当前位置:网站首页>mysql性能监控与执行计划
mysql性能监控与执行计划
2022-08-10 20:24:00 【xushiyu1996818】
目录
show profile
使用show profile查询剖析工具,可以指定具体的type
此工具默认是禁用的,可以通过服务器变量在绘画级别动态的修改
set profiling=1;
当设置完成之后,在服务器上执行的所有语句,都会测量其耗费的时间和其他一些查询执行状态变更相关的数据。
select * from emp;
在mysql的命令行模式下只能显示两位小数的时间,可以使用如下命令查看具体的执行时间
show profiles;
执行如下命令可以查看详细的每个步骤的时间:
show profile for query 1;

具体profile类型
type
all:显示所有性能信息
show profile all for query n
block io:显示块io操作的次数
show profile block io for query n
context switches:显示上下文切换次数,被动和主动
show profile context switches for query n
cpu:显示用户cpu时间、系统cpu时间
show profile cpu for query n
IPC:显示发送和接受的消息数量
show profile ipc for query n
Memory:暂未实现
page faults:显示页错误数量
show profile page faults for query n
source:显示源码中的函数名称与位置
show profile source for query n
swaps:显示swap的次数
show profile swaps for query n
具体结果字段含义
上图中横向栏意义
"Status": "query end", 状态
"Duration": "1.751142", 持续时间
"CPU_user": "0.008999", cpu用户
"CPU_system": "0.003999", cpu系统
"Context_voluntary": "98", 上下文主动切换
"Context_involuntary": "0", 上下文被动切换
"Block_ops_in": "8", 阻塞的输入操作
"Block_ops_out": "32", 阻塞的输出操作
"Messages_sent": "0", 消息发出
"Messages_received": "0", 消息接受
"Page_faults_major": "0", 主分页错误
"Page_faults_minor": "0", 次分页错误
"Swaps": "0", 交换次数
"Source_function": "mysql_execute_command", 源功能
"Source_file": "sql_parse.cc", 源文件
"Source_line": "4465" 源代码行
上图中纵向栏意义
starting:开始
checking permissions:检查权限
Opening tables:打开表
init : 初始化
System lock :系统锁
optimizing : 优化
statistics : 统计
preparing :准备
executing :执行
Sending data :发送数据
Sorting result :排序
end :结束
query end :查询 结束
closing tables : 关闭表 /去除TMP 表
freeing items : 释放物品
cleaning up :清理
performance schema
performance_schema的介绍
MySQL的performance schema 用于监控MySQL server在一个较低级别的运行过程中的资源消耗、资源等待等情况。
特点如下:
1、提供了一种在数据库运行时实时检查server的内部执行情况的方法。performance_schema 数据库中的表使用performance_schema存储引擎。该数据库主要关注数据库运行过程中的性能相关的数据,与information_schema不同,information_schema主要关注server运行过程中的元数据信息
2、performance_schema通过监视server的事件来实现监视server内部运行情况, “事件”就是server内部活动中所做的任何事情以及对应的时间消耗,利用这些信息来判断server中的相关资源消耗在了哪里?一般来说,事件可以是函数调用、操作系统的等待、SQL语句执行的阶段(如sql语句执行过程中的parsing 或 sorting阶段)或者整个SQL语句与SQL语句集合。事件的采集可以方便的提供server中的相关存储引擎对磁盘文件、表I/O、表锁等资源的同步调用信息。
3、performance_schema中的事件与写入二进制日志中的事件(描述数据修改的events)、事件计划调度程序(这是一种存储程序)的事件不同。performance_schema中的事件记录的是server执行某些活动对某些资源的消耗、耗时、这些活动执行的次数等情况。
4、performance_schema中的事件只记录在本地server的performance_schema中,其下的这些表中数据发生变化时不会被写入binlog中,也不会通过复制机制被复制到其他server中。
5、 当前活跃事件、历史事件和事件摘要相关的表中记录的信息。能提供某个事件的执行次数、使用时长。进而可用于分析某个特定线程、特定对象(如mutex或file)相关联的活动。
6、PERFORMANCE_SCHEMA存储引擎使用server源代码中的“检测点”来实现事件数据的收集。对于performance_schema实现机制本身的代码没有相关的单独线程来检测,这与其他功能(如复制或事件计划程序)不同
7、收集的事件数据存储在performance_schema数据库的表中。这些表可以使用SELECT语句查询,也可以使用SQL语句更新performance_schema数据库中的表记录(如动态修改performance_schema的setup_*开头的几个配置表,但要注意:配置表的更改会立即生效,这会影响数据收集)
8、performance_schema的表中的数据不会持久化存储在磁盘中,而是保存在内存中,一旦服务器重启,这些数据会丢失(包括配置表在内的整个performance_schema下的所有数据)
9、MySQL支持的所有平台中事件监控功能都可用,但不同平台中用于统计事件时间开销的计时器类型可能会有所差异。
performance schema入门
在mysql的5.7版本中,性能模式是默认开启的,如果想要显式的关闭的话需要修改配置文件,不能直接进行修改,会报错Variable 'performance_schema' is a read only variable。
--查看performance_schema的属性
mysql> SHOW VARIABLES LIKE 'performance_schema';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| performance_schema | ON |
+--------------------+-------+
1 row in set (0.01 sec)
--在配置文件中修改performance_schema的属性值,on表示开启,off表示关闭
[mysqld]
performance_schema=ON
--切换数据库
use performance_schema;
--查看当前数据库下的所有表,会看到有很多表存储着相关的信息
show tables;
--可以通过show create table tablename来查看创建表的时候的表结构
mysql> show create table setup_consumers;
+-----------------+---------------------------------
| Table | Create Table
+-----------------+---------------------------------
| setup_consumers | CREATE TABLE `setup_consumers` (
`NAME` varchar(64) NOT NULL,
`ENABLED` enum('YES','NO') NOT NULL
) ENGINE=PERFORMANCE_SCHEMA DEFAULT CHARSET=utf8 |
+-----------------+---------------------------------
1 row in set (0.00 sec) 想要搞明白后续的内容,同学们需要理解两个基本概念:
instruments: 生产者,用于采集mysql中各种各样的操作产生的事件信息,对应配置表中的配置项我们可以称为监控采集配置项。
consumers:消费者,对应的消费者表用于存储来自instruments采集的数据,对应配置表中的配置项我们可以称为消费存储配置项。
performance_schema表的分类
performance_schema库下的表可以按照监视不同的纬度就行分组。
--语句事件记录表,这些表记录了语句事件信息,当前语句事件表events_statements_current、历史语句事件表events_statements_history和长语句历史事件表events_statements_history_long、以及聚合后的摘要表summary,其中,summary表还可以根据帐号(account),主机(host),程序(program),线程(thread),用户(user)和全局(global)再进行细分)
show tables like '%statement%';
--等待事件记录表,与语句事件类型的相关记录表类似:
show tables like '%wait%';
--阶段事件记录表,记录语句执行的阶段事件的表
show tables like '%stage%';
--事务事件记录表,记录事务相关的事件的表
show tables like '%transaction%';
--监控文件系统层调用的表
show tables like '%file%';
--监视内存使用的表
show tables like '%memory%';
--动态对performance_schema进行配置的配置表
show tables like '%setup%';performance_schema的简单配置与使用
数据库刚刚初始化并启动时,并非所有instruments(事件采集项,在采集项的配置表中每一项都有一个开关字段,或为YES,或为NO)和consumers(与采集项类似,也有一个对应的事件类型保存表配置项,为YES就表示对应的表保存性能数据,为NO就表示对应的表不保存性能数据)都启用了,所以默认不会收集所有的事件,可能你需要检测的事件并没有打开,需要进行设置,可以使用如下两个语句打开对应的instruments和consumers(行计数可能会因MySQL版本而异)。
--打开等待事件的采集器配置项开关,需要修改setup_instruments配置表中对应的采集器配置项
UPDATE setup_instruments SET ENABLED = 'YES', TIMED = 'YES'where name like 'wait%';
--打开等待事件的保存表配置开关,修改setup_consumers配置表中对应的配置项
UPDATE setup_consumers SET ENABLED = 'YES'where name like '%wait%';
--当配置完成之后可以查看当前server正在做什么,可以通过查询events_waits_current表来得知,该表中每个线程只包含一行数据,用于显示每个线程的最新监视事件
select * from events_waits_current\G
*************************** 1. row ***************************
THREAD_ID: 11
EVENT_ID: 570
END_EVENT_ID: 570
EVENT_NAME: wait/synch/mutex/innodb/buf_dblwr_mutex
SOURCE:
TIMER_START: 4508505105239280
TIMER_END: 4508505105270160
TIMER_WAIT: 30880
SPINS: NULL
OBJECT_SCHEMA: NULL
OBJECT_NAME: NULL
INDEX_NAME: NULL
OBJECT_TYPE: NULL
OBJECT_INSTANCE_BEGIN: 67918392
NESTING_EVENT_ID: NULL
NESTING_EVENT_TYPE: NULL
OPERATION: lock
NUMBER_OF_BYTES: NULL
FLAGS: NULL
/*该信息表示线程id为11的线程正在等待buf_dblwr_mutex锁,等待事件为30880
属性说明:
id:事件来自哪个线程,事件编号是多少
event_name:表示检测到的具体的内容
source:表示这个检测代码在哪个源文件中以及行号
timer_start:表示该事件的开始时间
timer_end:表示该事件的结束时间
timer_wait:表示该事件总的花费时间
注意:_current表中每个线程只保留一条记录,一旦线程完成工作,该表中不会再记录该线程的事件信息
*/
/*
_history表中记录每个线程应该执行完成的事件信息,但每个线程的事件信息只会记录10条,再多就会被覆盖,*_history_long表中记录所有线程的事件信息,但总记录数量是10000,超过就会被覆盖掉
*/
select thread_id,event_id,event_name,timer_wait from events_waits_history order by thread_id limit 21;
/*
summary表提供所有事件的汇总信息,该组中的表以不同的方式汇总事件数据(如:按用户,按主机,按线程等等)。例如:要查看哪些instruments占用最多的时间,可以通过对events_waits_summary_global_by_event_name表的COUNT_STAR或SUM_TIMER_WAIT列进行查询(这两列是对事件的记录数执行COUNT(*)、事件记录的TIMER_WAIT列执行SUM(TIMER_WAIT)统计而来)
*/
SELECT EVENT_NAME,COUNT_STAR FROM events_waits_summary_global_by_event_name ORDER BY COUNT_STAR DESC LIMIT 10;
/*
instance表记录了哪些类型的对象会被检测。这些对象在被server使用时,在该表中将会产生一条事件记录,例如,file_instances表列出了文件I/O操作及其关联文件名
*/
select * from file_instances limit 20; 常用配置项的参数说明
1、启动选项
performance_schema_consumer_events_statements_current=TRUE
是否在mysql server启动时就开启events_statements_current表的记录功能(该表记录当前的语句事件信息),启动之后也可以在setup_consumers表中使用UPDATE语句进行动态更新setup_consumers配置表中的events_statements_current配置项,默认值为TRUE
performance_schema_consumer_events_statements_history=TRUE
与performance_schema_consumer_events_statements_current选项类似,但该选项是用于配置是否记录语句事件短历史信息,默认为TRUE
performance_schema_consumer_events_stages_history_long=FALSE
与performance_schema_consumer_events_statements_current选项类似,但该选项是用于配置是否记录语句事件长历史信息,默认为FALSE
除了statement(语句)事件之外,还支持:wait(等待)事件、state(阶段)事件、transaction(事务)事件,他们与statement事件一样都有三个启动项分别进行配置,但这些等待事件默认未启用,如果需要在MySQL Server启动时一同启动,则通常需要写进my.cnf配置文件中
performance_schema_consumer_global_instrumentation=TRUE
是否在MySQL Server启动时就开启全局表(如:mutex_instances、rwlock_instances、cond_instances、file_instances、users、hostsaccounts、socket_summary_by_event_name、file_summary_by_instance等大部分的全局对象计数统计和事件汇总统计信息表 )的记录功能,启动之后也可以在setup_consumers表中使用UPDATE语句进行动态更新全局配置项
默认值为TRUE
performance_schema_consumer_statements_digest=TRUE
是否在MySQL Server启动时就开启events_statements_summary_by_digest 表的记录功能,启动之后也可以在setup_consumers表中使用UPDATE语句进行动态更新digest配置项
默认值为TRUE
performance_schema_consumer_thread_instrumentation=TRUE
是否在MySQL Server启动时就开启
events_xxx_summary_by_yyy_by_event_name表的记录功能,启动之后也可以在setup_consumers表中使用UPDATE语句进行动态更新线程配置项
默认值为TRUE
performance_schema_instrument[=name]
是否在MySQL Server启动时就启用某些采集器,由于instruments配置项多达数千个,所以该配置项支持key-value模式,还支持%号进行通配等,如下:
# [=name]可以指定为具体的Instruments名称(但是这样如果有多个需要指定的时候,就需要使用该选项多次),也可以使用通配符,可以指定instruments相同的前缀+通配符,也可以使用%代表所有的instruments
## 指定开启单个instruments
--performance-schema-instrument= 'instrument_name=value'
## 使用通配符指定开启多个instruments
--performance-schema-instrument= 'wait/synch/cond/%=COUNTED'
## 开关所有的instruments
--performance-schema-instrument= '%=ON'
--performance-schema-instrument= '%=OFF'
注意,这些启动选项要生效的前提是,需要设置performance_schema=ON。另外,这些启动选项虽然无法使用show variables语句查看,但我们可以通过setup_instruments和setup_consumers表查询这些选项指定的值。2、系统变量
show variables like '%performance_schema%';
--重要的属性解释
performance_schema=ON
/*
控制performance_schema功能的开关,要使用MySQL的performance_schema,需要在mysqld启动时启用,以启用事件收集功能
该参数在5.7.x之前支持performance_schema的版本中默认关闭,5.7.x版本开始默认开启
注意:如果mysqld在初始化performance_schema时发现无法分配任何相关的内部缓冲区,则performance_schema将自动禁用,并将performance_schema设置为OFF
*/
performance_schema_digests_size=10000
/*
控制events_statements_summary_by_digest表中的最大行数。如果产生的语句摘要信息超过此最大值,便无法继续存入该表,此时performance_schema会增加状态变量
*/
performance_schema_events_statements_history_long_size=10000
/*
控制events_statements_history_long表中的最大行数,该参数控制所有会话在events_statements_history_long表中能够存放的总事件记录数,超过这个限制之后,最早的记录将被覆盖
全局变量,只读变量,整型值,5.6.3版本引入 * 5.6.x版本中,5.6.5及其之前的版本默认为10000,5.6.6及其之后的版本默认值为-1,通常情况下,自动计算的值都是10000 * 5.7.x版本中,默认值为-1,通常情况下,自动计算的值都是10000
*/
performance_schema_events_statements_history_size=10
/*
控制events_statements_history表中单个线程(会话)的最大行数,该参数控制单个会话在events_statements_history表中能够存放的事件记录数,超过这个限制之后,单个会话最早的记录将被覆盖
全局变量,只读变量,整型值,5.6.3版本引入 * 5.6.x版本中,5.6.5及其之前的版本默认为10,5.6.6及其之后的版本默认值为-1,通常情况下,自动计算的值都是10 * 5.7.x版本中,默认值为-1,通常情况下,自动计算的值都是10
除了statement(语句)事件之外,wait(等待)事件、state(阶段)事件、transaction(事务)事件,他们与statement事件一样都有三个参数分别进行存储限制配置,有兴趣的同学自行研究,这里不再赘述
*/
performance_schema_max_digest_length=1024
/*
用于控制标准化形式的SQL语句文本在存入performance_schema时的限制长度,该变量与max_digest_length变量相关(max_digest_length变量含义请自行查阅相关资料)
全局变量,只读变量,默认值1024字节,整型值,取值范围0~1048576
*/
performance_schema_max_sql_text_length=1024
/*
控制存入events_statements_current,events_statements_history和events_statements_history_long语句事件表中的SQL_TEXT列的最大SQL长度字节数。 超出系统变量performance_schema_max_sql_text_length的部分将被丢弃,不会记录,一般情况下不需要调整该参数,除非被截断的部分与其他SQL比起来有很大差异
全局变量,只读变量,整型值,默认值为1024字节,取值范围为0~1048576,5.7.6版本引入
降低系统变量performance_schema_max_sql_text_length值可以减少内存使用,但如果汇总的SQL中,被截断部分有较大差异,会导致没有办法再对这些有较大差异的SQL进行区分。 增加该系统变量值会增加内存使用,但对于汇总SQL来讲可以更精准地区分不同的部分。
*/重要配置表的配置顺序说明
配置表之间存在相互关联关系,按照配置影响的先后顺序,可添加为
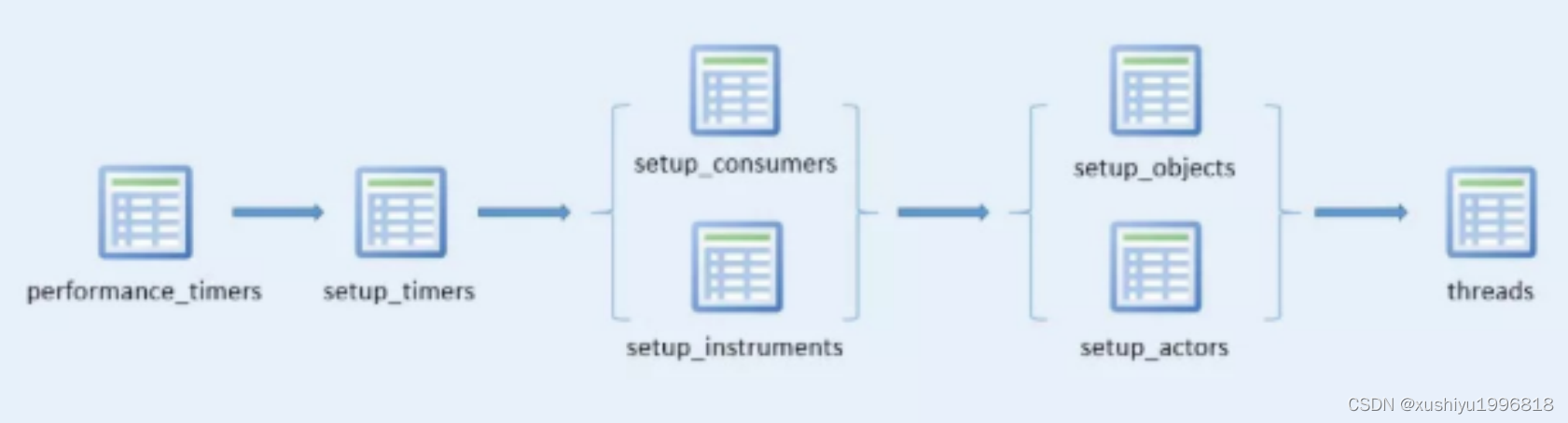
/*
performance_timers表中记录了server中有哪些可用的事件计时器
字段解释:
timer_name:表示可用计时器名称,CYCLE是基于CPU周期计数器的定时器
timer_frequency:表示每秒钟对应的计时器单位的数量,CYCLE计时器的换算值与CPU的频率相关、
timer_resolution:计时器精度值,表示在每个计时器被调用时额外增加的值
timer_overhead:表示在使用定时器获取事件时开销的最小周期值
*/
select * from performance_timers;
/*
setup_timers表中记录当前使用的事件计时器信息
字段解释:
name:计时器类型,对应某个事件类别
timer_name:计时器类型名称
*/
select * from setup_timers;
/*
setup_consumers表中列出了consumers可配置列表项
字段解释:
NAME:consumers配置名称
ENABLED:consumers是否启用,有效值为YES或NO,此列可以使用UPDATE语句修改。
*/
select * from setup_consumers;
/*
setup_instruments 表列出了instruments 列表配置项,即代表了哪些事件支持被收集:
字段解释:
NAME:instruments名称,instruments名称可能具有多个部分并形成层次结构
ENABLED:instrumetns是否启用,有效值为YES或NO,此列可以使用UPDATE语句修改。如果设置为NO,则这个instruments不会被执行,不会产生任何的事件信息
TIMED:instruments是否收集时间信息,有效值为YES或NO,此列可以使用UPDATE语句修改,如果设置为NO,则这个instruments不会收集时间信息
*/
SELECT * FROM setup_instruments;
/*
setup_actors表的初始内容是匹配任何用户和主机,因此对于所有前台线程,默认情况下启用监视和历史事件收集功能
字段解释:
HOST:与grant语句类似的主机名,一个具体的字符串名字,或使用“%”表示“任何主机”
USER:一个具体的字符串名称,或使用“%”表示“任何用户”
ROLE:当前未使用,MySQL 8.0中才启用角色功能
ENABLED:是否启用与HOST,USER,ROLE匹配的前台线程的监控功能,有效值为:YES或NO
HISTORY:是否启用与HOST, USER,ROLE匹配的前台线程的历史事件记录功能,有效值为:YES或NO
*/
SELECT * FROM setup_actors;
/*
setup_objects表控制performance_schema是否监视特定对象。默认情况下,此表的最大行数为100行。
字段解释:
OBJECT_TYPE:instruments类型,有效值为:“EVENT”(事件调度器事件)、“FUNCTION”(存储函数)、“PROCEDURE”(存储过程)、“TABLE”(基表)、“TRIGGER”(触发器),TABLE对象类型的配置会影响表I/O事件(wait/io/table/sql/handler instrument)和表锁事件(wait/lock/table/sql/handler instrument)的收集
OBJECT_SCHEMA:某个监视类型对象涵盖的数据库名称,一个字符串名称,或“%”(表示“任何数据库”)
OBJECT_NAME:某个监视类型对象涵盖的表名,一个字符串名称,或“%”(表示“任何数据库内的对象”)
ENABLED:是否开启对某个类型对象的监视功能,有效值为:YES或NO。此列可以修改
TIMED:是否开启对某个类型对象的时间收集功能,有效值为:YES或NO,此列可以修改
*/
SELECT * FROM setup_objects;
/*
threads表对于每个server线程生成一行包含线程相关的信息,
字段解释:
THREAD_ID:线程的唯一标识符(ID)
NAME:与server中的线程检测代码相关联的名称(注意,这里不是instruments名称)
TYPE:线程类型,有效值为:FOREGROUND、BACKGROUND。分别表示前台线程和后台线程
PROCESSLIST_ID:对应INFORMATION_SCHEMA.PROCESSLIST表中的ID列。
PROCESSLIST_USER:与前台线程相关联的用户名,对于后台线程为NULL。
PROCESSLIST_HOST:与前台线程关联的客户端的主机名,对于后台线程为NULL。
PROCESSLIST_DB:线程的默认数据库,如果没有,则为NULL。
PROCESSLIST_COMMAND:对于前台线程,该值代表着当前客户端正在执行的command类型,如果是sleep则表示当前会话处于空闲状态
PROCESSLIST_TIME:当前线程已处于当前线程状态的持续时间(秒)
PROCESSLIST_STATE:表示线程正在做什么事情。
PROCESSLIST_INFO:线程正在执行的语句,如果没有执行任何语句,则为NULL。
PARENT_THREAD_ID:如果这个线程是一个子线程(由另一个线程生成),那么该字段显示其父线程ID
ROLE:暂未使用
INSTRUMENTED:线程执行的事件是否被检测。有效值:YES、NO
HISTORY:是否记录线程的历史事件。有效值:YES、NO *
THREAD_OS_ID:由操作系统层定义的线程或任务标识符(ID):
*/
select * from threads注意:在performance_schema库中还包含了很多其他的库和表,能对数据库的性能做完整的监控,大家需要参考官网详细了解。
performance_schema实践操作
基本了解了表的相关信息之后,可以通过这些表进行实际的查询操作来进行实际的分析。
--1、哪类的SQL执行最多?
SELECT DIGEST_TEXT,COUNT_STAR,FIRST_SEEN,LAST_SEEN FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
--2、哪类SQL的平均响应时间最多?
SELECT DIGEST_TEXT,AVG_TIMER_WAIT FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
--3、哪类SQL排序记录数最多?
SELECT DIGEST_TEXT,SUM_SORT_ROWS FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
--4、哪类SQL扫描记录数最多?
SELECT DIGEST_TEXT,SUM_ROWS_EXAMINED FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
--5、哪类SQL使用临时表最多?
SELECT DIGEST_TEXT,SUM_CREATED_TMP_TABLES,SUM_CREATED_TMP_DISK_TABLES FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
--6、哪类SQL返回结果集最多?
SELECT DIGEST_TEXT,SUM_ROWS_SENT FROM events_statements_summary_by_digest ORDER BY COUNT_STAR DESC
--7、哪个表物理IO最多?
SELECT file_name,event_name,SUM_NUMBER_OF_BYTES_READ,SUM_NUMBER_OF_BYTES_WRITE FROM file_summary_by_instance ORDER BY SUM_NUMBER_OF_BYTES_READ + SUM_NUMBER_OF_BYTES_WRITE DESC
--8、哪个表逻辑IO最多?
SELECT object_name,COUNT_READ,COUNT_WRITE,COUNT_FETCH,SUM_TIMER_WAIT FROM table_io_waits_summary_by_table ORDER BY sum_timer_wait DESC
--9、哪个索引访问最多?
SELECT OBJECT_NAME,INDEX_NAME,COUNT_FETCH,COUNT_INSERT,COUNT_UPDATE,COUNT_DELETE FROM table_io_waits_summary_by_index_usage ORDER BY SUM_TIMER_WAIT DESC
--10、哪个索引从来没有用过?
SELECT OBJECT_SCHEMA,OBJECT_NAME,INDEX_NAME FROM table_io_waits_summary_by_index_usage WHERE INDEX_NAME IS NOT NULL AND COUNT_STAR = 0 AND OBJECT_SCHEMA <> 'mysql' ORDER BY OBJECT_SCHEMA,OBJECT_NAME;
--11、哪个等待事件消耗时间最多?
SELECT EVENT_NAME,COUNT_STAR,SUM_TIMER_WAIT,AVG_TIMER_WAIT FROM events_waits_summary_global_by_event_name WHERE event_name != 'idle' ORDER BY SUM_TIMER_WAIT DESC
--12-1、剖析某条SQL的执行情况,包括statement信息,stege信息,wait信息
SELECT EVENT_ID,sql_text FROM events_statements_history WHERE sql_text LIKE '%count(*)%';
--12-2、查看每个阶段的时间消耗
SELECT event_id,EVENT_NAME,SOURCE,TIMER_END - TIMER_START FROM events_stages_history_long WHERE NESTING_EVENT_ID = 1553;
--12-3、查看每个阶段的锁等待情况
SELECT event_id,event_name,source,timer_wait,object_name,index_name,operation,nesting_event_id FROM events_waits_history_longWHERE nesting_event_id = 1553;show processlist
使用show processlist查看连接的线程个数,来观察是否有大量线程处于不正常的状态或者其他不正常的特征
mysql> show processlist;
+—–+————-+——————–+
| Id | User | Host | db | Command | Time| State | Info
+—–+————-+——————–+
|207|root |192.168.0.2:51621 |mytest | Sleep | 5 | | NULL
|208|root |192.168.0.2:51622 |mytest | Sleep | 5 | | NULL
|220|root |192.168.0.2:51676 |mytest |Query | 84 | locked |
select name,culture,value,type from book where id=1属性说明
id表示session id
user表示操作的用户
host表示操作的主机
db表示操作的数据库
command表示当前状态
sleep:线程正在等待客户端发送新的请求
query:线程正在执行查询或正在将结果发送给客户端
locked:在mysql的服务层,该线程正在等待表锁
analyzing and statistics:线程正在收集存储引擎的统计信息,并生成查询的执行计划
Copying to tmp table:线程正在执行查询,并且将其结果集都复制到一个临时表中
sorting result:线程正在对结果集进行排序
sending data:线程可能在多个状态之间传送数据,或者在生成结果集或者向客户端返回数据
info表示详细的sql语句
time表示相应命令执行时间
state表示命令执行状态
执行计划explain
在 select 语句之前增加 explain 关键字,mysql会在查询上设置一个标记,执行查询时,会返回执行计划的信息,而不是执行这条SQL(如果 from 中包含子查询,仍会执行该子查询,将结果放入临时表中)。
mysql> explain select * from actor;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | actor | ALL | NULL | NULL | NULL | NULL | 2 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+在查询中的每个表会输出一行,如果有两个表通过 join 连接查询,那么会输出两行。表的意义相当广泛:可以是子查询、一个 union 结果等。
explain 有两个变种:
1)explain extended:会在 explain 的基础上额外提供一些查询优化的信息。紧随其后通过 show warnings 命令可以 得到优化后的查询语句,从而看出优化器优化了什么。额外还有 filtered 列,是一个半分比的值,rows * filtered/100 可以估算出将要和 explain 中前一个表进行连接的行数(前一个表指 explain 中的id值比当前表id值小的表)。
mysql> explain extended select * from film where id = 1;
+----+-------------+-------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | film | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+----------+-------+
mysql> show warnings;
+-------+------+--------------------------------------------------------------------------------+
| Level | Code | Message |
+-------+------+--------------------------------------------------------------------------------+
| Note | 1003 | /* select#1 */ select '1' AS `id`,'film1' AS `name` from `test`.`film` where 1 |
+-------+------+--------------------------------------------------------------------------------+2)explain partitions:相比 explain 多了个 partitions 字段,如果查询是基于分区表的话,会显示查询将访问的分区。
接下来我们将展示 explain 中每个列的信息。
| Column | Meaning |
|---|---|
| id | The SELECT identifier |
| select_type | The SELECT type |
| table | The table for the output row |
| partitions | The matching partitions |
| type | The join type |
| possible_keys | The possible indexes to choose |
| key | The index actually chosen |
| key_len | The length of the chosen key |
| ref | The columns compared to the index |
| rows | Estimate of rows to be examined |
| filtered | Percentage of rows filtered by table condition |
| extra | Additional information |
id列
id列的编号是 select 的序列号,有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。
如果id相同,那么执行顺序从上到下
如果id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
id相同和不同的,同时存在:相同的可以认为是一组,从上往下顺序执行,在所有组中,id值越大,优先级越高,越先执行
MySQL将 select 查询分为简单查询和复杂查询。复杂查询分为三类:简单子查询、派生表(from语句中的子查询)、union 查询。
1)简单子查询
mysql> explain select (select 1 from actor limit 1) from film;
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| 1 | PRIMARY | film | index | NULL | idx_name | 32 | NULL | 1 | Using index |
| 2 | SUBQUERY | actor | index | NULL | PRIMARY | 4 | NULL | 2 | Using index |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+ 2)from子句中的子查询
mysql> explain select id from (select id from film) as der;
+----+-------------+------------+-------+---------------+----------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+---------------+----------+---------+------+------+-------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 2 | NULL |
| 2 | DERIVED | film | index | NULL | idx_name | 32 | NULL | 1 | Using index |
+----+-------------+------------+-------+---------------+----------+---------+------+------+-------------+这个查询执行时有个临时表别名为der,外部 select 查询引用了这个临时表
3)union查询
mysql> explain select 1 union all select 1;
+----+--------------+------------+------+---------------+------+---------+------+------+-----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+------------+------+---------------+------+---------+------+------+-----------------+
| 1 | PRIMARY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
| 2 | UNION | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
| NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+------------+------+---------------+------+---------+------+------+-----------------+union结果总是放在一个匿名临时表中,临时表不在SQL总出现,因此它的id是NULL。
select_type列
select_type 表示对应行是是简单还是复杂的查询,如果是复杂的查询,又是上述三种复杂查询中的哪一种。
1)simple:简单查询。查询不包含子查询和union
mysql> explain select * from film where id = 2;
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | film | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+2)primary:复杂查询中最外层的 select
3)subquery:包含在 select 中的子查询(不在 from 子句中)
4)derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)
用这个例子来了解 primary、subquery 和 derived 类型
mysql> explain select (select 1 from actor where id = 1) from (select * from film where id = 1) der;
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------------+
| 1 | PRIMARY | <derived3> | system | NULL | NULL | NULL | NULL | 1 | NULL |
| 3 | DERIVED | film | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL |
| 2 | SUBQUERY | actor | const | PRIMARY | PRIMARY | 4 | const | 1 | Using index |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+-------------+ 5)union:在 union 中的第二个和随后的 select
6)union result:从 union 临时表检索结果的 select
用这个例子来了解 union 和 union result 类型:
mysql> explain select 1 union all select 1;
+----+--------------+------------+------+---------------+------+---------+------+------+-----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+------------+------+---------------+------+---------+------+------+-----------------+
| 1 | PRIMARY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
| 2 | UNION | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
| NULL | UNION RESULT | <union1,2> | ALL | NULL | NULL | NULL | NULL | NULL | Using temporary |
+----+--------------+------------+------+---------------+------+---------+------+------+-----------------+--sample:简单的查询,不包含子查询和union
explain select * from emp;
--primary:查询中若包含任何复杂的子查询,最外层查询则被标记为Primary
explain select staname,ename supname from (select ename staname,mgr from emp) t join emp on t.mgr=emp.empno ;
--union:若第二个select出现在union之后,则被标记为union
explain select * from emp where deptno = 10 union select * from emp where sal >2000;
--dependent union:跟union类似,此处的depentent表示union或union all联合而成的结果会受外部表影响
explain select * from emp e where e.empno in ( select empno from emp where deptno = 10 union select empno from emp where sal >2000)
--union result:从union表获取结果的select
explain select * from emp where deptno = 10 union select * from emp where sal >2000;
--subquery:在select或者where列表中包含子查询
explain select * from emp where sal > (select avg(sal) from emp) ;
--dependent subquery:subquery的子查询要受到外部表查询的影响
explain select * from emp e where e.deptno in (select distinct deptno from dept);
--DERIVED: from子句中出现的子查询,也叫做派生类,
explain select staname,ename supname from (select ename staname,mgr from emp) t join emp on t.mgr=emp.empno ;
--UNCACHEABLE SUBQUERY:表示使用子查询的结果不能被缓存
explain select * from emp where empno = (select empno from emp where [email protected]@sort_buffer_size);
--uncacheable union:表示union的查询结果不能被缓存:sql语句未验证table列
对应行正在访问哪一个表,表名或者别名,可能是临时表或者union合并结果集
1、如果是具体的表名,则表明从实际的物理表中获取数据,当然也可以是表的别名
2、表名是derivedN的形式,表示使用了id为N的查询产生的衍生表
3、当有union result的时候,表名是union n1,n2等的形式,n1,n2表示参与union的id
type列
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行。
依次从最优到最差分别为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
NULL:mysql能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小值,可以单独查找索引来完成,不需要在执行时访问表
mysql> explain select min(id) from film;
+----+-------------+-------+------+---------------+------+---------+------+------+------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+-------+------+---------------+------+---------+------+------+------------------------------+const, system:mysql能对查询的某部分进行优化并将其转化成一个常量(可以看show warnings 的结果)。用于 primary key 或 unique key 的所有列与常数比较时,所以表最多有一个匹配行,读取1次,速度比较快。
mysql> explain extended select * from (select * from film where id = 1) tmp;
+----+-------------+------------+--------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+----------+-------+
| 1 | PRIMARY | <derived2> | system | NULL | NULL | NULL | NULL | 1 | 100.00 | NULL |
| 2 | DERIVED | film | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+------------+--------+---------------+---------+---------+-------+------+----------+-------+
mysql> show warnings;
+-------+------+---------------------------------------------------------------+
| Level | Code | Message |
+-------+------+---------------------------------------------------------------+
| Note | 1003 | /* select#1 */ select '1' AS `id`,'film1' AS `name` from dual |
+-------+------+---------------------------------------------------------------+eq_ref:primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。这可能是在 const 之外最好的联接类型了,简单的 select 查询不会出现这种 type。
mysql> explain select * from film_actor left join film on film_actor.film_id = film.id;
+----+-------------+------------+--------+---------------+-------------------+---------+-------------------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+--------+---------------+-------------------+---------+-------------------------+------+-------------+
| 1 | SIMPLE | film_actor | index | NULL | idx_film_actor_id | 8 | NULL | 3 | Using index |
| 1 | SIMPLE | film | eq_ref | PRIMARY | PRIMARY | 4 | test.film_actor.film_id | 1 | NULL |
+----+-------------+------------+--------+---------------+-------------------+---------+-------------------------+------+-------------+ref:相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。
1. 简单 select 查询,name是普通索引(非唯一索引)
mysql> explain select * from film where name = "film1";
+----+-------------+-------+------+---------------+----------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+----------+---------+-------+------+--------------------------+
| 1 | SIMPLE | film | ref | idx_name | idx_name | 33 | const | 1 | Using where; Using index |
+----+-------------+-------+------+---------------+----------+---------+-------+------+--------------------------+2.关联表查询,idx_film_actor_id是film_id和actor_id的联合索引,这里使用到了film_actor的左边前缀film_id部分。
mysql> explain select * from film left join film_actor on film.id = film_actor.film_id;
+----+-------------+------------+-------+-------------------+-------------------+---------+--------------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+-------------------+-------------------+---------+--------------+------+-------------+
| 1 | SIMPLE | film | index | NULL | idx_name | 33 | NULL | 3 | Using index |
| 1 | SIMPLE | film_actor | ref | idx_film_actor_id | idx_film_actor_id | 4 | test.film.id | 1 | Using index |
+----+-------------+------------+-------+-------------------+-------------------+---------+--------------+------+-------------+ref_or_null:类似ref,但是可以搜索值为NULL的行。
mysql> explain select * from film where name = "film1" or name is null;
+----+-------------+-------+-------------+---------------+----------+---------+-------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------------+---------------+----------+---------+-------+------+--------------------------+
| 1 | SIMPLE | film | ref_or_null | idx_name | idx_name | 33 | const | 2 | Using where; Using index |
+----+-------------+-------+-------------+---------------+----------+---------+-------+------+--------------------------+index_merge:表示使用了索引合并的优化方法。 例如下表:id是主键,tenant_id是普通索引。or 的时候没有用 primary key,而是使用了 primary key(id) 和 tenant_id 索引
mysql> explain select * from role where id = 11011 or tenant_id = 8888;
+----+-------------+-------+-------------+-----------------------+-----------------------+---------+------+------+-------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------------+-----------------------+-----------------------+---------+------+------+-------------------------------------------------+
| 1 | SIMPLE | role | index_merge | PRIMARY,idx_tenant_id | PRIMARY,idx_tenant_id | 4,4 | NULL | 134 | Using union(PRIMARY,idx_tenant_id); Using where |
+----+-------------+-------+-------------+-----------------------+-----------------------+---------+------+------+-------------------------------------------------+range:范围扫描通常出现在 in(), between ,> ,<, >= 等操作中。使用一个索引来检索给定范围的行。
mysql> explain select * from actor where id > 1;
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | actor | range | PRIMARY | PRIMARY | 4 | NULL | 2 | Using where |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+index:和ALL一样,不同就是mysql只需扫描索引树,这通常比ALL快一些。
mysql> explain select count(*) from film;
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| 1 | SIMPLE | film | index | NULL | idx_name | 33 | NULL | 3 | Using index |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+ALL:即全表扫描,意味着mysql需要从头到尾去查找所需要的行。通常情况下这需要增加索引来进行优化了
mysql> explain select * from actor;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | actor | ALL | NULL | NULL | NULL | NULL | 2 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+--all:全表扫描,一般情况下出现这样的sql语句而且数据量比较大的话那么就需要进行优化。
explain select * from emp;
--index:全索引扫描这个比all的效率要好,主要有两种情况,一种是当前的查询时覆盖索引,即我们需要的数据在索引中就可以索取,或者是使用了索引进行排序,这样就避免数据的重排序
explain select empno from emp;
--range:表示利用索引查询的时候限制了范围,在指定范围内进行查询,这样避免了index的全索引扫描,适用的操作符: =, <>, >, >=, <, <=, IS NULL, BETWEEN, LIKE, or IN()
explain select * from emp where empno between 7000 and 7500;
--index_subquery:利用索引来关联子查询,不再扫描全表
explain select * from emp where emp.job in (select job from t_job);
--unique_subquery:该连接类型类似与index_subquery,使用的是唯一索引
explain select * from emp e where e.deptno in (select distinct deptno from dept);
--index_merge:在查询过程中需要多个索引组合使用,没有模拟出来
--ref_or_null:对于某个字段即需要关联条件,也需要null值的情况下,查询优化器会选择这种访问方式
explain select * from emp e where e.mgr is null or e.mgr=7369;
--ref:使用了非唯一性索引进行数据的查找
create index idx_3 on emp(deptno);
explain select * from emp e,dept d where e.deptno =d.deptno;
--eq_ref :使用唯一性索引进行数据查找
explain select * from emp,emp2 where emp.empno = emp2.empno;
--const:这个表至多有一个匹配行,
explain select * from emp where empno = 7369;
--system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现possible_keys列
这一列显示查询可能使用哪些索引来查找。
explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。
key列
这一列显示mysql实际采用哪个索引来优化对该表的访问。
如果没有使用索引,则该列是 NULL。如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用 force index、ignore index。
实际执行中,可能用的不是这个key,可以force index强制走正确的索引,或者优化SQL,最后实在不行,可以新建索引,或者删掉错误的索引。
查询中若使用了覆盖索引,则该索引和查询的select字段重叠。
key_len列
这一列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
在不损失精度的情况下长度越短越好
举例来说,film_actor的联合索引 idx_film_actor_id 由 film_id 和 actor_id 两个int列组成,并且每个int是4字节。通过结果中的key_len=4可推断出查询使用了第一个列:film_id列来执行索引查找。
mysql> explain select * from film_actor where film_id = 2;
+----+-------------+------------+------+-------------------+-------------------+---------+-------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+------+-------------------+-------------------+---------+-------+------+-------------+
| 1 | SIMPLE | film_actor | ref | idx_film_actor_id | idx_film_actor_id | 4 | const | 1 | Using index |
+----+-------------+------------+------+-------------------+-------------------+---------+-------+------+-------------+key_len计算规则如下:
字符串
char(n):n字节长度
varchar(n):2字节存储字符串长度,如果是utf-8,则长度 3n + 2
数值类型
tinyint:1字节
smallint:2字节
int:4字节
bigint:8字节
时间类型
date:3字节
timestamp:4字节
datetime:8字节
如果字段允许为 NULL,需要1字节记录是否为 NULL
索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引。
ref列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),func,NULL,字段名(例:film.id)
如果可能的话,是一个常数
explain select * from emp,dept where emp.deptno = dept.deptno and emp.deptno = 10;rows列
这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
行数只是一个接近的数字,不是完全正确的
此参数很重要,直接反应的sql找了多少数据,在完成目的的情况下越少越好
MySQL中数据的单位都是页,MySQL又采用了采样统计的方法,采样统计的时候,InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。
我们数据是一直在变的,所以索引的统计信息也是会变的,会根据一个阈值,重新做统计。
至于MySQL索引可能走错也很好理解,如果走A索引要扫描100行,B所有只要20行,但是他可能选择走A索引,你可能会想MySQL是不是有病啊,其实不是的。
一般走错都是因为优化器在选择的时候发现,走A索引没有额外的代价,比如走B索引并不能直接拿到我们的值,还需要回到主键索引才可以拿到,多了一次回表的过程,这个也是会被优化器考虑进去的。
他发现走A索引不需要回表,没有额外的开销,所有他选错了。
如果是上面的统计信息错了,那简单,我们用analyze table tablename 就可以重新统计索引信息了,所以在实践中,如果你发现explain的结果预估的rows值跟实际情况差距比较大,可以采用这个方法来处理。
Extra列
这一列展示的是额外信息。常见的重要值如下:
distinct: 一旦mysql找到了与行相联合匹配的行,就不再搜索了
mysql> explain select distinct name from film left join film_actor on film.id = film_actor.film_id;
+----+-------------+------------+-------+-------------------+-------------------+---------+--------------+------+------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+-------------------+-------------------+---------+--------------+------+------------------------------+
| 1 | SIMPLE | film | index | idx_name | idx_name | 33 | NULL | 3 | Using index; Using temporary |
| 1 | SIMPLE | film_actor | ref | idx_film_actor_id | idx_film_actor_id | 4 | test.film.id | 1 | Using index; Distinct |
+----+-------------+------------+-------+-------------------+-------------------+---------+--------------+------+------------------------------+Using index:这发生在对表的请求列都是同一索引的部分的时候,返回的列数据只使用了索引中的信息,而没有再去访问表中的行记录。是性能高的表现。
mysql> explain select id from film order by id;
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+
| 1 | SIMPLE | film | index | NULL | PRIMARY | 4 | NULL | 3 | Using index |
+----+-------------+-------+-------+---------------+---------+---------+------+------+-------------+ Using where:mysql服务器将在存储引擎检索行后再进行过滤。就是先读取整行数据,再按 where 条件进行检查,符合就留下,不符合就丢弃。
mysql> explain select * from film where id > 1;
+----+-------------+-------+-------+---------------+----------+---------+------+------+--------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+--------------------------+
| 1 | SIMPLE | film | index | PRIMARY | idx_name | 33 | NULL | 3 | Using where; Using index |
+----+-------------+-------+-------+---------------+----------+---------+------+------+--------------------------+Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
1. actor.name没有索引,此时创建了张临时表来distinct
mysql> explain select distinct name from actor;
+----+-------------+-------+------+---------------+------+---------+------+------+-----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-----------------+
| 1 | SIMPLE | actor | ALL | NULL | NULL | NULL | NULL | 2 | Using temporary |
+----+-------------+-------+------+---------------+------+---------+------+------+-----------------+2. film.name建立了idx_name索引,此时查询时extra是using index,没有用临时表
mysql> explain select distinct name from film;
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| 1 | SIMPLE | film | index | idx_name | idx_name | 33 | NULL | 3 | Using index |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+Using filesort:mysql 会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。此时mysql会根据联接类型浏览所有符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息。这种情况下一般也是要考虑使用索引来优化的。
1. actor.name未创建索引,会浏览actor整个表,保存排序关键字name和对应的id,然后排序name并检索行记录
mysql> explain select * from actor order by name;
+----+-------------+-------+------+---------------+------+---------+------+------+----------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+----------------+
| 1 | SIMPLE | actor | ALL | NULL | NULL | NULL | NULL | 2 | Using filesort |
+----+-------------+-------+------+---------------+------+---------+------+------+----------------+2. film.name建立了idx_name索引,此时查询时extra是using index
mysql> explain select * from film order by name;
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+
| 1 | SIMPLE | film | index | NULL | idx_name | 33 | NULL | 3 | Using index |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-------------+--using filesort:说明mysql无法利用索引进行排序,只能利用排序算法进行排序,会消耗额外的位置
explain select * from emp order by sal;
--using temporary:建立临时表来保存中间结果,查询完成之后把临时表删除
explain select ename,count(*) from emp where deptno = 10 group by ename;
--using index:这个表示当前的查询时覆盖索引的,直接从索引中读取数据,而不用访问数据表。如果同时出现using where 表名索引被用来执行索引键值的查找,如果没有,表面索引被用来读取数据,而不是真的查找
explain select deptno,count(*) from emp group by deptno limit 10;
--using where:使用where进行条件过滤
explain select * from t_user where id = 1;
--using join buffer:使用连接缓存,情况没有模拟出来
--impossible where:where语句的结果总是false
explain select * from emp where empno = 7469;使用的表
以上所有sql使用的表和数据:
DROP TABLE IF EXISTS `actor`;
CREATE TABLE `actor` (
`id` int(11) NOT NULL,
`name` varchar(45) DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `actor` (`id`, `name`, `update_time`) VALUES (1,'a','2017-12-22 15:27:18'), (2,'b','2017-12-22 15:27:18'), (3,'c','2017-12-22 15:27:18');
DROP TABLE IF EXISTS `film`;
CREATE TABLE `film` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `film` (`id`, `name`) VALUES (3,'film0'),(1,'film1'),(2,'film2');
DROP TABLE IF EXISTS `film_actor`;
CREATE TABLE `film_actor` (
`id` int(11) NOT NULL,
`film_id` int(11) NOT NULL,
`actor_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_film_actor_id` (`film_id`,`actor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `film_actor` (`id`, `film_id`, `actor_id`) VALUES (1,1,1),(2,1,2),(3,2,1);边栏推荐
- Leetcode 200.岛屿数量 BFS
- Multifunctional Nanozyme Ag/PANI | Flexible Substrate Nano ZnO Enzyme | Rhodium Sheet Nanozyme | Ag-Rh Alloy Nanoparticle Nanozyme | Iridium Ruthenium Alloy/Iridium Oxide Biomimetic Nanozyme
- LeetCode questions 1-10
- 转铁蛋白Tf功能化β-榄香烯-雷公藤红素/紫杉醇PLGA纳米粒/雷公藤甲素脂质体(化学试剂)
- 从 Delta 2.0 开始聊聊我们需要怎样的数据湖
- Ransom Letter Questions and Answers
- .NET现代应用的产品设计 - DDD实践
- Site Architecture Detection & Chrome Plugin for Information Gathering
- Transferrin-modified vincristine-tetrandrine liposomes | transferrin-modified co-loaded paclitaxel and genistein liposomes (reagents)
- FEMRL: A Framework for Large-Scale Privacy-Preserving Linkage of Patients’ Electronic Health Rec Paper Summary
猜你喜欢
Transferrin (TF) Modified Paclitaxel (PTX) Liposomes (TF-PTX-LP) | Transferrin (Tf) Modified Curcumin Liposomes
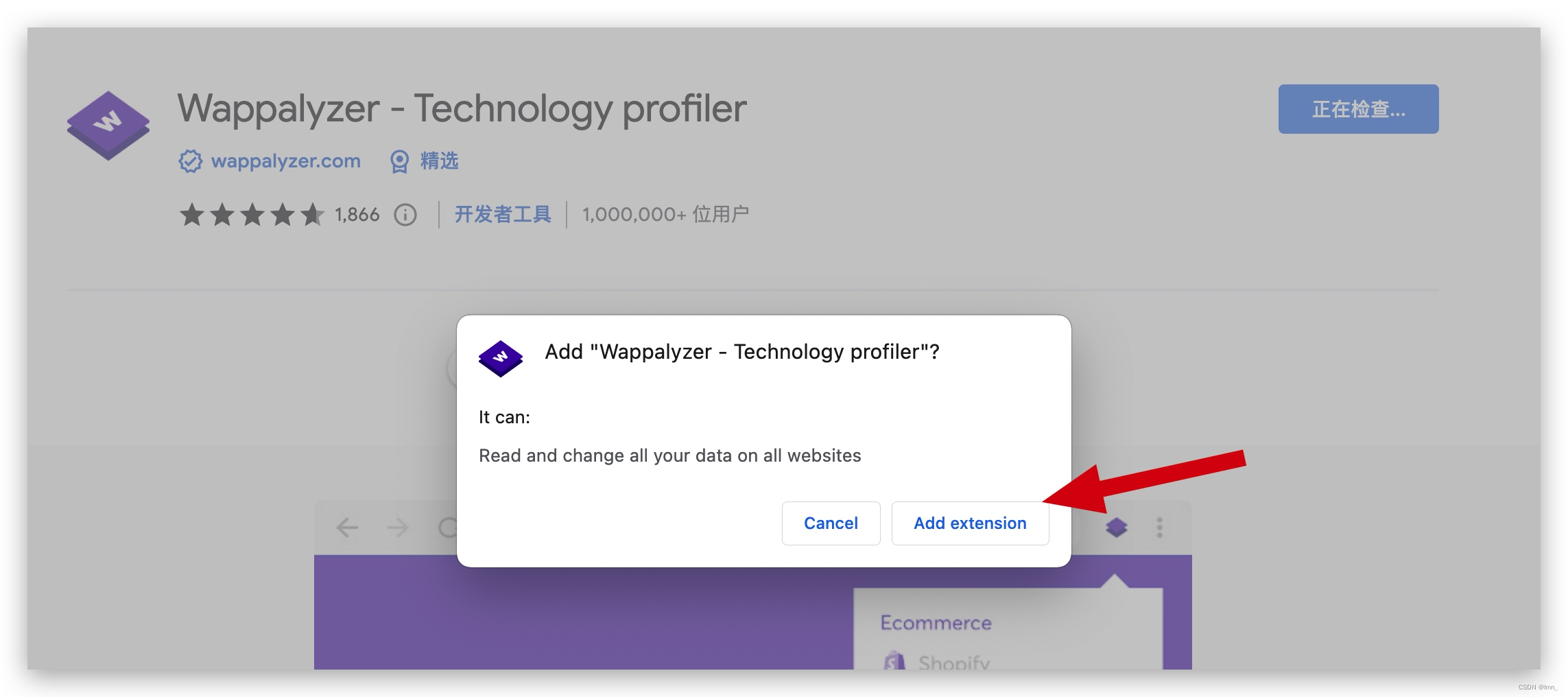
Site Architecture Detection & Chrome Plugin for Information Gathering
铁蛋白颗粒负载雷替曲塞/培美曲塞/磺胺地索辛/金刚烷(科研试剂)
赎金信问题答记
2019河北省大学生程序设计竞赛部分题题解
Hangdian Multi-School Seven 1003-Counting Stickmen (Combination Mathematics)
C语言系列——猜名次、猜凶手、打印杨辉三角
每日一R「03」Borrow 语义与引用
Tf ferritin particles contain cisplatin / oxaliplatin / doxorubicin / methotrexate MTX / paclitaxel PTX and other drugs
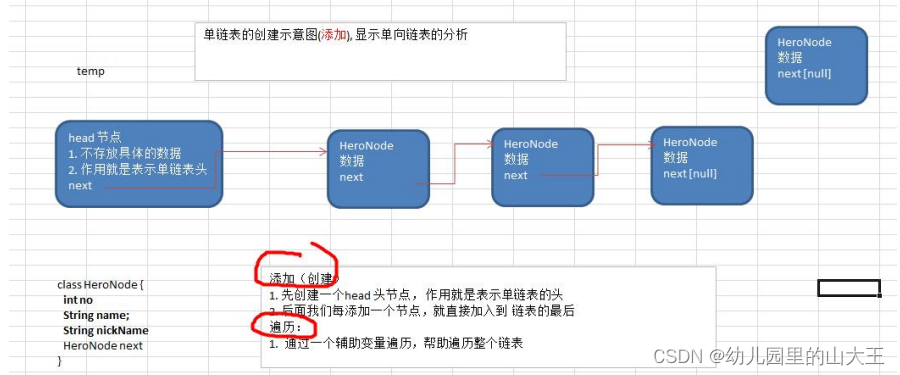
线性结构----链表
随机推荐
论文解读(g-U-Nets)《Graph U-Nets》
通用线程:POSIX 线程详解,第 2部分
指针常量和常量指针
CMU博士论文 | 视频多模态学习:探索模型和任务复杂性
力扣18-四数之和——双指针法
多线程与高并发(五)—— 源码解析 ReentrantLock
线性结构----链表
2020 ICPC Shanghai Site G
echart 特例-多分组X轴
Tf铁蛋白颗粒包载顺铂/奥沙利铂/阿霉素/甲氨蝶呤MTX/紫杉醇PTX等药物
Transferrin (TF) Modified Paclitaxel (PTX) Liposomes (TF-PTX-LP) | Transferrin (Tf) Modified Curcumin Liposomes
怎么完全卸载赛门铁克_Symantec卸载方法,赛门铁克卸载「建议收藏」
苹果字体查找
Site Architecture Detection & Chrome Plugin for Information Gathering
重载和重写
Tf ferritin particles contain cisplatin / oxaliplatin / doxorubicin / methotrexate MTX / paclitaxel PTX and other drugs
Pt/CeO2 monatomic nanoparticles enzyme | H - rGO - Pt @ Pd NPs enzyme | carbon nanotube load platinum nanoparticles peptide modified nano enzyme | leukemia antagonism FeOPtPEG composite nano enzyme
whois information collection & corporate filing information
leetcode 85.最大矩形 单调栈应用
你不知道的浏览器页面渲染机制