当前位置:网站首页>Convolutional Neural Network Gradient Vanishing, The Concept of Gradient in Neural Networks
Convolutional Neural Network Gradient Vanishing, The Concept of Gradient in Neural Networks
2022-08-11 09:49:00 【Yangyang 2013 haha】
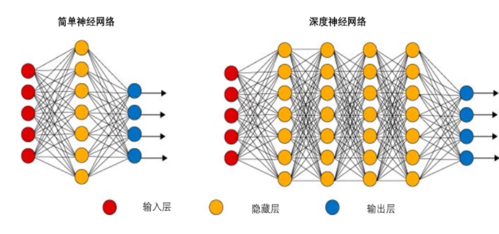
什么是梯度消失?How to speed up gradient descent
One of the gradients in the cumulative product is less than1,Then keep multiplying,这个值会越来越小,Gradient decay is very large,迅速接近0.In a neural network it is a parameter close to the output layer,梯度越大,far parameter,梯度越接近0.根本原因是sigmoid函数的缺陷.
方法:1、good initialization method,逐层预训练,Backprop fine-tuning.2、换激活函数,用relu,leaky——relu.by making the gradient close to1或等于1,Avoid the cumulative multiplication process,Results decay rapidly.
避免梯度消失和梯度爆炸的方案:使用新的激活函数SigmoidBoth the function and the hyperbolic tangent function will cause the problem of vanishing gradients.ReLU函数当x<0,can lead to inability to learn.
Take advantage of some improvedReLUCan to a certain extent, to avoid the problem of gradient disappeared.例如,ELU和LeakyReLU,这些都是ReLU的变体.
How to prevent gradient disappearance and gradient explosion in deep learning?
为什么deep learning Can suppress the problem of gradient disappearance or explosion
Must learn neural network,Because deep learning itself is a neural network algorithm,The reason why it is called deep learning is to highlight the word depth.The depth represents many of the neural network layers.
Because there is no good training method for the neural network algorithm mentioned before,Eventually there trained neural network2到3Layers are the limit,No real value for many applications.
The previous mainstream neural network training method is called backpropagation,But it cannot solve the disappeared with the increase of the layer number of neural network and gradient.
在2006年由GeffryHitonGreed in advance step by step training to use,Make the training of the neural network can efficiently,Layer can reach many layers,Plus the main push of cloud computing in computing power,Makes the neural network have great practical value.
If you are a beginner, just know that deep learning is a neural network,Just a breakthrough in depth.You can refer to the small article.
The choice of loss function and activation function for deep learning
The choice of loss function and activation function of deep learning in deep neural network(DNN)反向传播算法(BP)中,我们对DNNThe use of the forward and backpropagation algorithm is summarized.Which USES the loss function is the mean square error,And the activation function isSigmoid.
实际上DNNCan use the loss function and activation function.How to choose these loss functions and activation functions??The following is the content of this article.MSE损失+SigmoidThe problem of activation function Let's first look at the mean square error+SigmoidWhat's wrong with the combination of.
回顾下SigmoidThe expression of the activation function is:函数图像如下:从图上可以看出,对于Sigmoid,当zAfter the value becomes larger and larger,函数曲线变得越来越平缓,means the derivative at this timeσ′(z)也越来越小.
同样的,当z的取值越来越小时,也有这个问题.仅仅在z取值为0附近时,导数σ′(z)的取值较大.in mean square error+Sigmoid的反向传播算法中,每一层向前递推都要乘以σ′(z),得到梯度变化值.
Sigmoid的这个曲线意味着在大多数时候,Our gradient changes by a small value,导致我们的W,b更新到极值的速度较慢,That is, our algorithm converges slowly.So what can be done to improve it??
交叉熵损失+Sigmoid改进收敛速度SigmoidThe functional characteristics of , lead to the problem of slow convergence of the backpropagation algorithm,那么如何改进呢?换掉Sigmoid?这当然是一种选择.
Another common choice is to use cross entropy loss function instead of mean square deviation loss function.每个样本的交叉熵损失函数的形式:其中,?is the inner product of vectors.
This form is quite familiar,In the summary of the principle of logistic regression, we actually use a similar form,It's just that at the time we derived it using maximum likelihood estimation,The scientific name of this loss function is cross entropy..
使用了交叉熵损失函数,就能解决SigmoidIs the backpropagation algorithm slow when the function derivative changes most of the time??Let's see when using cross entropy,our output layerδL的梯度情况.
When comparing the mean square error loss function,δLGradient using cross entropy,obtainedδlGradient expressionσ′(z),The gradient is the difference between the predicted value and the true value,这样求得的Wl,blThe gradient of also does not containσ′(z),Therefore, the problem of slow convergence of backpropagation is avoided..
通常情况下,如果我们使用了sigmoid激活函数,交叉熵损失函数肯定比均方差损失函数好用.
对数似然损失+softmaxFor classification output In the front, we all assumed that the output is a continuous derivable value,But if it is a classification problem,Then the output is a category,那我们怎么用DNN来解决这个问题呢?
DNN分类模型要求是输出层神经元输出的值在0到1之间,同时所有输出值之和为1.很明显,existing ordinaryDNNcannot meet this requirement.But we only need to connect the existing full connectionDNN稍作改良,即可用于解决分类问题.
在现有的DNN模型中,We can put the output layeri个神经元的激活函数定义为如下形式:This method is very simple and beautiful,Just change the activation function of the output layer fromSigmoidSuch functions can be transformed into the activation function of the above formula..
The activation function above is oursoftmax激活函数.It has a wide range of applications in classification problems.将DNN用于分类问题,在输出层用softmaxThe activation function is also the most common.
For classificationsoftmax激活函数,The corresponding loss function is generally a log-likelihood function.,即:其中yk的取值为0或者1,If the output of a training sample is thei类.则yi=1,其余的j≠i都有yj=0.
Since each sample belongs to only one category,So this log-likelihood function can be simplified to:It can be seen that the loss function is only related to the output corresponding to the real category,This assumes that the true class is the firsti类,then the other does not belong to theiClass derivative directly for the serial number of the corresponding neurons gradient0.
For the real categoryi类,它的WiLThe corresponding gradient is calculated as:可见,Gradient calculation is also very simple,There is no problem with the slow training speed mentioned in the first section..
当softmaxAfter you have output layer back propagation calculation,ordinary behindDNNThe backpropagation calculation of the layer is the same as the ordinaryDNN没有区别.梯度爆炸ordisappear withReLU学习DNN,You must have heard the words gradient explosion and gradient disappearance.
Especially the gradient disappears,是限制DNNA key hurdle with deep learning,There is no completely overcome.What is exploding gradient and vanishing gradient??
简单理解,is in the process of backpropagation algorithm,Since we used the chain rule which is matrix derivation,有一大串连乘,如果连乘的数字在每层都是小于1的,则梯度越往前乘越小,导致梯度消失,而如果连乘的数字在每层都是大于1的,则梯度越往前乘越大,导致梯度爆炸.
For example, the following gradient calculation:If unfortunately our samples cause the gradient of each layer to be less than1,In the back propagation algorithm,我们的δlWith the layer number is more and more small,even closer0,导致梯度几乎消失,which leads to the previous hidden layerW,bparameters as the iteration progresses,Few major changes,Not to mention restraint.
There is currently no perfect solution to this problem.For the gradient,can generally be adjusted by adjusting ourDNN模型中的初始化参数得以解决.
For the vanishing gradient problem that cannot be solved perfectly,一个可能部分解决梯度消失问题的办法是使用ReLU(RectifiedLinearUnit)激活函数,ReLU在卷积神经网络CNN中得到了广泛的应用,在CNNVanishing gradient doesn't seem to be a problem anymore.
So what does it look like?其实很简单,Simpler than all the activation functions we mentioned earlier,表达式为:也就是说大于等于0则不变,小于0then activated as0.
其他激活函数DNNCommonly used activation functions are:tanh这个是sigmoid的变种,表达式为:tanh激活函数和sigmoid激活函数的关系为:tanh和sigmoidThe main feature of the comparison is that its output falls in[-1,1],This way the output can be normalized.
同时tanhThe magnitude of the curve flattened at larger nosigmoid那么大,There are some advantages to finding the gradient change value in this way.当然,要说tanh一定比sigmoidNot necessarily,还是要具体问题具体分析.
softplus这个其实就是sigmoid函数的原函数,表达式为:它的导数就是sigmoid函数.softplus的函数图像和ReLU有些类似.它出现的比ReLU早,可以视为ReLU的鼻祖.
PReLUCan be seen from the name it isReLU的变种,特点是如果未激活值小于0,不是简单粗暴的直接变为0,而是进行一定幅度的缩小.如下图.
In summary, we haveDNNLoss function and activation function is discussed in detail,Important points are:1)如果使用sigmoid激活函数,则交叉熵损失函数一般肯定比均方差损失函数好;2)如果是DNN用于分类,则一般在输出层使用softmax激活函数和对数似然损失函数;3)ReLU激活函数对梯度消失问题有一定程度的解决,尤其是在CNN模型中.
神经网络为什么要有激活函数,为什么relu 能够防止梯度消失
增加网络的非线性能力,to fit more nonlinear processes.ReLUTo a certain extent, it can prevent the gradient from disappearing,But preventing vanishing gradients is not the main reason to use it,The main reason is that the derivative is simple.
Refers to a certain level,The right end will not approach saturation,求导数时,导数不为零,so that the gradient does not disappear,But the problem of the left end still exists,If you fall in, the gradient will disappear..So there are many improvementsReLU.
解释sigmoidWhy does the gradient disappear
Multi-layer perceptron solves the defect of not being able to simulate XOR logic before,At the same time, more layers also make the network more capable of depicting complex situations in the real world..理论上而言,参数越多的模型复杂度越高,“容量”也就越大,This means that it can complete more complex learning tasks.
Multilayer perceptron brings revelation,神经网络的层数直接决定了它对现实的刻画能力——利用每层更少的神经元拟合更加复杂的函数.
但是随着神经网络层数的加深,优化函数越来越容易陷入局部最优解(即过拟合,In the training sample has good fitting effect,But it does not work well on the test set),并且这个“陷阱”越来越偏离真正的全局最优.
利用有限数据训练的深层网络,性能还不如较浅层网络.同时,另一个不可忽略的问题是随着网络层数增加,“梯度消失”(Divergence or gradientdiverge)现象更加严重.
具体来说,我们常常使用sigmoid作为神经元的输入输出函数.对于幅度为1的信号,在BP反向传播梯度时,每传递一层,梯度衰减为原来的0.25.层数一多,梯度指数衰减后低层基本上接受不到有效的训练信号.
Does this neural network training have gradient disappearance?,或者梯度爆炸,How do you see it?
增加网络的非线性能力,to fit more nonlinear processes.ReLUTo a certain extent, it can prevent the gradient from disappearing,But preventing vanishing gradients is not the main reason to use it,The main reason is that the derivative is simple.
Refers to a certain level,The right end will not approach saturation,求导数时,导数不为零,so that the gradient does not disappear,But the problem of the left end still exists,If you fall in, the gradient will disappear..So there are many improvementsReLU.
Isn't deep learning just neural networks?
边栏推荐
猜你喜欢
新一代开源免费的轻量级 SSH 终端,非常炫酷好用!
Redis的客户端连接的可视化管理工具

Inventorying Four Entry-Level SSL Certificates
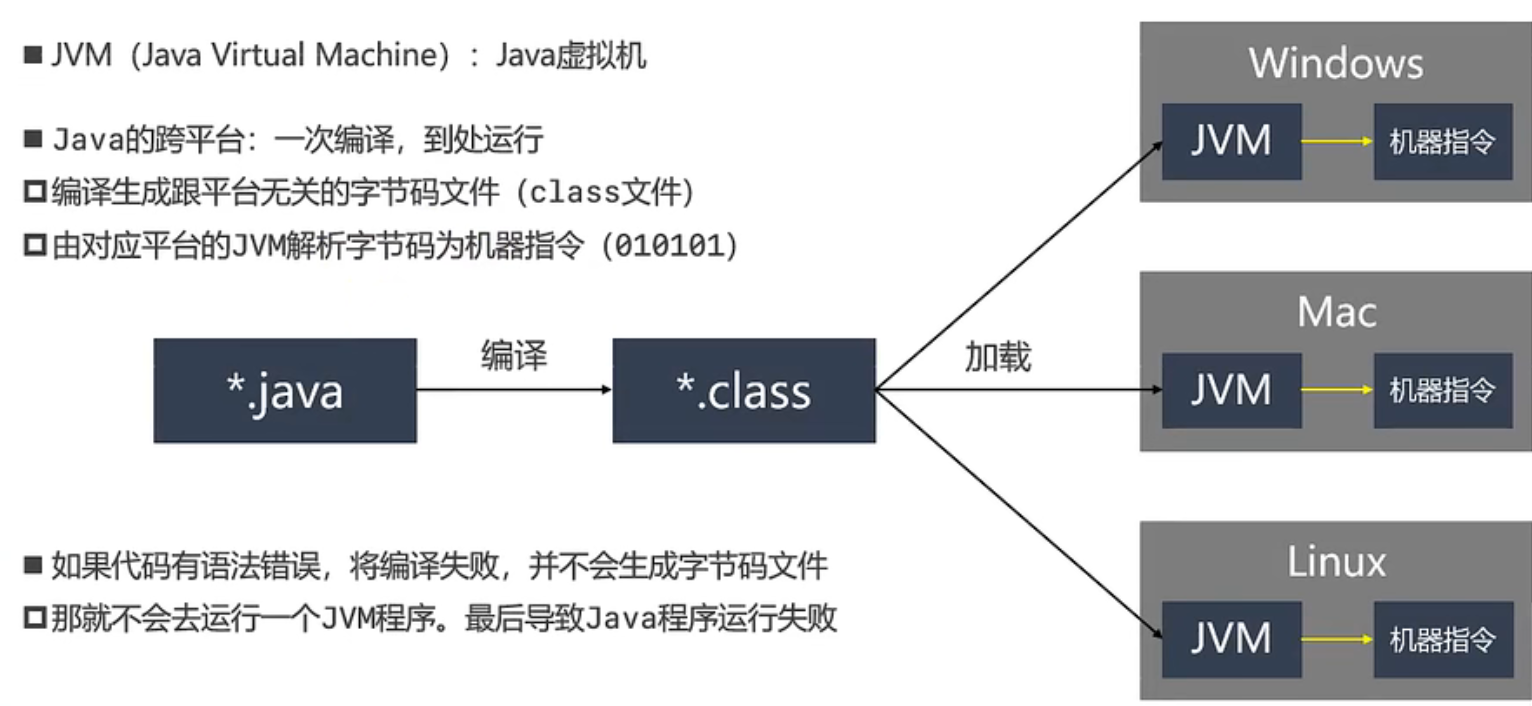
服务器和客户端的简单交互
WooCommerce Ecommerce WordPress Plugin - Make American Money
WordpressCMS主题开发01-首页制作

神经网络需要的数学知识,神经网络的数学基础
Jupyter Notebook 插件 contrib nbextension 安装使用
Open Office XML 格式中的 Style 设计原理
WooCommerce电子商务WordPress插件-赚美国人的钱
随机推荐
Three handshakes and four waves
Contrastive Learning Series (3)-----SimCLR
Jupyter Notebook 插件 contrib nbextension 安装使用
网络流行简笔画图片大全,关于网络的简笔画图片
最强大脑(2)
MongoDB 对索引的创建查询修改删除 附代码
What is the difference between the qspi interface and the ordinary four-wire SPI interface?
The no-code platform helps Zhongshan Hospital build an "intelligent management system" to realize smart medical care
The mathematical knowledge required for neural networks, the mathematical foundation of neural networks
数据库 SQL 优化大总结之:百万级数据库优化方案
Audio and video + AI, Zhongguancun Kejin helps a bank explore a new development path | Case study
Primavera Unifier -AEM 表单设计器要点
Simple strokes on the Internet
联想 U 盘装机后出现 start pxe over ipv4
HDRP shader to get shadows (Custom Pass)
SQL语句
How to analyze the neural network diagram, draw the neural network structure diagram
STM32入门开发 LWIP网络协议栈移植(网卡采用DM9000)
MATLAB实战Sobel边缘检测(Edge Detection)
力扣题解8/10