当前位置:网站首页>【语义分割】2016-SegNet TPAMI
【语义分割】2016-SegNet TPAMI
2022-08-10 19:12:00 【說詤榢】
【语义分割】2016-SegNet TPAMI
论文题目:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
论文链接:https://arxiv.org/abs/1511.00561
论文代码:
发表时间:2015年11月
引用:Badrinarayanan V, Kendall A, Cipolla R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(12): 2481-2495.
引用数:11939
1. 简介
1.1 简介
SegNet之前,语义分割的许多方法都是直接采用设计图像分类的方法去解决,虽然有时获得的结果还说得过去,但总体来说比较粗糙。其实很容易理解为什么,在图像分类的过程中,我们都是将特征图进行多次卷积与max pooling,并进行展开为全连接层,最终依赖softmax等函数进行概率的计算,在此过程中,图像经过一系列下采样早已经失去了边界信息,边界信息的丢失对于图像分类没有什么影响,但是图像分割就不一样了,它需要根据边界来细致的将某个物体分割出来。基于这个大背景下,又借鉴了FCN与U-Net结构,作者提出了SegNet。
2. 网络
2.1 整体架构
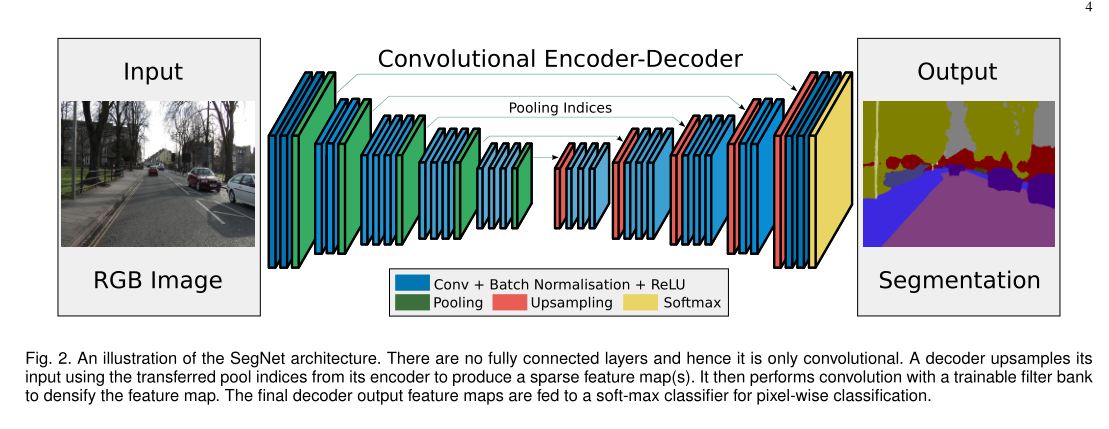
SetNet是由Vijay、Alex等人发表在IEEE上的一种deep convolutional encoder-decoder 结构的图像分割方法。
- 该分割的核心训练部分包含一个
encoder network,一个相对应的decoder network,最后是一个逐像素的分类层。 - 其中encoder network使用的是VGG16中的前13层卷积网络结构,只是添加了少许改动。
- decoder network的作用在于将原图像经由encoder network计算出的feature maps从低分辨率映射到和原图尺寸一致的分辨率以便于做逐像素的分类处理。
而SegNet的创新就在于其decoder net对低分辨率的feature map(s)做上采样(upsample)的一个设计。
其方法是,在encoder的每一个max-pooling过程中保存其池化索引(最大值的index),在decoder层使用这些得到的索引来做非线性上采样。
这些经过上采样的特征图是稀疏的,再对其做可训练的卷积操作产生密集feature maps,最后将其送入multi-class softmax分类器中进行分类。
2.2 encoder
SegNet就是使用了VGGNet16的前13个卷积层,去除了对应的全连接层,和我们现在的主干网络类似,卷积层+BN层+ReLU层,Encoder就是获取图像的高阶语义特征,这里需要注意的是SegNet会保留每一次max pooling的位置(即2x2的区域->1x1的区域,所对应的位置)
2.3 Decoder编码器
上采样当中存在着一个不确定性,即一个1x1的特征点经过上采样将会变成一个2x2特征区域,这个区域中的某个1x1区域将会被原来的1x1特征点取代,其他的三个区域为空。但是哪个1x1区域会被原特征点取代呢?一个做法就是随机将这个特征点分配到任意的一个位置,或者干脆给它分配到一个固定的位置。但是这样做无疑会引入一些误差,并且这些误差会传递给下一层。层数越深,误差影响的范围也就越大。所以把1x1特征点放到正确的位置至关重要。
SegNet通过一个叫Pooling Indices方式来保存池化点的来源信息。在Encoder的池化层处理中,会记录每一个池化后的1x1特征点来源于之前的2x2的哪个区域,在这个信息在论文中被称为Pooling Indices。Pooling Indices会在Decoder中使用。既然SegNet是一个对称网络,那么在Decoder中需要对特征图进行上采样的时候,我们就可以利用它对应的池化层的Pooling Indices来确定某个1x1特征点应该放到上采样后的2x2区域中的哪个位置。此过程的如下图所示。
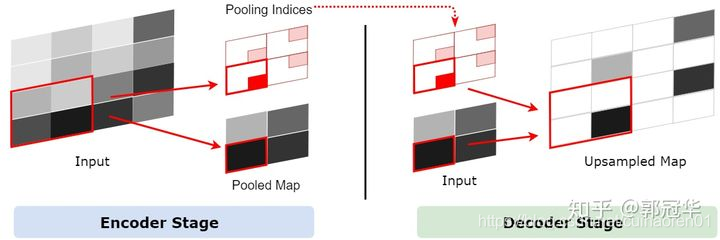
在这里说明下和UNet和Deconv的区别:
与U-Net的区别:
U-Net没有利用池化位置索引信息,而是将编码阶段的整个特征图传输到相应的解码器(以牺牲更多内存为代价),并将其连接,再进行上采样(通过反卷积),从而得到解码器特征图。与Deconv的区别:
Deconvnet具有更多的参数,需要更多的计算资源,并且很难进行端到端训练,主要是因为使用了全连接层。
import numpy as np
a = [[1,2,1,2], [3,4,3,4],[1,2,1,2],[3,4,3,4]]
b = torch.Tensor(a) # 初始化tensor
print(b)
--------------------------------------------------------------------------
Output:
tensor([[1., 2., 1., 2.],
[3., 4., 3., 4.],
[1., 2., 1., 2.],
[3., 4., 3., 4.]])
---------------------------------------------------------------------------
import torch.nn as nn
pool_test = nn.MaxPool2d(2, 2, return_indices=True, ceil_mode=True)
b = b.reshape(1, 1, 4, 4)
c, inx = pool_test(b) # 对tensor进行max_pooling
print(c)
print(inx)
---------------------------------------------------------------------------
Output:
c: tensor([[[[4., 4.],
[4., 4.]]]])
inx : tensor([[[[ 5, 7],
[13, 15]]]])
---------------------------------------------------------------------------
unpool_test = nn.MaxUnpool2d(2, 2)
shape_b = b.size()[2:]
up = unpool_test(c, inx, shape_b)
print(up)
print(b + up)
---------------------------------------------------------------------------
Output:
up : tensor([[[[0., 0., 0., 0.],
[0., 4., 0., 4.],
[0., 0., 0., 0.],
[0., 4., 0., 4.]]]])
up + b : tensor([[[[1., 2., 1., 2.],
[3., 8., 3., 8.],
[1., 2., 1., 2.],
[3., 8., 3., 8.]]]])
3. 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from collections import OrderedDict
class SegNet(nn.Module):
def __init__(self,input_nbr,label_nbr):
super(SegNet, self).__init__()
batchNorm_momentum = 0.1
self.conv11 = nn.Conv2d(input_nbr, 64, kernel_size=3, padding=1)
self.bn11 = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv12 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn12 = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv21 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn21 = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv22 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn22 = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv31 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.bn31 = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv32 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn32 = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv33 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn33 = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv41 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.bn41 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv42 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn42 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv43 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn43 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv51 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn51 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv52 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn52 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv53 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn53 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv53d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn53d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv52d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn52d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv51d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn51d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv43d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn43d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv42d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn42d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv41d = nn.Conv2d(512, 256, kernel_size=3, padding=1)
self.bn41d = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv33d = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn33d = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv32d = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn32d = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv31d = nn.Conv2d(256, 128, kernel_size=3, padding=1)
self.bn31d = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv22d = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn22d = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv21d = nn.Conv2d(128, 64, kernel_size=3, padding=1)
self.bn21d = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv12d = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn12d = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv11d = nn.Conv2d(64, label_nbr, kernel_size=3, padding=1)
def forward(self, x):
# Stage 1
x11 = F.relu(self.bn11(self.conv11(x)))
x12 = F.relu(self.bn12(self.conv12(x11)))
x1p, id1 = F.max_pool2d(x12,kernel_size=2, stride=2,return_indices=True)
# Stage 2
x21 = F.relu(self.bn21(self.conv21(x1p)))
x22 = F.relu(self.bn22(self.conv22(x21)))
x2p, id2 = F.max_pool2d(x22,kernel_size=2, stride=2,return_indices=True)
# Stage 3
x31 = F.relu(self.bn31(self.conv31(x2p)))
x32 = F.relu(self.bn32(self.conv32(x31)))
x33 = F.relu(self.bn33(self.conv33(x32)))
x3p, id3 = F.max_pool2d(x33,kernel_size=2, stride=2,return_indices=True)
# Stage 4
x41 = F.relu(self.bn41(self.conv41(x3p)))
x42 = F.relu(self.bn42(self.conv42(x41)))
x43 = F.relu(self.bn43(self.conv43(x42)))
x4p, id4 = F.max_pool2d(x43,kernel_size=2, stride=2,return_indices=True)
# Stage 5
x51 = F.relu(self.bn51(self.conv51(x4p)))
x52 = F.relu(self.bn52(self.conv52(x51)))
x53 = F.relu(self.bn53(self.conv53(x52)))
x5p, id5 = F.max_pool2d(x53,kernel_size=2, stride=2,return_indices=True)
# Stage 5d
x5d = F.max_unpool2d(x5p, id5, kernel_size=2, stride=2)
x53d = F.relu(self.bn53d(self.conv53d(x5d)))
x52d = F.relu(self.bn52d(self.conv52d(x53d)))
x51d = F.relu(self.bn51d(self.conv51d(x52d)))
# Stage 4d
x4d = F.max_unpool2d(x51d, id4, kernel_size=2, stride=2)
x43d = F.relu(self.bn43d(self.conv43d(x4d)))
x42d = F.relu(self.bn42d(self.conv42d(x43d)))
x41d = F.relu(self.bn41d(self.conv41d(x42d)))
# Stage 3d
x3d = F.max_unpool2d(x41d, id3, kernel_size=2, stride=2)
x33d = F.relu(self.bn33d(self.conv33d(x3d)))
x32d = F.relu(self.bn32d(self.conv32d(x33d)))
x31d = F.relu(self.bn31d(self.conv31d(x32d)))
# Stage 2d
x2d = F.max_unpool2d(x31d, id2, kernel_size=2, stride=2)
x22d = F.relu(self.bn22d(self.conv22d(x2d)))
x21d = F.relu(self.bn21d(self.conv21d(x22d)))
# Stage 1d
x1d = F.max_unpool2d(x21d, id1, kernel_size=2, stride=2)
x12d = F.relu(self.bn12d(self.conv12d(x1d)))
x11d = self.conv11d(x12d)
return x11d
def load_from_segnet(self, model_path):
s_dict = self.state_dict()# create a copy of the state dict
th = torch.load(model_path).state_dict() # load the weigths
# for name in th:
# s_dict[corresp_name[name]] = th[name]
self.load_state_dict(th)
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
model=SegNet(input_nbr=3,label_nbr=19)
y=model(x)
print(y.shape)
边栏推荐
- 洛谷 P1629 邮递员送信 (三种最短路)
- flask装饰器版登录、session
- 常见端口及服务
- WCF and TCP message communication practice, c # 】 【 realize group chat function
- 【luogu CF1534F2】Falling Sand (Hard Version)(性质)(dfs)(线段树 / 单调队列 / 贪心)
- uni-app 数据上拉加载更多功能
- Hangdian Multi-School Seven 1003-Counting Stickmen (Combination Mathematics)
- [Go WebSocket] 你的第一个Go WebSocket服务: echo server
- 链表应用----约瑟夫问题
- Ransom Letter Questions and Answers
猜你喜欢

2022 Hangdian Multi-School Seven Black Magic (Sign-in)
Ferritin particle-loaded raltitrexed/pemetrexed/sulfadesoxine/adamantane (scientific research reagent)
[Go WebSocket] 你的第一个Go WebSocket服务: echo server
Metasploit——渗透攻击模块(Exploit)
Apple Font Lookup
Echart饼状图标注遮盖解决方案汇总
巧用RoaringBitMap处理海量数据内存diff问题

leetcode 547.省份数量 并查集
从 GAN 到 WGAN
Rider调试ASP.NET Core时报thread not gc-safe的解决方法
![[Go WebSocket] 你的第一个Go WebSocket服务: echo server](/img/ac/a5f0a9b9e97470c4c74c5ca84383ab)
随机推荐
多线程与高并发(五)—— 源码解析 ReentrantLock
Tf ferritin particles contain cisplatin / oxaliplatin / doxorubicin / methotrexate MTX / paclitaxel PTX and other drugs
nfs挂载服务器,解决挂载后无法更改用户id,无法修改、写文件,文件只读权限Read-only file system等问题
【无标题】基于Huffman和LZ77的GZIP压缩
优化是一种习惯●出发点是'站在靠近临界'的地方
烟雾、空气质量、温湿度…自己徒手做个环境检测设备
Solution for thread not gc-safe when Rider debugs ASP.NET Core
[SemiDrive source code analysis] [MailBox inter-core communication] 51 - DCF_IPCC_Property implementation principle analysis and code combat
IIC通信协议总结[通俗易懂]
idea插件 协议 。。 公司申请软件用
zip文件协议解析
FEMRL: A Framework for Large-Scale Privacy-Preserving Linkage of Patients’ Electronic Health Rec Paper Summary
QoS Quality of Service Six Router Congestion Management
【LeetCode】42、接雨水
keepalived:故障检测自动修复脚本
杭电多校七 1003-Counting Stickmen(组合数学)
Rider调试ASP.NET Core时报thread not gc-safe的解决方法
laya打包发布apk
Leetcode 200.岛屿数量 BFS
YOLOv3 SPP source analysis