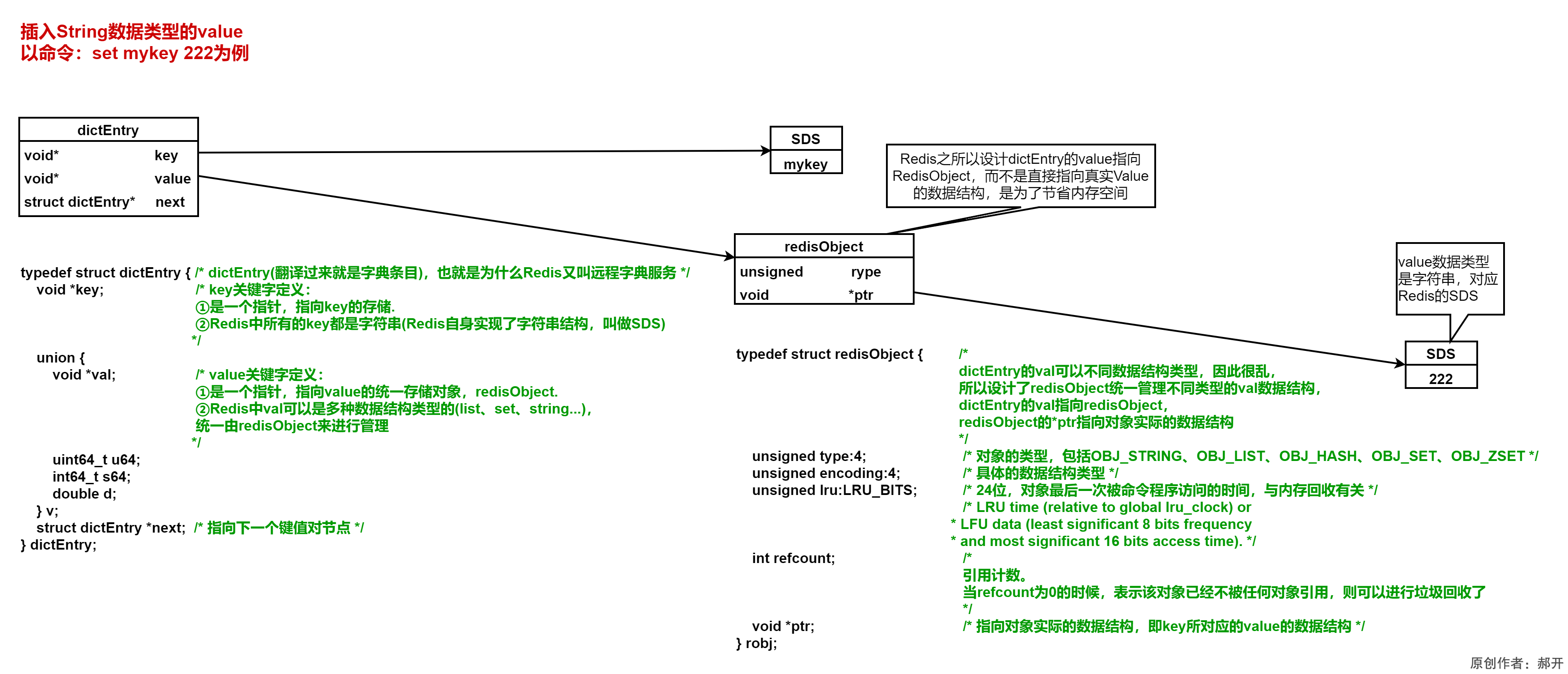
Redis source code-String: Redis String command, Redis String storage principle, three encoding types of Redis string, Redis String SDS source code analysis, Redis String application scenarios
My creative anniversary丨Thank you for being with you for these 365 days, not forgetting the original intention, and each is wonderful
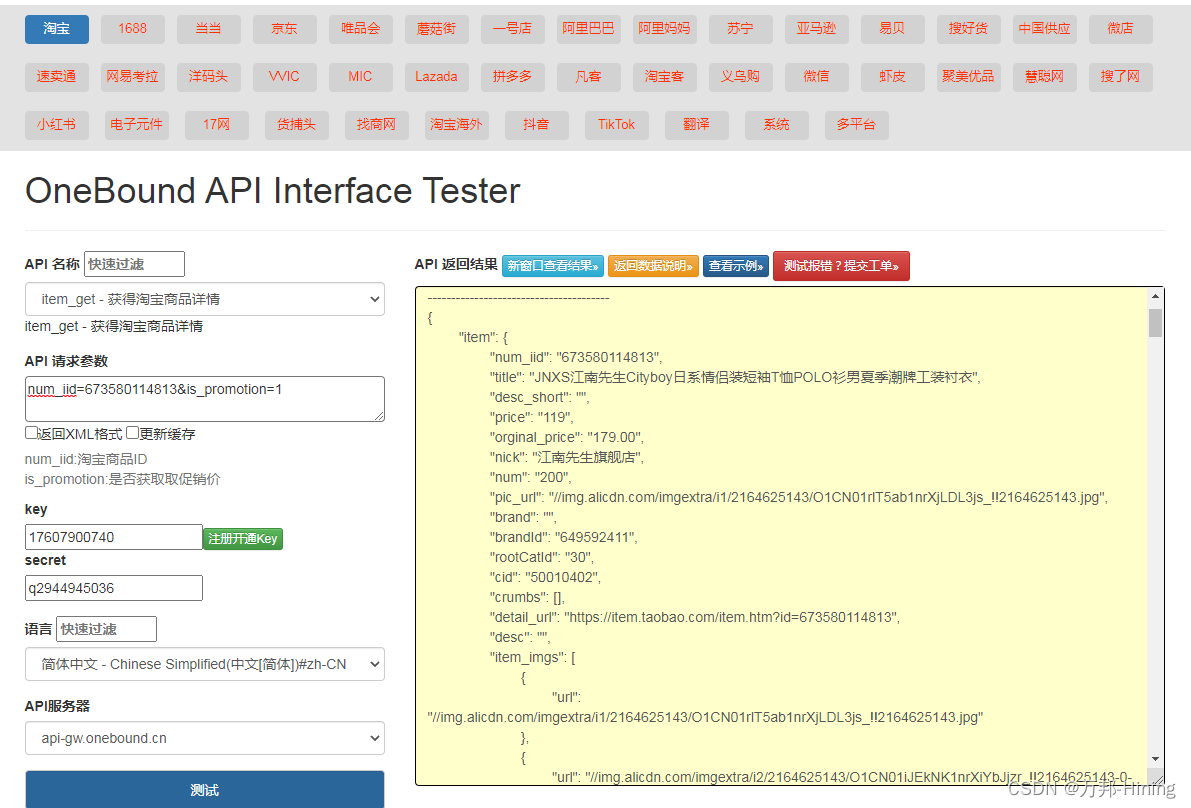
Taobao product details API interface

伦敦银规则有哪些?

JRS303-Data Verification
随机推荐
tf.cast(),reduce_min(),reduce_max()
Redis source code-String: Redis String command, Redis String storage principle, three encoding types of Redis string, Redis String SDS source code analysis, Redis String application scenarios
How Unity programmers can improve their abilities
接口测试的基础流程和用例设计方法你知道吗?
测试用例很难?有手就行
1046 punches (15 points)
1061 判断题 (15 分)
从何跟踪伦敦金最新行情走势?
1081 检查密码 (15 分)
2022-08-10 Group 4 Self-cultivation class study notes (every day)
1076 Wifi密码 (15 分)
matplotlib
1061 True or False (15 points)
2021-08-11 for循环结合多线程异步查询并收集结果
Discourse's Close Topic and Reopen Topic
1101 How many times B is A (15 points)
go-grpc TSL认证 解决 transport: authentication handshake failed: x509 certificate relies on ... ...
语音信号处理:预处理【预加重、分帧、加窗】
JRS303-Data Verification
基于FPGA的FIR滤波器的实现(4)— 串行结构FIR滤波器的FPGA代码实现