当前位置:网站首页>Shell正则表达式,三剑客之grep命令
Shell正则表达式,三剑客之grep命令
2022-08-09 11:44:00 【G咖喱炒饭】
目录
一、正则表达式
1、 正则表达式定义
正则表达式又称正规表达式、常规表达式。在代码中常简写为 regex、regexp 或 RE。正则表达式是使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单来说, 是一种匹配字符串的方法,通过一些特殊符号,实现快速查找、删除、替换某个特定字符串。
通常用于判断语句中,用来检查某一字符串是否满足某一格式
正则表达式是由普通字符与元字符组成
普通字符包括大小写字母、数字、标点符号及一些其他符号
元字符是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
Linux 中常用的有两种正则表达式引擎
基础正则表达式:BRE
支持的工具:grep、egrep、sed、awk
扩展正则表达式:ERE
支持的工具:egrep、awk
| 文本处理工具 | 基础正则表达式 | 扩展正则表达式 |
|---|---|---|
| vi 编辑器 | 支持 | \ |
| grep | 支持 | \ |
| egrep | 支持 | 支持 |
| sed | 支持 | \ |
| awk | 支持 | 支持 |
2、基础正则表达式
基础正则表达式是常用的正则表达式部分,常用的元字符及作用如下表所示:
| 元字符 | 作用 |
|---|---|
| \ | 转义字符,用于取消特殊符号的含义,如:\!,\n |
| ^ | 匹配输入字符串的开始位置。除非在方括号表达式中使用,表示不包含该字符集合。如:^world匹配以world开头的行 |
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则“$”也匹配 ''\n' 或' \r '。如:world $匹配以world结尾的行 |
| . | 匹配除 \n (换行)之外的任何的1个字符 |
| * | 匹配前面表达式0次或者多次 |
| [] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a” |
| [^] | 赋值字符集合。匹配未包含的一个任意字符。例如,“abc”可以匹配“plain”中“plin”中的任何一个字母 |
\{n\} | 匹配前面的表达式n次,如:[0-9]\{2\}匹配两位数字 |
\{n,\} | 匹配前面的表达式不少于n次,如:[0-9[\{2,\}表示两位及两位以上数字 |
\{n,m\} | 匹配前面的表达式n到m次,如:[a-z]\{2,3\}匹配两到三位的小写字母 |
| [n1-n2] | 字符范围。匹配指定范围内的任意一个字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意一个小写字母字符。 注意:只有连字符(-)在字符组内部,并且出现在两个字符之间时,才能表示字符的范围;如果出现在字符组的开头,则只能表示连字符本身 |
注意 egrep, awk使用{n}、{n,}、{n,m}匹配时“{}"前不用加“\”
3、拓展正则表达式
扩展正则表达式是对基础正则表达式的扩充和深化
支持的工具有 egerp 和 awk
扩展正则表达式元字符
| 元字符 | 作用与示例 |
|---|---|
| + | 作用:重复一个或者一个以上的前一个字符 示例:执行“egrep -n 'wo+d' test.txt”命令,即可查询"wood""woood""woooooood"等字符串 |
| ? | 作用:零个或者一个的前一个字符 示例:执行“egrep -n 'bes?t' test.txt”命令,即可查询“bet”“best”这两个字符串 |
| | | 作用:使用或者(or)的方式找出多个字符 示例:执行“egrep -n 'of|is|on' test.txt”命令即可查询"of"或者"if"或者"on"字符串 |
| () | 作用:查找“组”字符串示例:“egrep -n 't(a|e)st' test.txt”。“tast”与“test”因为这两个单词的“t”与“st”是重复的,所以将“a”与“e”列于“()”符号当中,并以“|”分隔,即可查询"tast"或者"test"字符串 |
| ()+ | 作用:辨别多个重复的组 示例:“egrep -n 'A(xyz)+C' test.txt”。该命令是查询开头的"A"结尾是"C",中间有一个以上的 "xyz"字符串的意思 |
二、grep命令
1、grep格式,参数选项
grep [选项] 匹配的模式(正则) [目标文件]
选项
-c 只打印匹配的文本行的次数,不显示文本内容。
-i 匹配时忽略字母大小写
-h 当搜索多个文件,不显示匹配文件名前缀。
-l 只列出含义匹配的文本行的文件的文件名,不显示其具体匹配的内容。
-n 列出所有匹配的文本行,并显示行号
-s 不显示关于不存在或无法读取文件的错误信息
-v 只显示不匹配的文本行,反向选择,显示与搜索字符串不相符的行。
-w 匹配整个单词
-x 匹配整个文本行
-r 递归搜索,不仅搜索当前目录,还有各级子目录
-E 开启扩展(extend)的正则表达式
--color=auto 可以将找到的关键词部分加上颜色的显示2、案例实践
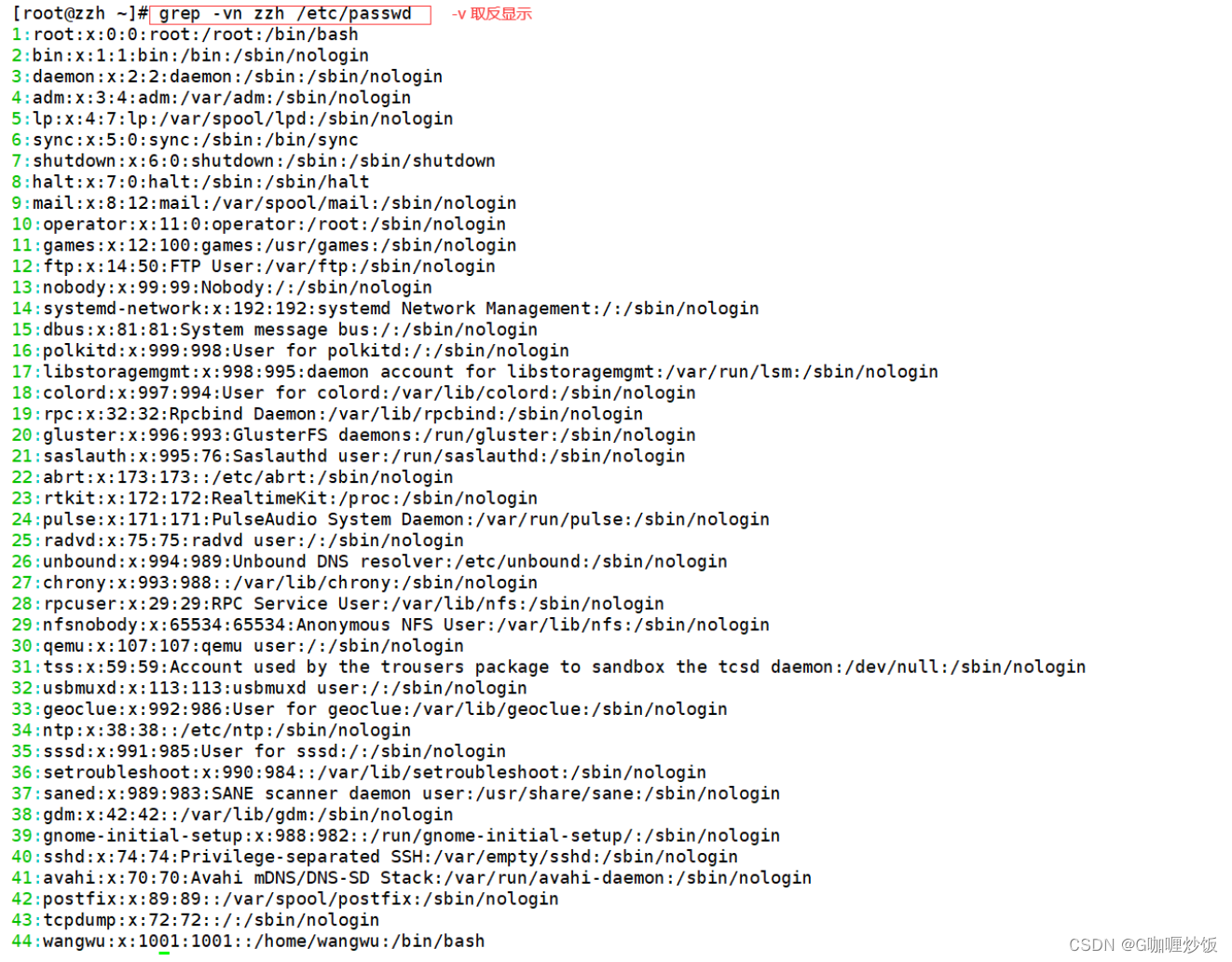
2.1 查找特定字符 显示行号

使用 -v 可以取反
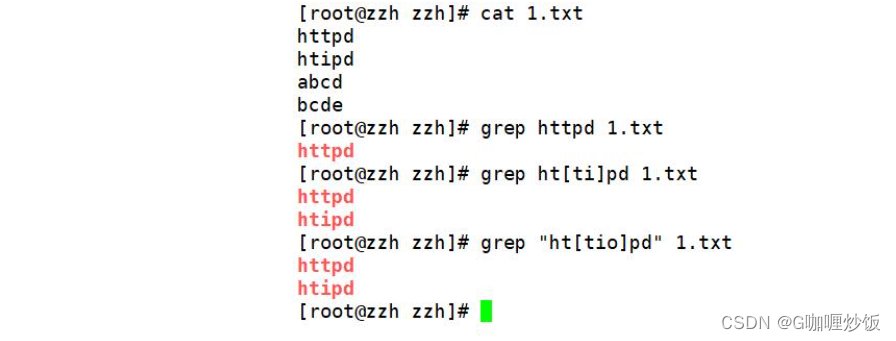
2.2 利用括号 [] 查找集合字符
查找httpd 和 htipd 的时候,两个字符串前后都相同,可以利用 [] 同时查找。
“[]”中无论有几个字符,都仅代表一个字符,也就是说“[ti]”表示匹配“t”或者“i”。
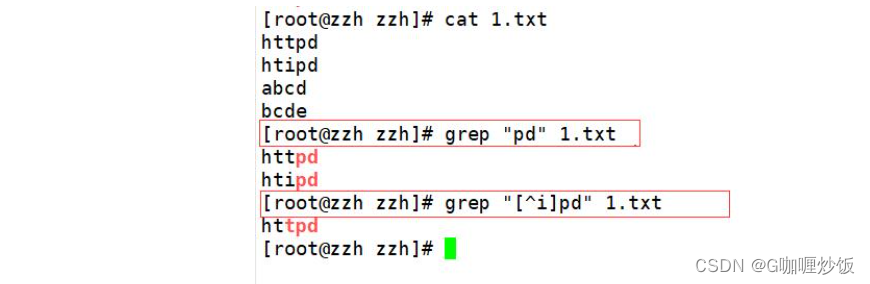
查找某字符串前 不是某一个想查找的字符的时候,可以通过[^]实现
不希望字符串前面存在小写字母,可以用[^a-z]实现,同理大写字母是[^A-Z]。
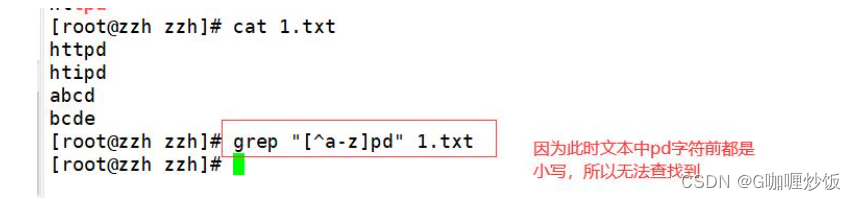
[0-9] #可以用来表示包含数字的字符2.3 查找行首“^”与行尾字符“$”
基础正则表达式包含两个定位元字符:“^”(行首)与“$”(行尾)
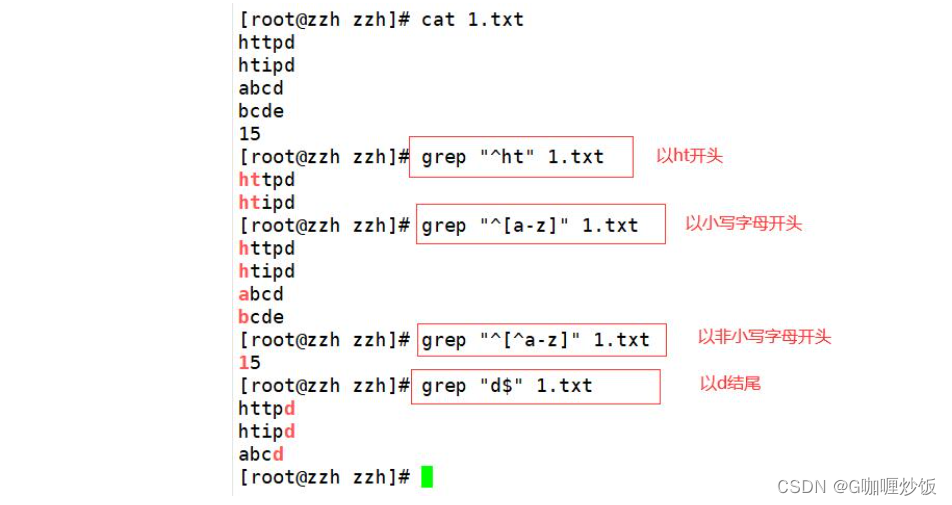
查找空白

2.4 查找任意一个字符“.”与重复字符 “*”
“ . ” 代表任意一个字符
“ * ”代表的是重复零个或多个前面的单字符。“t*”表示拥有零个(即为空字符)或大于等于一个“t"的字符,如果是“tt*”,则第一个 t 必须存在,第二个 t 则是零个或多个 t,所以凡是包含 t、tt、ttt,等的资料都符合标准
2.5.* 任意长度的任意字符

2.6 查找连续字符范围“{}”
我们使用“.”与“*”来设定零个到无限多个重复的字符,如果想要限制一个范围内的重复的字符串该如何实现呢?例如,查找三到五个 o 的连续字符,这个时候就需要使用基础正则表达式中的限定范围的字符“{}”。因为“{}”在Shell中具有特殊 意义,所以在使用“{}”字符时,需要利用转义字符“\”,将“{}”字符转换成普通字符。 “{}”字符的使用方法如下所示。
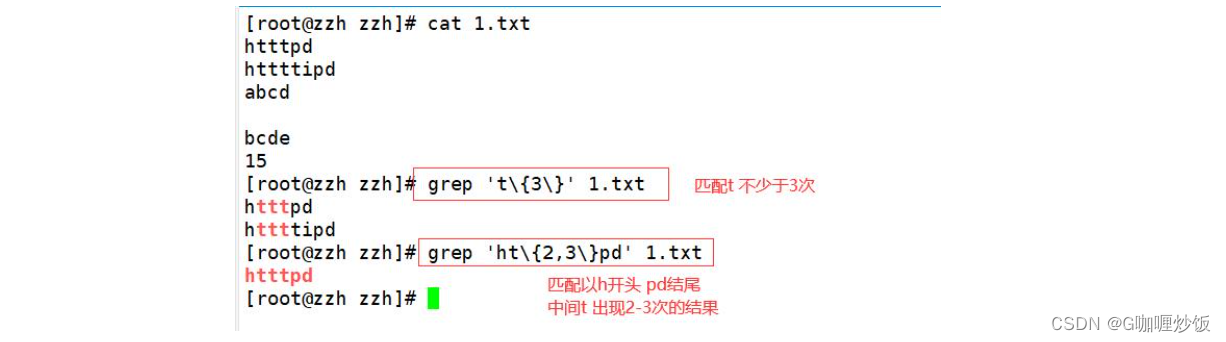
边栏推荐
猜你喜欢
JS封装防抖(代码持续优化)
x86 exception handling and interrupt mechanism (2) interrupt vector table
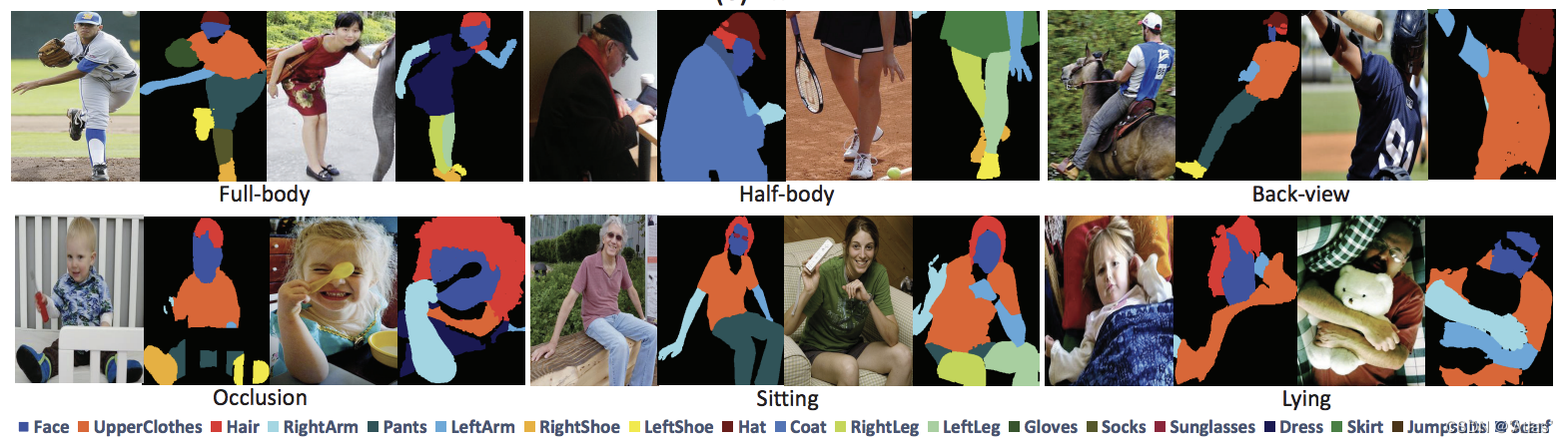
人体解析(Human Parse)开源数据集整理
Chinese valentine's day?Programmers don't exist
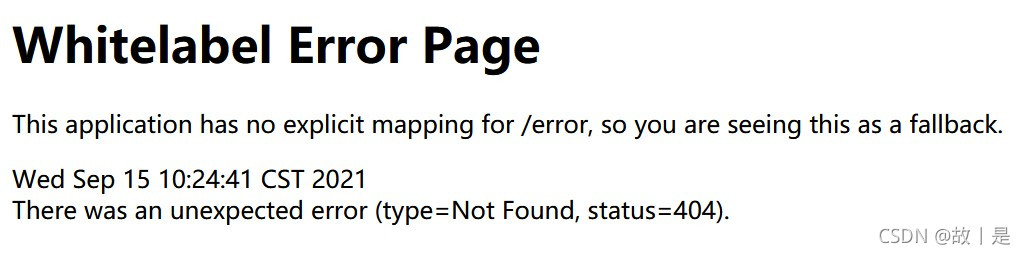
This application has no explicit mapping for /error, so you are seeing this as a fallback
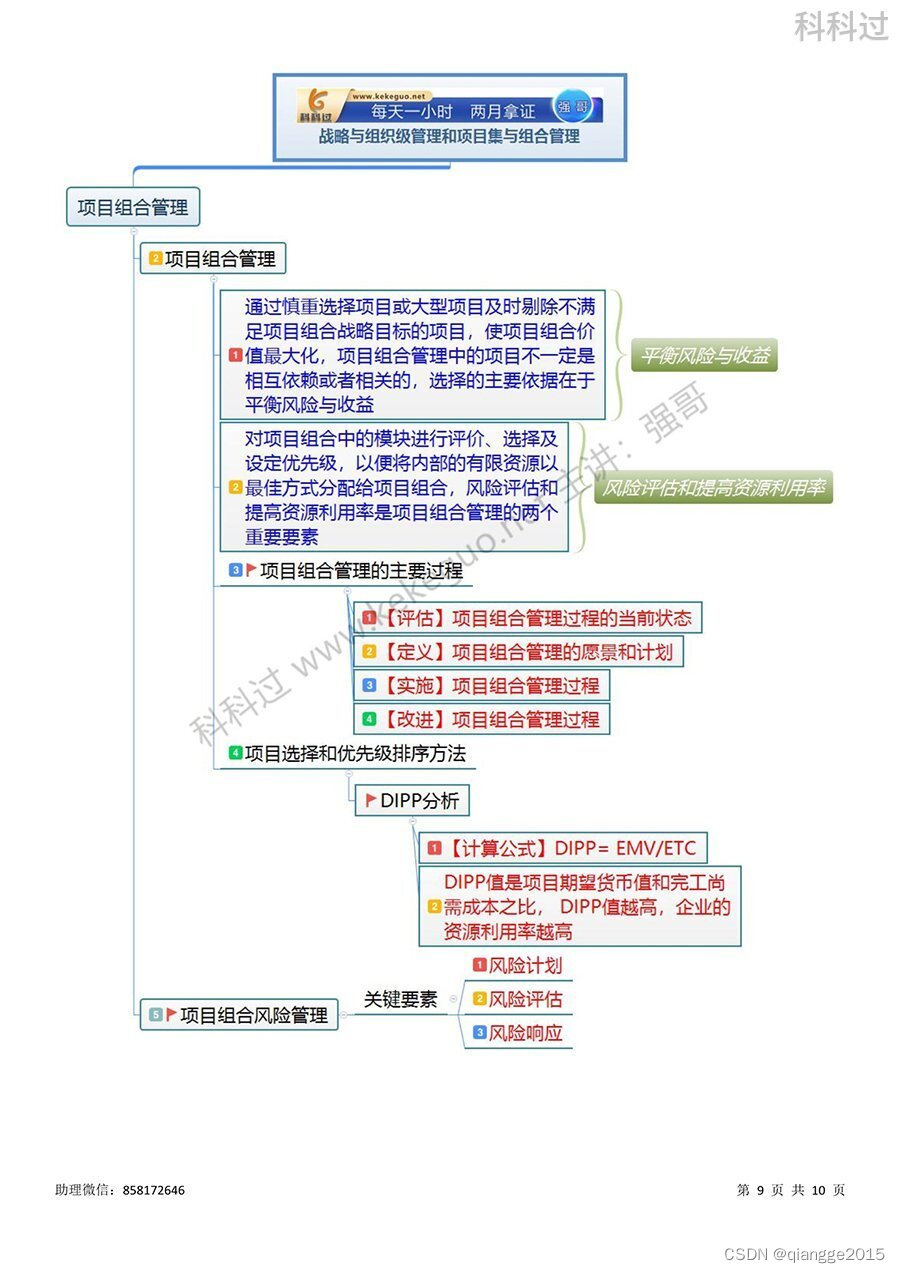
信息系统项目管理师必背核心考点(六十三)项目组合管理的主要过程&DIPP分析

x86 Exception Handling and Interrupt Mechanism (3) Interrupt Handling Process
软件测试——金融测试类面试题,看完直接去面试了

F280049库函数API编程、直接寄存器控制编程和混合编程方法
Win10调整磁盘存储空间详解
随机推荐
从零开始Blazor Server(9)--修改Layout
PTA 实验7-5 输出大写英文字母(10 分)
防止数据冒用的方法
Double pointer - the role of char **, int **
WPF implements a MessageBox message prompt box with a mask
Redis的下载安装
【Data augmentation in NLP】——1
ThreadLocal类
win10右键文件,一直转圈
BeanFacroty和FactoryBean到底是什么?AppliacationContext它又是什么?
web course design
TI的片上固化好的boot ROM(上电引导加载程序)退出后的去向
[现代控制理论]2_state-space状态空间方程
electron 应用开发优秀实践
TIC2000系列处理器在线升级
《数字经济全景白皮书》银行业智能营销应用专题分析 发布
PAT1007
mysql参数学习----max_allowed_packet
杂记(6)
Web console control edit box