当前位置:网站首页>Intersection, union and difference sets of spark operators
Intersection, union and difference sets of spark operators
2022-04-23 15:48:00 【Uncle flying against the wind】
Preface
In daily development , It often involves the intersection of different sets of data , Operation of Union and difference sets , stay Spark in , Similar operators are also provided to help us deal with such business , namely double Value type Data processing ;
intersection
Function signature
def intersection(other: RDD[T]): RDD[T]
Function description
To the source RDD And parameters RDD Returns a new RDD
Case a , Find the intersection of two sets
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DoubleValueTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO operator - double Value type
// intersection , Union and difference sets require the data types of the two data sources to be consistent
// Zipper operation the types of two data sources can be different
val rdd1 = sc.makeRDD(List(1,2,3,4))
val rdd2 = sc.makeRDD(List(3,4,5,6))
val rdd7 = sc.makeRDD(List("3","4","5","6"))
// intersection : 【3,4】
val rdd3: RDD[Int] = rdd1.intersection(rdd2)
//val rdd8 = rdd1.intersection(rdd7)
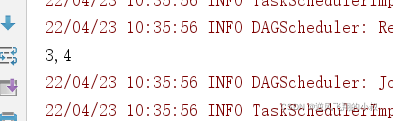
println(rdd3.collect().mkString(","))
sc.stop()
}
}Run the above code , Observe the console output effect
union
Function signature
def union(other: RDD[T]): RDD[T]
Function description
To the source RDD And parameters RDD Returns a new... After union RDD
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DoubleValueTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO operator - double Value type
// intersection , Union and difference sets require the data types of the two data sources to be consistent
// Zipper operation the types of two data sources can be different
val rdd1 = sc.makeRDD(List(1,2,3,4))
val rdd2 = sc.makeRDD(List(3,4,5,6))
val rdd7 = sc.makeRDD(List("3","4","5","6"))
// intersection : 【3,4】
/*val rdd3: RDD[Int] = rdd1.intersection(rdd2)
//val rdd8 = rdd1.intersection(rdd7)
println(rdd3.collect().mkString(","))*/
// Combine : 【1,2,3,4,3,4,5,6】
val rdd4: RDD[Int] = rdd1.union(rdd2)
println(rdd4.collect().mkString(","))
sc.stop()
}
}subtract
Function signature
def subtract(other: RDD[T]): RDD[T]
Function description
With a RDD The main elements are , Remove two RDD Repeat elements in , Keep the other elements . Difference set
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DoubleValueTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO operator - double Value type
// intersection , Union and difference sets require the data types of the two data sources to be consistent
// Zipper operation the types of two data sources can be different
val rdd1 = sc.makeRDD(List(1,2,3,4))
val rdd2 = sc.makeRDD(List(3,4,5,6))
val rdd7 = sc.makeRDD(List("3","4","5","6"))
// intersection : 【3,4】
/*val rdd3: RDD[Int] = rdd1.intersection(rdd2)
//val rdd8 = rdd1.intersection(rdd7)
println(rdd3.collect().mkString(","))*/
// Combine : 【1,2,3,4,3,4,5,6】
/*val rdd4: RDD[Int] = rdd1.union(rdd2)
println(rdd4.collect().mkString(","))*/
// Difference set : 【1,2】
val rdd5: RDD[Int] = rdd1.subtract(rdd2)
println(rdd5.collect().mkString(","))
sc.stop()
}
}zip
zip Also known as zipper operator , Function signature
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
Function description
Put two RDD The elements in , Merge in the form of key value pairs . among , Key value alignment Key For the first time 1 individual RDDThe elements in , Value For the first time 2 individual RDD Elements in the same position in
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DoubleValueTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
// TODO operator - double Value type
// intersection , Union and difference sets require the data types of the two data sources to be consistent
// Zipper operation the types of two data sources can be different
val rdd1 = sc.makeRDD(List(1,2,3,4))
val rdd2 = sc.makeRDD(List(3,4,5,6))
val rdd7 = sc.makeRDD(List("3","4","5","6"))
// intersection : 【3,4】
/*val rdd3: RDD[Int] = rdd1.intersection(rdd2)
//val rdd8 = rdd1.intersection(rdd7)
println(rdd3.collect().mkString(","))*/
// Combine : 【1,2,3,4,3,4,5,6】
/*val rdd4: RDD[Int] = rdd1.union(rdd2)
println(rdd4.collect().mkString(","))*/
// Difference set : 【1,2】
/*val rdd5: RDD[Int] = rdd1.subtract(rdd2)
println(rdd5.collect().mkString(","))*/
// zipper : 【1-3,2-4,3-5,4-6】
val rdd6: RDD[(Int, Int)] = rdd1.zip(rdd2)
val rdd8 = rdd1.zip(rdd7)
println(rdd6.collect().mkString(","))
sc.stop()
}
}版权声明
本文为[Uncle flying against the wind]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231544587277.html
边栏推荐
- 布隆过滤器在亿级流量电商系统的应用
- Tencent offer has been taken. Don't miss the 99 algorithm high-frequency interview questions. 80% of them are lost in the algorithm
- 编译,连接 -- 笔记
- 时序模型:门控循环单元网络(GRU)
- 糖尿病眼底病变综述概要记录
- MySQL optimistic lock to solve concurrency conflict
- Metalife established a strategic partnership with ESTV and appointed its CEO Eric Yoon as a consultant
- How can poor areas without networks have money to build networks?
- C, calculation method and source program of bell number
- For examination
猜你喜欢

MySQL optimistic lock to solve concurrency conflict

腾讯Offer已拿,这99道算法高频面试题别漏了,80%都败在算法上
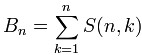
C, calculation method and source program of bell number
C#,贝尔数(Bell Number)的计算方法与源程序
Spark 算子之partitionBy
CVPR 2022 quality paper sharing
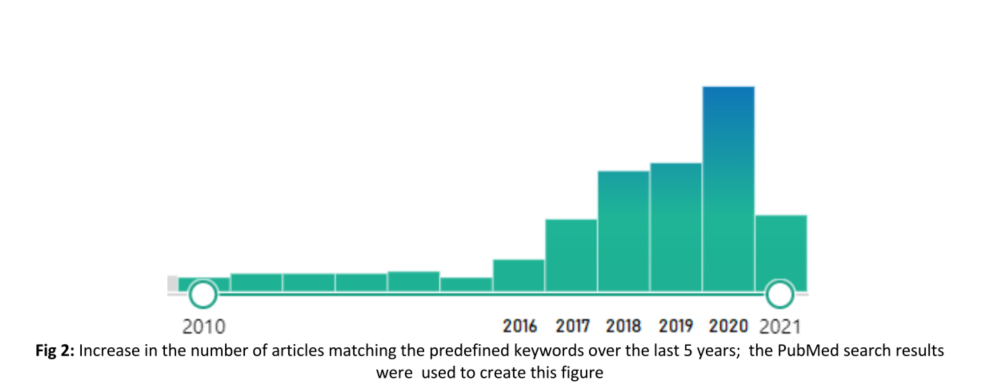
糖尿病眼底病变综述概要记录
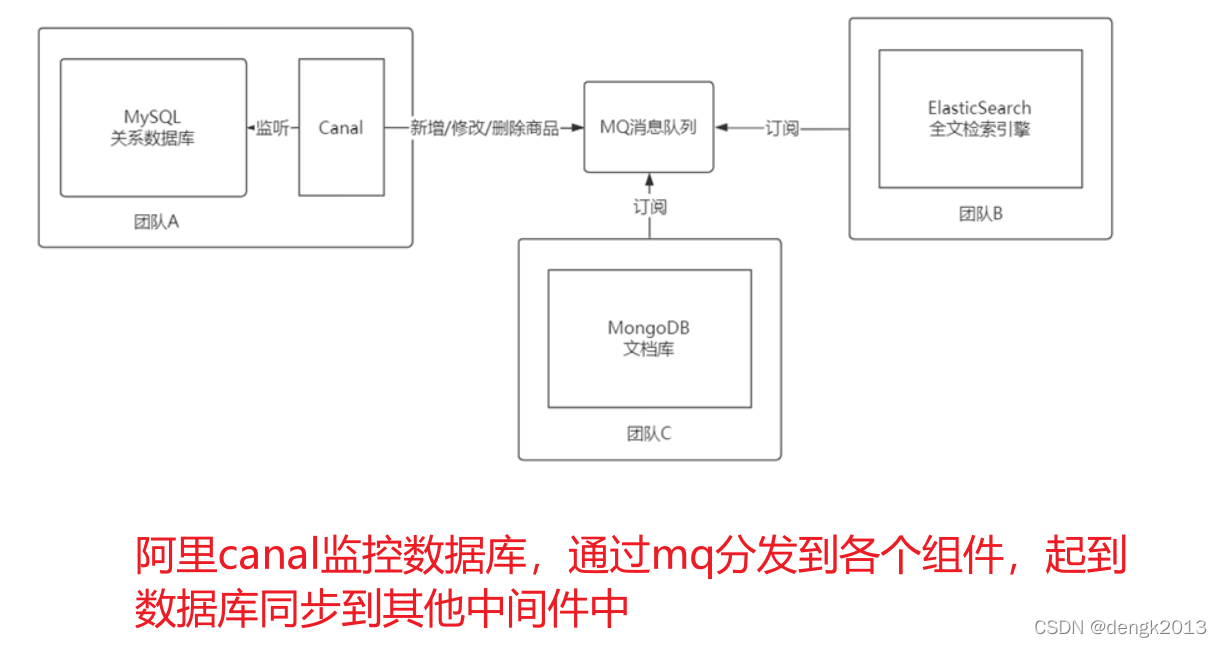
MySQL集群模式與應用場景
cadence SPB17. 4 - Active Class and Subclass
For examination
随机推荐
Upgrade MySQL 5.1 to 5.66
携号转网最大赢家是中国电信,为何人们嫌弃中国移动和中国联通?
Go语言切片,范围,集合
Best practices of Apache APIs IX high availability configuration center based on tidb
时序模型:门控循环单元网络(GRU)
Upgrade MySQL 5.1 to 5.611
PHP function
leetcode-396 旋转函数
shell脚本中的DATE日期计算
CVPR 2022 quality paper sharing
Spark 算子之partitionBy
JVM-第2章-类加载子系统(Class Loader Subsystem)
Load Balancer
【自娱自乐】构造笔记 week 2
Use bitnami PostgreSQL docker image to quickly set up stream replication clusters
JS regular determines whether the port path of the domain name or IP is correct
MySQL集群模式與應用場景
Codejock Suite Pro v20.3.0
删除字符串中出现次数最少的字符
C language --- advanced pointer