当前位置:网站首页>基于深度学习的三维点云分割综述
基于深度学习的三维点云分割综述
2022-08-10 22:40:00 【3D_vision】
传统的点云分割方法包括:
- 基于边缘检测的方法
- 基于区域增长的算法
- 基于特征聚类的算法
- 基于模型拟合的算法
- 基于图形的算法
深度学习方法相对于传统方法的优势:
传统方法过分依赖于人工设计的特征,成本高,计算量大,并且普适性差,在面向大数据集时表现不佳。
三维点云数据集:
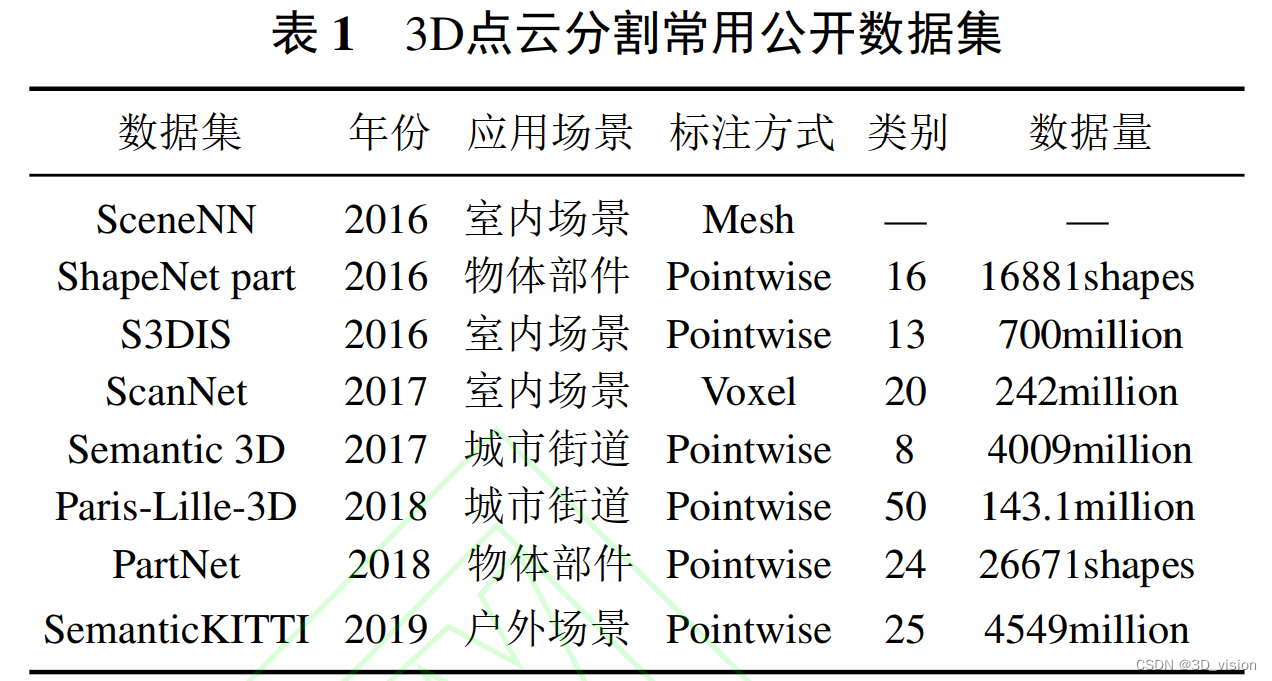
点云模型的评价指标:
评价指标用于 分割算法 之间的性能比较,包括:平均交并比(mIoU)、总体分割精度(Overall Accuracy,OA)、平均精确率(mean Accuracy Precision,mAP)、参数量(Parameters)和每秒的浮点运算数(FLOPs)等。
- TP(True Positive) 预测为正样本且是预测结果是正确。
- FP(False Positive) 预测为正样本但是预测结果错误。
- FN(False Negative) 预测结果为负样本但是预测结果错误。
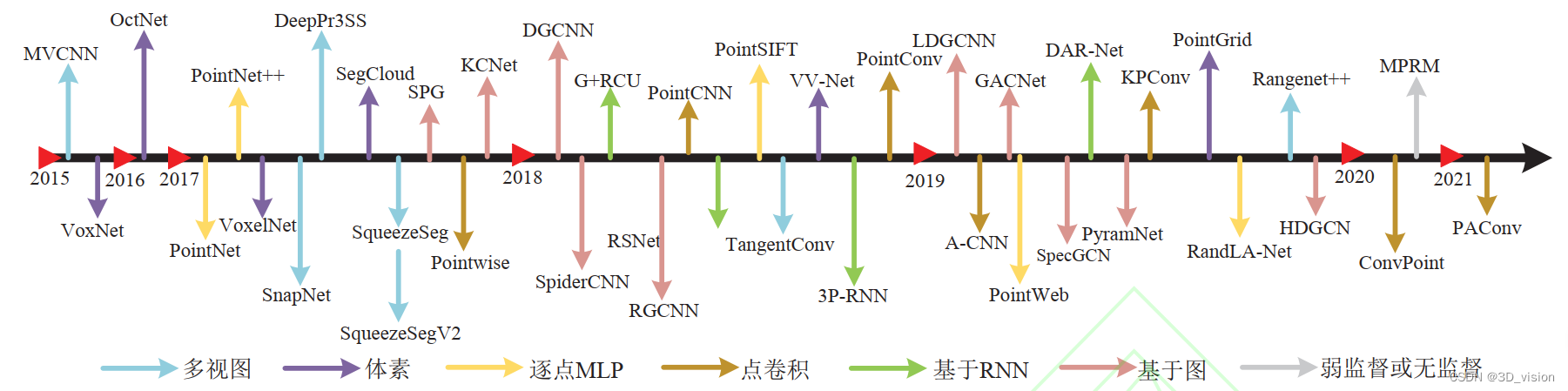
3D点云语义分割方法发展脉络
基于体素化的方法
基于体素化的方法是一种结构化的表示方法,其将无序的点云分割成一系列占用一定空间的体素,然后送入3D CNN逐步进行体素级别的特征学习,最后为每一格体素内的所有点匹配与该体素相同的语义标签。该方法有效地促进无序点云规则化,但是存在较高的计算和内存成本。
基于多视图的方法
多视图方法将一个3D对象按照多个角度投影成多个2D视图并提取各视图特征,然后融合这些特征以预测结果。
这种方法一个比较经典的网络就是MVCNN。它模拟相机从若干不同角度获取3D物体的2D图像,再利用预训练CNN模型提取特征,最后通过全局最大池化将不同视角的特征聚合达到形状识别的目的。
但是该方法所提取的特征冗余性很高,且没有很好的考虑多视角下的特征之间的关系。
基于点云的方法
1.基于多层感知机MLP的方法PointNet直接将3D点云作为输入,引入T-Net结构实现点云的旋转不变,利用共享的多层感知机(MLP)提取输入的每个点的特征,通过最大池化将所有点的信息聚合得到全局特征。该方法有效改善了原始点云旋转不变性差的问题,广泛应用于分类、部件分割和语义分割等任务。
但存在过分关注全局特征而忽略局部特征的问题,没有考虑点与点之间的结构信息,也没有充分考虑到点云密度不均匀所造成的不利影响等问题,难以适应复杂场景。
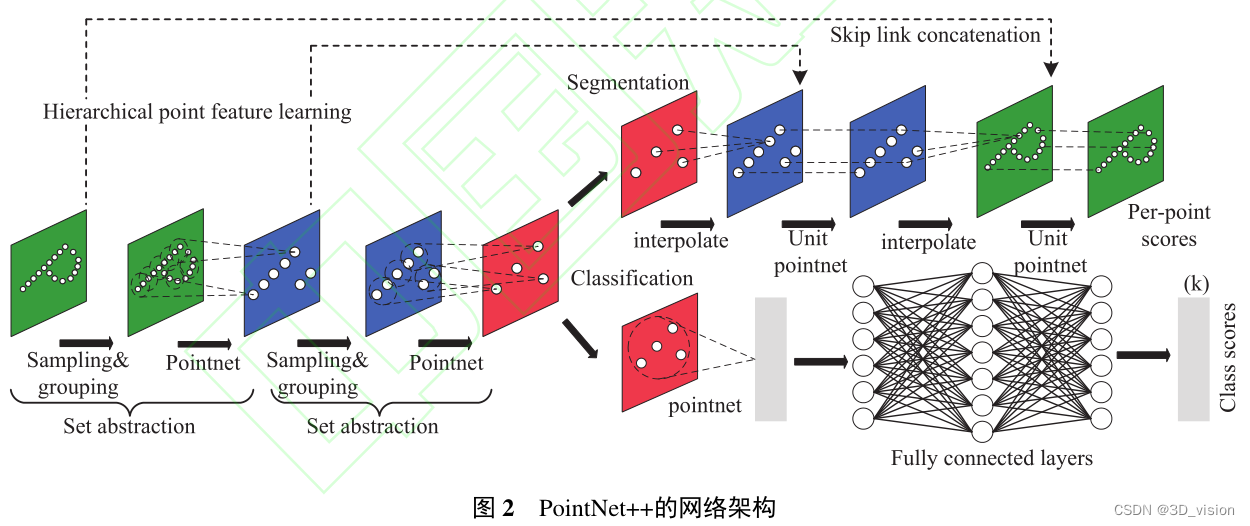
针对以上问题, 在PointNet基础上进一步提出了PointNet++。如图2所示,该方法通过层级下采样来捕捉局部几何细节信息。此外,该方法还提出了多尺度分组和多分辨率分组的策略,以克服由于点云数据密度不均匀引起的稀疏点信息可能被忽视问题。虽然有效解决了PointNet在采样和特征提取方法上存在的问题,但仍然没有充分考虑如何有效利用点与点之间的结构信息,且所采用的K近邻搜索方法可能使得采样点集中在一个方向上,容易出现标签错分。
2.点卷积的方法
代表作:PointCNN,PointConv。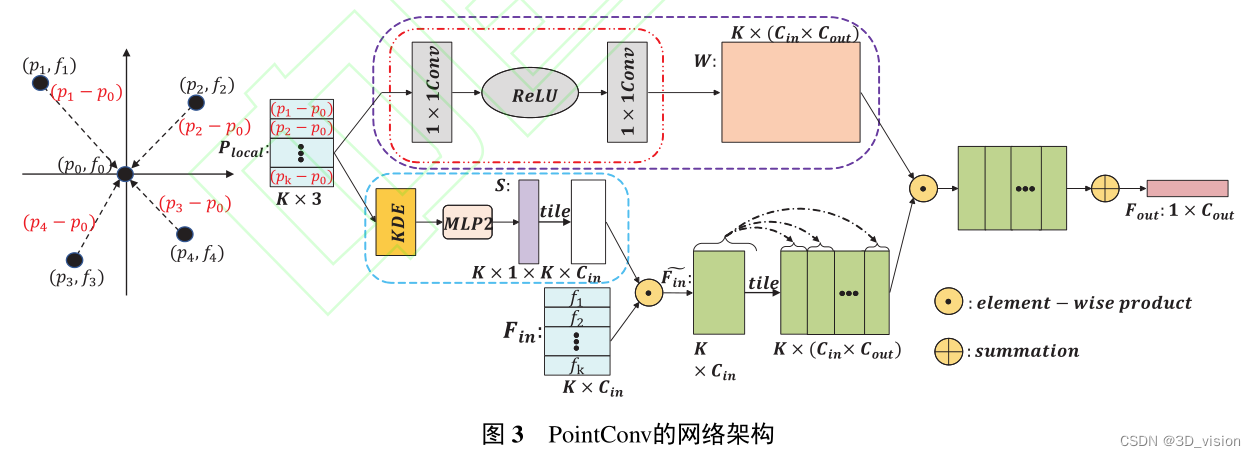
3.基于RNN的方法
将循环神经网络应用于3D点云语义分割模型。
4.基于图卷积的方法
基于图卷积的点云语义分割将点云中的每个点视为图的顶点,与邻域点生成图有向边,在空间域或频谱域中学习点、边特征,以捕获3D点云的局部几何结构特征。
代表作:DGCNN
DGCNN提出了一个用于学习边缘特征的边缘卷积(EdgeConv),通过构建局部邻域图和对每条邻边进行EdgeConv操作,动态更新层级之间的图结构。EdgeConv可以捕捉到每个点与其邻域点的距离信息。
但是同样DGCNN忽视了相邻点之间向量的方向信息,忽略了一些结构信息。
边栏推荐
- 解析方法的参数列表(包含参数名称)
- 高学历毕业生,该学单片机还是plc?
- LeetCode每日两题01:反转字符串 (均1200道)方法:双指针
- leetcode:357. 统计各位数字都不同的数字个数
- 云服务器基于 SSH 协议实现免密登录
- Distribution Network Expansion Planning: Consider Decisions Using Probabilistic Energy Production and Consumption Profiles (Matlab Code Implementation)
- 实例053:按位异或
- What would happen if disconnecting during the process of TCP connection?
- 虚拟地址空间
- Power system power flow calculation (Newton-Raphson method, Gauss-Seidel method, fast decoupling method) (Matlab code implementation)
猜你喜欢
RecyclerView滑动监听
![Research on multi-element N-k fault model of power system based on AC power flow (implemented by Matlab code) [Power System Fault]](/img/d0/13ae2b9987a4fff6f28607a0c01b58.gif)
Research on multi-element N-k fault model of power system based on AC power flow (implemented by Matlab code) [Power System Fault]

合并k个已排序的链表

实例055:按位取反

风控逻辑利器---规则引擎
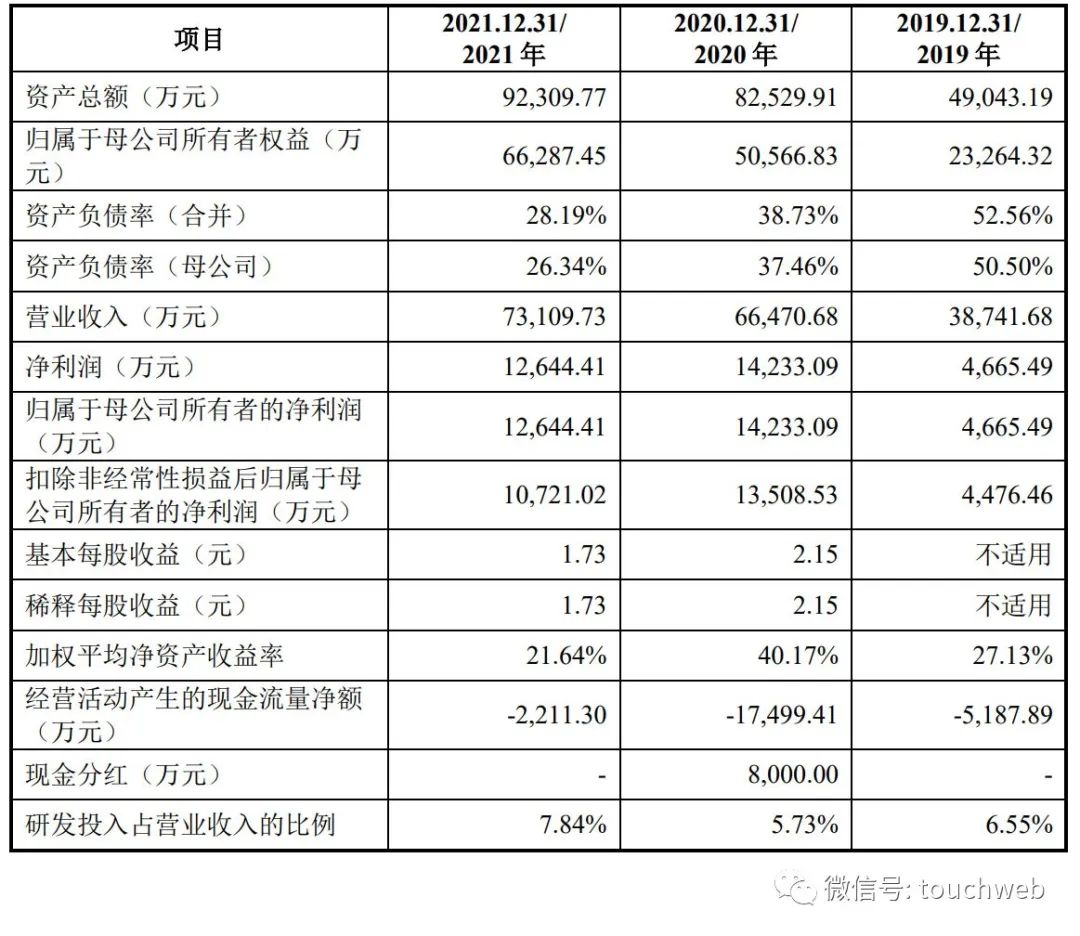
德科立科创板上市:年营收7.3亿 市值59亿

实例051:按位与
Power system power flow calculation (Newton-Raphson method, Gauss-Seidel method, fast decoupling method) (Matlab code implementation)
How to be a Righteous Hacker?What should you study?
Redis
随机推荐
N1BOOK writeup
【软件测试】2022年最火的十大测试工具,你掌握了几个
STL-deque
Glide监听Activity生命周期源码分析
Introduction to the use of counter instructions in Rockwell AB PLC RSLogix5000
TCP连接过程中如果拔掉网线会发生什么?
RK3399平台开发系列讲解(内核驱动外设篇)6.35、IAM20680陀螺仪介绍
gcc492 compile `.rodata‘ can not be used when making a PIE object; recompile with -fPIE
Detailed installation steps and environment configuration of geemap
数学建模准备知识
LeetCode每日两题02:反转字符串中的单词 (均1200道)
虎牙自动发弹幕换牌子
PlaidCTF 2022 Amongst Ourselves:Shipmate writeup
What would happen if disconnecting during the process of TCP connection?
一、ICESat-2数据查询,下载,与处理
诺诚健华通过注册:施一公家族身价15亿 高瓴浮亏5亿港元
文件IO-缓冲区
JS中使用正则表达式g模式和非g模式的区别
RK3399 platform development series explanation (kernel-driven peripherals) 6.35, IAM20680 gyroscope introduction
常用代码扩展点设计方式