当前位置:网站首页>电信保温杯笔记——《统计学习方法(第二版)——李航》第17章 潜在语义分析
电信保温杯笔记——《统计学习方法(第二版)——李航》第17章 潜在语义分析
2022-08-10 19:15:00 【电信保温杯】
电信保温杯笔记——《统计学习方法(第二版)——李航》第17章 潜在语义分析
论文
潜在语义分析:《Indexing by latent semantic analysis》
非负矩阵分解算法:《Learning parts of objects by non-negative matrix factorization》、《Algorithms for non-negative matrix factorization》
介绍
本文是对原书的精读,会有大量原书的截图,同时对书上不详尽的地方进行细致解读与改写。
潜在语义分析(latent semantic analysis,LSA)是一种无监督学习方法,也被称为潜在语义索引(latent semantic indexing,LSI),主要用于文本的话题分析。传统的方法以单词向量表示文本的语义内容,以单词向量空间的度量表示文本之间的语义相似度。潜在语义分析旨在解决这种方法不能准确表示语义的问题,试图从大量的文本数据中发现潜在的话题,以话题向量表示文本的语义内容,以话题向量空间的度量更准确地表示文本之间的语义相似度。具体地,将文本集合表示为单词-文本矩阵,对单词-文本矩阵进行分解,从而得到话题向量空间,以及文本在话题向量空间的表示。
单词向量空间在内积相似度未必能够准确表达两个文本的语义相似度。因为自然语言的单词具有一词多义性(polysemy)及多词一义性(synonymy),即同一个单词可以表示多个语义,多个单词可以表示同一个语义,所以基于单词向量的相似度计算存在不精确的问题。为了解决这个问题,提出了话题向量空间。
单词向量空间



优点:单词向量空间模型的优点是模型简单,计算效率高。因为单词向量通常是稀疏的,两个向量的内积计算只需要在其同不为零的维度上进行即可,需要的计算很少,可以高效地完成。
缺点:在内积相似度未必能够准确表达两个文本的语义相似度。因为自然语言的单词具有一词多义性(polysemy)及多词一义性(synonymy),即同一个单词可以表示多个语义,多个单词可以表示同一个语义,所以基于单词向量的相似度计算存在不精确的问题。

话题向量空间

话题向量空间

文本在话题向量空间的表示

从单词向量空间到话题向量空间的线性变换

潜在语义分析算法
矩阵奇异值分解算法

步骤
1. 单词-文本矩阵

2. 截断奇异值分解

3. 话题向量空间

4. 文本的话题空间表示

例子

非负矩阵分解算法

非负矩阵分解

潜在语义分析模型

非负矩阵分解的形式化

算法

∂ J ( W , H ) ∂ W i l = ∂ ( 1 2 ∑ p ∑ j [ X p j − ∑ k W p k H k j ] 2 ) ∂ W i l = 1 2 ∂ ( ∑ p ≠ i ∑ j [ X p j − ∑ k W p k H k j ] 2 + ∑ j [ X i j − ∑ k W i k H k j ] 2 ) ∂ W i l = 1 2 ∂ ( ∑ j [ X i j − ∑ k W i k H k j ] 2 ) ∂ W i l = 1 2 ∑ j ∂ ( [ X i j − ∑ k W i k H k j ] 2 ) ∂ W i l = ∑ j ( [ X i j − ∑ k W i k H k j ] ) ∂ ( [ X i j − ∑ k W i k H k j ] ) ∂ W i l = ∑ j ( [ X i j − ( W H ) i j ] ) ∂ ( [ X i j − ∑ k W i k H k j ] ) ∂ W i l = − ∑ j ( [ X i j − ( W H ) i j ] ) ∂ ( ∑ k W i k H k j ] ) ∂ W i l = − ∑ j ( [ X i j − ( W H ) i j ] ) H l j = − ∑ j ( [ X i j − ( W H ) i j ] ) H j l T = − ( ∑ j X i j H j l T − ∑ j ( W H ) i j H j l T ) = − [ ( X H T ) j l − ( W H H T ) i j ] ( 17.28 ) \begin{aligned} \frac{\partial J(W,H)}{\partial W_{il}} &= \frac{ \partial \left( \frac{1}{2} \sum_{p}\sum_{j} [X_{pj} - \sum_k W_{pk}H_{kj} ]^2 \right) }{\partial W_{il}} \\ &= \frac{1}{2} \frac{ \partial \left( \sum_{p\neq i}\sum_{j} [X_{pj} - \sum_k W_{pk}H_{kj} ]^2 + \sum_{j} [X_{ij} - \sum_k W_{ik}H_{kj} ]^2 \right) }{\partial W_{il}} \\ &= \frac{1}{2} \frac{ \partial \left( \sum_{j} [X_{ij} - \sum_k W_{ik}H_{kj} ]^2 \right) }{\partial W_{il}} \\ &= \frac{1}{2} \sum_{j} \frac{ \partial \left( [X_{ij} - \sum_k W_{ik}H_{kj} ]^2 \right) }{\partial W_{il}} \\ &= \sum_{j} \left( [X_{ij} - \sum_k W_{ik}H_{kj} ] \right)\frac{ \partial \left( [X_{ij} - \sum_k W_{ik}H_{kj} ] \right) }{\partial W_{il}} \\ &= \sum_{j} \left( [X_{ij} - (WH)_{ij} ] \right)\frac{ \partial \left( [X_{ij} - \sum_k W_{ik}H_{kj} ] \right) }{\partial W_{il}} \\ &= -\sum_{j} \left( [X_{ij} - (WH)_{ij} ] \right)\frac{ \partial \left( \sum_k W_{ik}H_{kj} ] \right) }{\partial W_{il}} \\ &= -\sum_{j} \left( [X_{ij} - (WH)_{ij} ] \right) H_{lj} \\ &= -\sum_{j} \left( [X_{ij} - (WH)_{ij} ] \right) H_{jl}^T \\ &= - \left( \sum_{j}X_{ij}H_{jl}^T - \sum_{j}(WH)_{ij}H_{jl}^T \right) \\ &= - \left[ (XH^T)_{jl} - (WHH^T)_{ij} \right] \quad\quad\quad\quad\quad\quad (17.28) \end{aligned} ∂Wil∂J(W,H)=∂Wil∂(21∑p∑j[Xpj−∑kWpkHkj]2)=21∂Wil∂(∑p=i∑j[Xpj−∑kWpkHkj]2+∑j[Xij−∑kWikHkj]2)=21∂Wil∂(∑j[Xij−∑kWikHkj]2)=21j∑∂Wil∂([Xij−∑kWikHkj]2)=j∑([Xij−k∑WikHkj])∂Wil∂([Xij−∑kWikHkj])=j∑([Xij−(WH)ij])∂Wil∂([Xij−∑kWikHkj])=−j∑([Xij−(WH)ij])∂Wil∂(∑kWikHkj])=−j∑([Xij−(WH)ij])Hlj=−j∑([Xij−(WH)ij])HjlT=−(j∑XijHjlT−j∑(WH)ijHjlT)=−[(XHT)jl−(WHHT)ij](17.28)


步骤

本章概要



相关视频
相关的笔记
hktxt /Learn-Statistical-Learning-Method
相关代码
边栏推荐
- Colocate Join :ClickHouse的一种高性能分布式join查询模型
- 铱钌合金/氧化铱仿生纳米酶|钯纳米酶|GMP-Pd纳米酶|金钯复合纳米酶|三元金属Pd-M-Ir纳米酶|中空金铂合金纳米笼核-多空二氧化硅壳纳米酶
- flask装饰器版登录、session
- Apache DolphinScheduler 3.0.0 正式版发布!
- 子域名收集&Google搜索引擎语法
- 【SemiDrive源码分析】【MailBox核间通信】51 - DCF_IPCC_Property实现原理分析 及 代码实战
- Public Key Retrieval is not allowed(不允许公钥检索)【解决办法】
- IIC通信协议总结[通俗易懂]
- 【二叉树】二叉搜索树的后序遍历序列
- 「POJ 3666」Making the Grade 题解(两种做法)
猜你喜欢
QoS Quality of Service Seven Switch Congestion Management
转铁蛋白Tf功能化β-榄香烯-雷公藤红素/紫杉醇PLGA纳米粒/雷公藤甲素脂质体(化学试剂)

电脑为什么会蓝屏的原因
主动信息收集
UE4 - 河流流体插件Fluid Flux
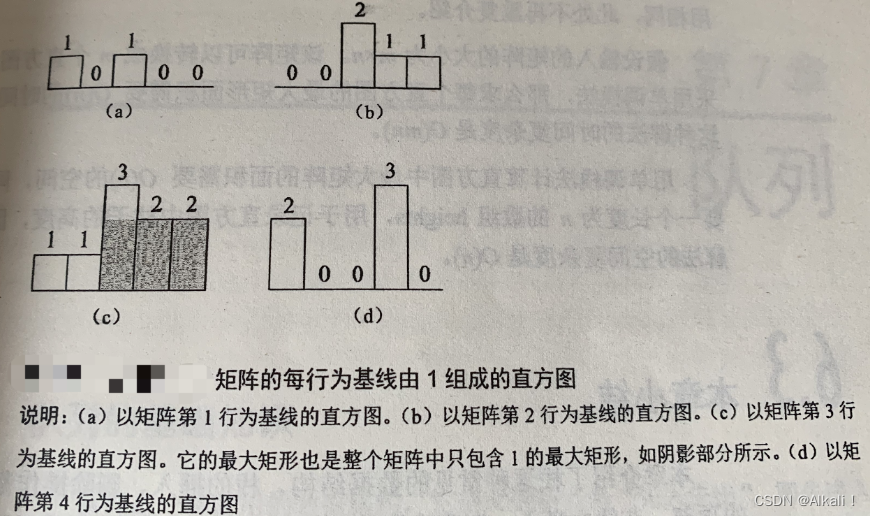
leetcode 85.最大矩形 单调栈应用
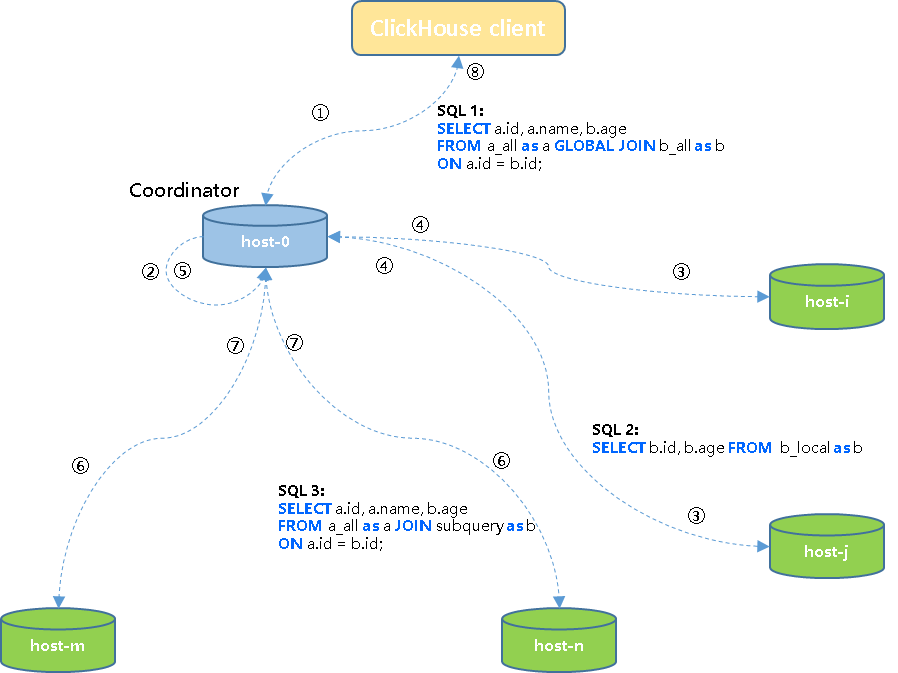
Colocate Join :ClickHouse的一种高性能分布式join查询模型
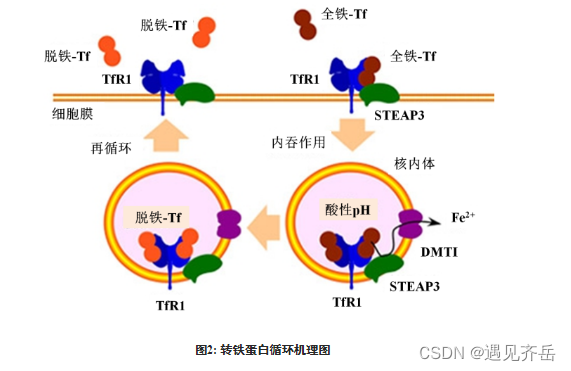
转铁蛋白(Tf)修饰去氢骆驼蓬碱磁纳米脂质体/香豆素-6脂质体/多柔比星脂质体
[Go WebSocket] Your first Go WebSocket server: echo server
idea插件 协议 。。 公司申请软件用
![[Go WebSocket] Your first Go WebSocket server: echo server](/img/ac/a5f0a9b9e97470c4c74c5ca84383ab)
随机推荐
【LeetCode】42、接雨水
皮质-皮质网络的多尺度交流
whois information collection & corporate filing information
转铁蛋白(Tf)修饰去氢骆驼蓬碱磁纳米脂质体/香豆素-6脂质体/多柔比星脂质体
Transferrin-modified vincristine-tetrandrine liposomes | transferrin-modified co-loaded paclitaxel and genistein liposomes (reagents)
The servlet mapping path matching resolution
IIC通信协议总结[通俗易懂]
leetcode 85.最大矩形 单调栈应用
【无标题】基于Huffman和LZ77的GZIP压缩
3D Game Modeling Learning Route
铱钌合金/氧化铱仿生纳米酶|钯纳米酶|GMP-Pd纳米酶|金钯复合纳米酶|三元金属Pd-M-Ir纳米酶|中空金铂合金纳米笼核-多空二氧化硅壳纳米酶
echart 特例-多分组X轴
《分布式微服务电商》专题(一)-项目简介
巧用RoaringBitMap处理海量数据内存diff问题
Ransom Letter Questions and Answers
The servlet mapping path matching resolution
Keras deep learning combat (17) - image segmentation using U-Net architecture
链表应用----约瑟夫问题
nfs挂载服务器,解决挂载后无法更改用户id,无法修改、写文件,文件只读权限Read-only file system等问题
优雅退出在Golang中的实现