当前位置:网站首页>Kettle -- control parsing
Kettle -- control parsing
2022-04-23 14:03:00 【Amelia who loves learning】
Kettle Control
1 Input control
The input control is the largest control in the transformation , Used to extract data or generate data . Input is ETL Inside E(Extract), Mainly do the work of data extraction .
-
CSVFile input
CSVFile is a comma separated fixed format text file , The suffix of this file is.csv, It can be usedExcelperhaps Text editor open . The most common in EnterprisesETLDemand is tocsvThe file is converted toexcelfile , If you useKettleTo do thisETLWork , It needs to be usedCSVFile input control . -
Text file input
Extracting the log information on the server is a problem in the companyETLDevelopment is a very common operation , Log information is basically text type , Therefore, the text file input control iskettleAn input control commonly used in . -
ExcelInput
ExcelInput control is also a very common input control , Generally, enterprises will use this control to control a large number ofExcelDocument carried outETLoperation . -
XMLInput
1)XML brief introduction
XML- Extensible markup language eXtensible Markup Language, from W3C Organization Publishing , At present, it is recommended to follow W3C Organized in 2000 Published in XML1.0 standard .XML Used to transmit and store data , Is in a unified format , Organization related data , Serve applications on different platforms .
2)XPath brief introduction
XPath That is to say XML Path to the language (XML Path Language), It's a way to determine XML The language of a part of a document .XPath be based on XML Tree structure of , Provide the ability to find nodes in the data structure tree .
XPath Using path expressions in XML Select node in document . Path expression :
| expression | describe |
|---|---|
nodename |
Select all children of this node |
/ |
Select from root node |
// |
Select the node in the document from the current node that matches the selection , Regardless of their location |
. |
Select the current node |
.. |
Select the parent of the current node |
@ |
Select Properties |
3)XML Input control
Pay attention to getting xml All paths to the document , Set the appropriate loop read path .
JSONInput
1)JSON brief introduction
JSON``(JavaScript Object Notation, JS Object shorthand ) Is a lightweight data exchange format .JSON An object is essentially a JS object , But this object is special , It can be directly converted to a string , Pass in different languages , It can be converted into objects in other languages through tools .
JSON The core concept : Array 、 object 、 attribute .
Array :[ ]
object :{ }
attribute :key:value
2)JSON Path
JSONPath Be similar to XPath stay xml Positioning in the document ,JsonPath Expressions are usually used to retrieve or set paths Json Of . Its expression can accept dot–notation( Point notation ) and bracket–notation( Bracket notation ) Format
Point notation :$.store.book[0].title
Bracket notation :$[‘store’][‘book’][0][‘title’]
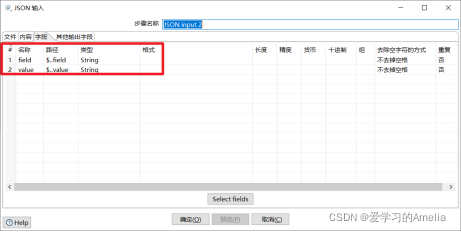
3)JSON Input control
understand JSON Format and `JSON Path in the future , We should learn to use JSON Input control ,JSON Controls are also made in enterprises ETL One of the commonly used controls .

6. Table input
1) Create database connection
Table input can be said to be kettle The most used input control in , Because most of the data in the enterprise will be stored in the database .kettle You can connect to all kinds of common databases on the market , such as Oracle,Mysql,SqlServer etc. . But before connecting to each database , We need to configure the corresponding database driver first .
First of all, we will change the corresponding version of mysql Connect the drive kettle Under the installation directory lib Under the folder , And then restart kettle The client of Spoon. Create the corresponding database connection , In the main object tree directory of the transformation view , There is one DB Connect , Right click and select new , In the open database connection box , Fill in the correct database information , Then test , After the test is correct , You can save this database connection .
By default, the database connection is only valid for this conversion , After another conversion , This connection won't work , You also need to create a new database connection , So we need to share the established database connection , After sharing , Other transformations can also be connected with the database we built in advance .
2) Table input
After creating the database connection , We can use the table input control , Double click the table input control , Select the database connection you just created , And then in SQL Enter the appropriate query statement in the box , Then click the preview button , See if we can preview the data we expect .
2 Output control
The output control is the second largest control in the transformation , Used to store data . The output is ETL Inside L(Load), Mainly do the work of data loading .
ExcelOutput
Kettle It comes with two Excel Output , One Excel Output , The other is Microsoft Excel Output .
Excel Output can only output xls file ( fit Excel2003),Microsoft Excel Output can output xls and xlsx file ( fit Excel2007 And later )
- Text file output
Text file output control , seeing the name of a thing one thinks of its function , This is a control that can output data into text , It is also commonly used in enterprises .
SQLFile output
SQL File output is usually connected with table input , Then, the table structure and data of the database table are represented as sql Export as a file , Then do database backup .
-
Table output
The table output control cankettleThe data in the data row is written directly to the table in the database . -
to update & Insert / to update
Update and insert / to update , These two controls are kettle It provides a control to compare the existing records in the database with the records in the data flow . Enterprise class ETL These two controls are often used to update the database .
Difference between them :
1) Update is to compare the data in the database table with the data in the data flow , Update if different , If there is more data in the data stream than in the database table , Then report a mistake .
2) Insert / The function of update is the same as that of update , It just optimizes the function of inserting data when it does not exist , Therefore, more enterprises also use insertion / to update .
- Delete
Delete control can delete the data with specified conditions in the database table , This control is generally used to delete database table data or compare it with another table data , Then carry out the operation of weight removal .
3 Convert control
The conversion control is the third largest control in the conversion , Used to convert data . Conversion is ETL Inside T(Transform), Mainly for data conversion , Data cleaning work .ETL The whole process ,Transform The workload is the largest , It takes a long time , It probably takes up the whole ETL Two thirds of .
Concat fields
Convert control Concat fields, seeing the name of a thing one thinks of its function , Is to connect multiple fields to form a new field .
- Value mapping
Value mapping is to map one value of a field to other values . There is a lot of use in data quality specifications , For example, many systems correspond to gender sex Fields are defined differently . So we need to use this control , Different values of the same field , The mapping is converted to the value we need .
- Increase constant & Add sequence
Adding a constant is to add a column of data to its own data stream , The data in this column is the same value ; Adding a sequence is to add a sequence field to the data flow , You can customize the increment step of the sequence field .
- Field selection
Field selection is to select fields from the data flow 、 Change name 、 Change data type .
- Calculator
A calculator is a collection of functions to create new fields , You can also set whether the field is removed ( Temporary fields ). We can calculate the existing fields through multiple calculation functions in the calculator , Get the new field .
- String cut & Replace & operation
There are three controls about strings in the conversion control , They are the cut string , String manipulation , String substitution ; The cut string is used to specify the clipping position of the input stream field and cut out a new field ; String replacement specifies the search content and replacement content , If the field of the input stream matches the search content, it is replaced to generate a new field ; String operation is to remove spaces at both ends of the string and switch case , And generate a new field .
- sort record & Remove duplicate records
Removing duplicate records is to remove the same data lines in the data stream . However, before using this control, it is required to modify the data first Sort , The control used to sort data is to sort records , The sort record control can sort the data flow in ascending or descending order of the specified fields . So sort records + Removing duplicate records controls are often used in conjunction with teaming .
- Unique line ( Hash value )
Unique line ( Hash value ) Delete the duplicate rows of data stream . The effect of this control is similar to ( sort record + Remove duplicate records ) The effect is the same , But the principle of implementation is different . sort record + Remove duplicate records and compare the data between every two rows , And the only line ( Hash value ) Is to create a hash value for each row of data , Compare whether the data is repeated by hash value , So the only line ( Hash value ) The weight removal efficiency is relatively high .
- Split Fields
Split field is to split the field into two or more fields according to the separator . It should be noted that , After the field is split , The original field will be removed from the data flow disappear .
- Split columns into multiple rows
Splitting a column into multiple rows is to split a specified field into multiple rows according to the specified separator , Then the other fields are copied directly .
- Row flattening
Row flattening is to merge multiple rows of data in the same group into one row , It can be understood as the reverse operation of splitting columns into multiple rows . However, it should be noted that there are two conditions for the use of row flattening controls :
1) You need to sort the data before using
2) The number of data pieces in each group shall be consistent , Otherwise, the data will be disordered
- Column turned
Column turned , As the name suggests, turn more columns into one row , If the data column has the same value , Follow the specified fields , Change the field contents of one column into different columns , The process of converting multiple rows of data into one row of data .
Be careful : Before columns are converted to rows, the data flow must be sorted by grouping fields , Otherwise, the data will be out of order !
1. Key fields : A field that changes from data content to column name
2. Grouping field : Column turned , Group fields after transformation
3. Target field : The column name field of the added column
4. Data field : The data field of the target field
5. Keyword value : Keywords in data field query , It can also be understood as key
6. type : To set the appropriate type for the target field , Otherwise, an error will be reported
- Transfer line column
Transfer line column , One row to many columns , Is to convert the field name of the data field into a column , Turn data rows into data columns . We can also simply understand that the row to column control is the reverse operation of the column to row control .
1.Key Field : Transfer line column , Generated column name field name
2. Field name : The field name in the original data stream
3.Key value :Key Value of field , This is self defined , Generally, it is the same as the previous field name
4.Value Field : Corresponding Key The column name of the data column of the value
4 Application controls
- Replace
NULLvalue
Replace NULL value , As the name suggests, it is to put the data in null Replace the value with another value .
1. You can choose to replace all fields in the data flow null value
2. You can also select fields , In the field box below , According to the different fields , take null Replace the value with a different value
- Write the log
The log writing control is mainly used during debugging , This control prints each row of data from the data stream to the console , It is convenient for us to debug the whole program .
5 Process control
The controls under process classification are mainly used to control data flow and data flow .
Switch/case
The most typical data classification control , You can use different values of the data of a field , Let the data flow from one way to multiple way .
1. Select the field to judge
2. Select the type of value of the judgment field
3. Fill in the judgment conditions and target steps of classified data
- Filtering records
And Switch/case For comparison , Filtering records is equivalent to if-else, You can customize and enter a judgment condition , Then the data in the data stream is divided into two paths .
1. First fill in the judgment conditions of the data below
2. Then select the judgment condition above as true perhaps false Output steps
- Empty operation
Empty operation , As the name suggests, it means doing nothing , This control is generally used as the end of the data flow .
- suspend
Abort is the end of the data flow , If there is data flow to this control , The entire conversion process will abort , And output the error message on the console . This control is generally used to verify data , Or debug the program .
6 Query control
The query control is used to query the data in the data source , And merge into the main data flow .
- Database query
Database query is to query data from the database , Then a process of left connection with the data in the data flow . Left connection means that all the original data in the data flow has , However, not all the data queried by the database query control will be listed , Association can only be performed according to the matching criteria entered .
1. Select the appropriate database link
2. Enter the name of the table to be queried in the database
3. Enter the connection conditions for the left connection of two tables
4. Get the return field , Get the value returned by the query table
- Stream query
Stream query control is to query the data in two data streams , Then do equivalent matching according to the specified fields . Be careful : Stream query loads data into memory before query , And can only perform equivalent query .
1. Enter the data stream of the query
2. Enter the fields for the two streams to match ( Equivalence match )
3. Enter the queried fields
7 Connect controls
The controls under the connection category generally connect multiple data sets through keywords , The process of forming a data set .
- Merge records
Merge records are used to merge data from two different sources , The data from these two sources are old data and new data , This step matches the old data with the new data according to the specified keyword 、 Compare 、 Merge . Note that old data and new data need to be sorted according to key fields in advance , And the old data and new data should have the same field name .
The merged data will include all data from the old data source and the new data source , For changing data , Replace old data with new data , At the same time, a marking field is used in the result , To specify the comparison results of new and old data .
1) Old data source : To select an old data source
2) New data sources : To select a new data source
3) Flag fields : Set the name of the flag field , The flag field is used to save the results of the comparison , The comparison results are as follows
①identical – Old data is the same as new data
②changed – The data has changed ;
③new – Records in new data but not in old data
④deleted – Records in old data but not in new data
4) Key fields : A field used to locate and judge the same record in two data sources .
5) Compare fields : For the same record in two data sources , Specify the fields to compare
- Recordset connection
Recordset connection can make left connection to the data flow in two steps , The right connection , Internal connection , External connection . This control is more powerful , Enterprises do ETL Developers will often use this control , However, it should be noted that before the recordset connection , You need to sort the data of the recordset , In addition, the fields associated with two tables must be selected for the sorted fields , Otherwise, the data is disordered , appear null value .
- To select two data streams to be connected
- Choose the connection type , There are four in all :
INNER,LEFT OUTER,RIGHT OUTER,FULL OUTER - Select the connection field from the two data flow steps
8 Statistics control
Statistics control can provide data sampling and statistics functions . The function of grouping controls is similar to GROUP BY, It can be grouped according to one or more specified fields , Then the remaining fields can be combined and calculated according to the aggregation function . Be careful , Before grouping , It's best to sort the data first .
9 Mapping controls
Mapping can be used to define sub transformations , Facilitate code encapsulation and reuse . mapping ( Subconversion ) Is used to configure the sub transformation , A step of calling a sub transformation . The mapping input specification is an input field , Input by the called transformation . The mapping output specification is to output all columns to the called transformation , Do nothing .
10 Script control
Script is to complete some complex operations directly by writing program code . perform SQL Script : perform sql Script control is to connect to the database , Then execute some of your own sql sentence .
版权声明
本文为[Amelia who loves learning]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231341317194.html
边栏推荐
- 第十五章 软件工程新技术
- 商家案例 | 运动健康APP用户促活怎么做?做好这几点足矣
- Atcoder beginer contest 248c dice sum (generating function)
- 项目中遇到的问题(五)操作Excel接口Poi的理解
- Oracle告警日志alert.log和跟踪trace文件中文乱码显示
- CentOS mysql多实例部署
- Taobao released the baby prompt "your consumer protection deposit is insufficient, and the expiration protection has been started"
- 村上春树 --《当我谈跑步时,我谈些什么》句子摘录
- Oracle alarm log alert Chinese trace and trace files
- cnpm的诡异bug
猜你喜欢


随机推荐
The art of automation
生产环境——
关于stream流,浅记一下------
Qt Designer怎样加入资源文件
9月8日,临去松山湖的前夜
基于ibeacons三点定位(微信小程序)
Ptorch classical convolutional neural network lenet
STM32 learning record 0007 - new project (based on register version)
CentOS mysql多实例部署
Go语言 RPC通讯
As a junior college student, I studied hard in closed doors for 56 days, won Ali offer with tears, five rounds of interviews and six hours of soul torture
linux MySQL数据定时dump
JS force deduction brush question 103 Zigzag sequence traversal of binary tree
1256: bouquet for algenon
_模_板_
Function executes only the once function for the first time
L2-024 tribe (25 points)
The latest development of fed digital currency
About note 1
Choreographer full resolution