当前位置:网站首页>干货!迈向鲁棒的测试时间适应
干货!迈向鲁棒的测试时间适应
2022-08-09 22:11:00 【AITIME论道】
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

通过自监督学习进行测试时间训练(TTT)是一种解决分布变化的新兴范式。尽管取得了令人鼓舞的结果,目前尚不清楚这种方法何时有效或失败。
在这项工作中,我们首先深入研究了这类方法的局限性,发现存在严重分布变化的情况下,TTT可能会恶化而不是改善模型性能。为
了解决这个问题,我们引入了一种利用离线特征总结和在线矩匹配的测试时特征对齐策略,以实现稳健的矩估计。
此外,我们通过理论分析阐明TTT的巨大潜力,并提出改进版的测试时间训练,称为TTT++,在多个视觉基准测试中显着优于此前方法。我们的结果表明,利用以紧凑形式存储的额外信息,对于测试时算法的设计至关重要。
本期AI TIME PhD直播间,我们邀请到洛桑理工学院(EPFL)在读博士生——刘越江,为我们带来报告分享《迈向鲁棒的测试时间适应》。

刘越江:
洛桑理工学院(EPFL)在读博士生,主要研究方向为针对跨环境泛化或迁移的表征学习,包含自监督学习、因果表征学习、测试时间训练,以第一作者在NeurIPS、ICCV、AAAI等发表多篇论文。
1
Machine Learning Achievements
首先,让我们回顾一下机器学习领域近些年取得的进展和目前的局限。众所周知,通过在大量数据中训练深度神经网络,我们在很多问题中已经能得到非常强大的深度模型。比如说图像识别、自动驾驶和语音识别等。

在这些问题中,标准的benchmark上的深度模型甚至能够超过人类的智力水平。并且机器学习模型的发展速度仍在不断加快。

不过,这些方法仍然存在很多局限。
Fundamental Challenges
局限之一就是这些方法往往依赖于I.I.D假设:简单来说,我们假设训练数据与测试数据来源于同样的环境和数据分布。

但是对于真实数据中的实际问题,假设往往是不成立的,可能会出现各种类型的分布变化。

比如说对于图像问题,可能会出现光线和天气的变化或者随机噪声。对于自动驾驶的问题,开环训练和闭环部署的差异也可能会导致变化。比如说,在测试过程中不断累积的预测误差可能会导致出现训练中从未出现过的危险场景。

Clear Gap between ID and OOD

针对这个OD问题,说明非常微小的环境变化也可能导致性能的显著下降。比如在上图中,红色部分是In-dist和Out-of-dist的结果差异,在很多子数据上OOD环境的准确性都会有明显的下降。
2
How to address distributional shifts?
我们该如何解决分布变化带来的影响?
Existing Approaches
针对上述问题,目前有三种主流的方法。第一种是Domain Generalization。
目标是训练一个模型,可以直接泛化到和训练场景不同但是相关联的新环境。这种方法通常需要对环境变化进行预判和假设,但是这些假设在真实场景之中未必能够成立。
另一种相对更容易处理的方法是Domain Adaptation,这种方法的目标将带标签的训练集和无标签的测试集去寻找一个特征空间,并在空间上尽量消除特征分布的差异。但是这个方法也存在一个明显的不足,因为是需要测试数据与训练数据同时存在,这在很多实际场景之中是很难实现的。

有没有什么方法可以兼顾上述两种方法的优点呢?Test-time Adaptation,这类方法的目标是在训练结束之后不再使用训练数据的前提下,根据测试样本在线的对模型进行更新。
其中一大优势是不需要像Domain Generalization一样对测试环境进行预先假设,也不需要像Domain Adaptation一样需要依赖于训练数据。

这个方向最近已经涌现了许多有意思的想法,同时也暴露了许多问题。
下面我们看一个最近比较流行的方法,Test-time Training(TTT)。
我们引入一个自监督的任务,然后在主任务和自监督的任务中同时训练order,然后在测试的时候环境发生了变化,即使没有主任务的标签,我们也可以使用自监督的方式对encoder进行更新。

什么情况会使得Test-time Training(TTT)模型变得更差呢?我们在接下来讨论了这种方法在怎样的情况下有可能会失败。
Limitations of TTT
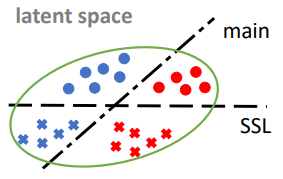
我们首先看下,设想问题目标是要构建一个针对下图数据点颜色的二分类器。在训练过程中引入一个与主任务相关的自监督任。在这个自监督任务中,我们用数据点的形式表示其标签。通过在两个任务中同时训练,我们有可能得到一个encoder使得在Latent Space这个特征空间中形成4个分类器。无论是对于主任务还是自监督任务而言,这些feature都能够被准确的进行线性的分割。
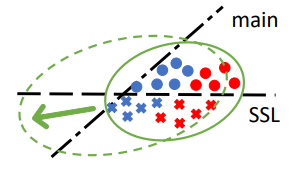
接下来,我们考虑测试环境。当训练环境与测试环境出现差异的时候,预训练模型可能在两个环节都出现错误。在这种情况下,我们通过自监督的方式对模型进行调整,特别是对encoder进行调整。这些数据点在空间中会集体下移,使得他们能够满足自监督的需求,但是在主任务中他们的准确率会不升反降。原因在于TTT这个方法的目标函数直接的去考虑是否能够缩小环境变化对数据分布的影响;与之相反,该方法可能会放大数据分布在空间中的差异,导致在主任务中的准确性会进一步下降。

为了解决上述问题,我们提出了特征机型在线对齐。这个方法主要分为两步:
● Offline feature summarization
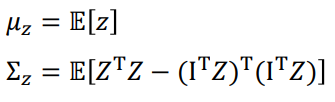
测试的时候,我们选择了在线的feature对齐,目的是使数据在特征空间中的分别尽可能地接近。
● Online moment matching

当然,这种方法也存在着不足,即其很难扩展到其他类型的问题之中。

为了解决上述问题,我们借鉴了对比学习的思路引入了动态特征队列。
我们要维护一个包含多个batch的buffer,在这个buffer里动态更新特征向量。

3
When Does TTT Thrive?
我们对方法进行了进一步的理论分析。
Potential of TTT
● 给定适当对齐的特征分布,主任务的预测精度是低界的
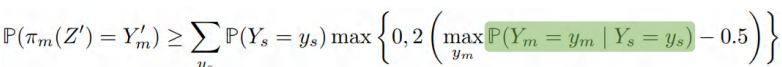
● 特殊情况:编码特性过拟合SSL任务

上面两个公式中的绿色项表明:当我们知道一个样本自监督标签的时候,我们能否有效地判断主任务的标签,即当两个任务高度相关的时候有可能可以提升主任务中的准确性。比如在图像问题中可以引入对比学习。
基于以上分析,我们提出了一种新的TTT++方法,相比之前的TTT方法有3点不同。
第一点是,通过预存特征分布信息的方式来引入online feature。
第二点是,通过解耦实现可靠的特征估计。
第三点是,针对图像问题可以用对比学习的方法在测试的时候对模型进行更有效的强化。
4
Experiments
我们在以下4个场景中对模型进行了有效性的验证

1 - Controlled Synthetic
我们选取了经典的二分类问题,为的是区分每个数据点所属的部位。这里我们引入了一个相对简单的自监督问题,这个自监督标签来自于两个中心线的Label Classifier提供的标签。在这种情况下,自监督任务和主任务的标签在大部分时候都是相同的。下图中,我们通过平移和选择构造新的训练环境。

我们发现,我们提出的TTT++方法能够更加有效的调整模型,并且有着明显的提升。为社么会有这些差异呢?如果我们观察这些数据点在特征空间中的分布,就会发现baseline方法确实无法考虑和消除数据分布的偏移。
2 - Visual Robustness
我们再看下我们的方法在图像问题中的实验结果。
• ResNet50 trained on CIFAR10/100, tested on CIFAR10/100-C or CIFAR10.1

相对于实验中的baseline方法,即使只是部分使用我们的方法,就已经能够得到非常有竞争力的结果。

我们还发现只是增加qeue size的方法,也能取得不错的准确率。
5
总结
我们对TTT这个方法深入分析,并给出了改进建议。改进后的TTT++方法有着显著的效果提升。我们的结果表明,通过利用额外的信息,比如与主任务相关的自监督任务或者是与模型相关的特征分布,可以更有效地实现目标。
• Ideas:
1. Offline feature summarization + online moment matching
2. Batch-queue decoupling for robust moment estimate
3. Contrastive method as a strong self-supervised learner at test time
• Insights:
• Exploiting take-specific information (e.g., related SSL) and model-specific information (e.g., feature distribution moments) can be crucial
• Rethink what to store, in addition to model param, for robust deployment
6
Other Applications

我们在其他应用上还考虑过在测试的时候对图像质量在线优化,前段时间我们在行为预测的问题中也尝试了类似的想法。
提
醒
论文题目:
TTT++: When Does Self-supervised Test-time Training Fail or Thrive?
论文链接:
https://openreview.net/pdf?id=86NHK__yFDl
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:刘越江
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了700多位海内外讲者,举办了逾350场活动,超280万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!
边栏推荐
猜你喜欢








随机推荐
linux上使用docker安装redis
Linux 配置MySQL
Users should clearly know that quantitative trading is not a simple procedure
全球不用交税的国家,为什么不交
R语言检验时间序列的平稳性:使用tseries包的adf.test函数实现增强的Dickey-Fuller(ADF)检验、检验时序数据是否具有均值回归特性(平稳性)、不具有均值回归特性的案例
Bi Sheng Compiler Optimization: Lazy Code Motion
外包的水有多深?腾讯15k的外包测试岗能去吗?
继承关系下构造方法的访问特点
R语言ggplot2可视化:使用ggpubr包的ggerrorplot函数可视化误差线(可视化不同水平均值点以及se标准误差)、设置add参数为dotplot添加点阵图
Leetcode 235. 二叉搜索树的最近公共祖先
数字与中文大写数字互转(5千万亿亿亿亿以上的数字也支持转换)
后台管理实现导入导出
EasyExcel使用
c:forEach varStatus属性
生成NC文件时,报错“未定义机床”
毕昇编译器优化:Lazy Code Motion
Install win7 virtual machine in Vmware and related simple knowledge
制定量化交易策略的基本步骤有哪些?
迅为瑞芯微RK3399开发板设置Buildroot文件系统测试MYSQL允许远程访问
杭电多校-Counting Stickmen-(思维+组合数+容斥)