当前位置:网站首页>Another data analysis artifact: Polaris is really powerful
Another data analysis artifact: Polaris is really powerful
2022-04-23 20:44:00 【Python data mining】
I believe that for many data analysis practitioners , What we use more is Pandas as well as SQL These two tools ,Pandas Not only can the data set be cleaned and analyzed , And can also draw all kinds of cool charts , But when the data set is large, if you still use Pandas It's obviously a little weak to deal with .
Today I will introduce another data processing and analysis tool , be called Polars, It is faster in data processing , Of course, there are also two API, One is Eager API, The other is Lazy API, among Eager API and Pandas The use of is similar to , The grammatical similarity is not too bad , Immediate execution can produce results . Like this article, remember to collect 、 Focus on 、 give the thumbs-up .
notes : Complete code 、 Information 、 At the end of the technical exchange document

and Lazy API and Spark Very similar , There will be parallel and query logic optimization operations .
Module installation and import
Let's install the module first , Use pip command
pip install polars
After the installation is successful , We use... Separately Pandas and Polars To read data , Look at the differences in their performance , We import the modules we will use
import pandas as pd
import polars as pl
import matplotlib.pyplot as plt
%matplotlib inline
use Pandas Read the file
The data set used this time is the user name data of registered users of a website , All in all 360MB size , We use first Pandas Module to read the csv file
%%time
df = pd.read_csv("users.csv")
df.head()
output

Can be seen with Pandas Read CSV The documents cost a total of 12 The second time , The dataset has two columns in total , One column is the user name , And the number of times the user name is repeated “n”, Let's sort the data set , It's called sort_values() Method , The code is as follows
%%time
df.sort_values("n", ascending=False).head()
output

use Polars To read the operation file
Now let's use Polars Module to read and manipulate files , See how long it takes , The code is as follows
%%time
data = pl.read_csv("users.csv")
data.head()
output

Can be seen with polars Module to read data only costs 730 Time in milliseconds , It can be said that it is much faster , We according to the “n” This column is used to sort the data set , The code is as follows
%%time
data.sort(by="n", reverse=True).head()
output
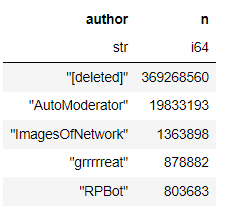
The time taken to sort the dataset is 1.39 second , Next we use polars Module to conduct a preliminary exploratory analysis of the data set , What are the total columns of the dataset 、 What are the names , We are still familiar with “ Titanic ” Data sets, for example
df_titanic = pd.read_csv("titanic.csv")
df_titanic.columns
output
['PassengerId',
'Survived',
'Pclass',
'Name',
'Sex',
'Age',
......]
and Pandas The same output column name calls columns Method , Then let's look at how many rows and columns there are in the dataset ,
df_titanic.shape
output
(891, 12)
Look at the data type of each column in the dataset
df_titanic.dtypes
output
[polars.datatypes.Int64,
polars.datatypes.Int64,
polars.datatypes.Int64,
polars.datatypes.Utf8,
polars.datatypes.Utf8,
polars.datatypes.Float64,
......]
Fill in null values and statistical analysis of data
Let's look at the distribution of null values in the dataset , call null_count() Method
df_titanic.null_count()
output

We can see “Age” as well as “Cabin” There are two empty columns of values , We can try to fill in with the average , The code is as follows
df_titanic["Age"] = df_titanic["Age"].fill_nan(df_titanic["Age"].mean())
To calculate the average value of a column, you only need to call mean() The method can , So the median 、 Maximum / The calculation of the minimum value is the same , The code is as follows
print(f'Median Age: {
df_titanic["Age"].median()}')
print(f'Average Age: {
df_titanic["Age"].mean()}')
print(f'Maximum Age: {
df_titanic["Age"].max()}')
print(f'Minimum Age: {
df_titanic["Age"].min()}')
output
Median Age: 29.69911764705882
Average Age: 29.699117647058817
Maximum Age: 80.0
Minimum Age: 0.42
Data filtering and visualization
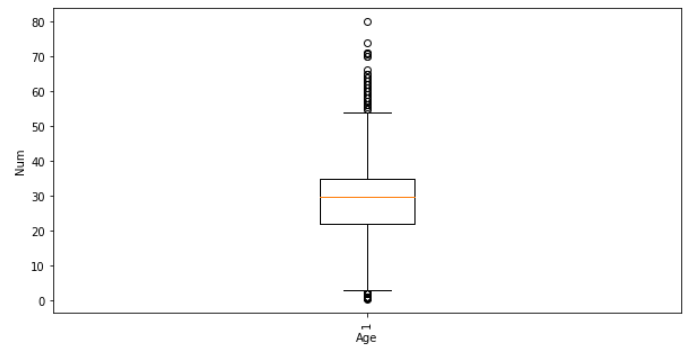
We screened out people older than 40 What are the age-old passengers , The code is as follows
df_titanic[df_titanic["Age"] > 40]
output

Finally, let's simply draw a chart , The code is as follows
fig, ax = plt.subplots(figsize=(10, 5))
ax.boxplot(df_titanic["Age"])
plt.xticks(rotation=90)
plt.xlabel('Age Column')
plt.ylabel('Age')
plt.show()
output
On the whole ,polars In data analysis and processing Pandas Modules have many similarities , There will be part of it API There are differences , Interested children's shoes can refer to its official website :https://www.pola.rs/
Recommended articles
-
Li Hongyi 《 machine learning 》 Mandarin Program (2022) coming
-
Some people made Mr. Wu Enda's machine learning and in-depth learning into a Chinese version
-
So elegant ,4 paragraph Python Automatic data analysis artifact is really fragrant
-
It's very fragrant , Tidy up 20 Visual large screen template
Technical communication
Welcome to reprint 、 Collection 、 Gain some praise and support !

At present, a technical exchange group has been opened , Group friends have exceeded 2000 people , The best way to add notes is : source + Interest direction , Easy to find like-minded friends
- The way ①、 Send the following picture to wechat , Long press recognition , The background to reply : Add group ;
- The way ②、 Add microsignals :dkl88191, remarks : come from CSDN
- The way ③、 WeChat search official account :Python Learning and data mining , The background to reply : Add group

版权声明
本文为[Python data mining]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204232041258613.html
边栏推荐
- go slice
- Linux中,MySQL的常用命令
- LeetCode 20、有效的括号
- 2022DASCTF Apr X FATE 防疫挑战赛 CRYPTO easy_real
- Some basic knowledge of devexpress report development
- High paid programmer & interview question series 91 limit 20000 loading is very slow. How to solve it? How to locate slow SQL?
- Shanghai responded that "flour official website is an illegal website": neglect of operation and maintenance has been "hacked", and the police have filed a case
- On BIM data redundancy theory
- Leetcode 994, rotten orange
- Latest investigation and progress of building intelligence based on sati
猜你喜欢

UnhandledPromiseRejectionwarning:CastError: Cast to ObjectId failed for value

Devexpress 14.1 installation record
Fastdfs思维导图
LeetCode 74、搜索二维矩阵
Plato farm is one of the four largest online IEOS in metauniverse, and the transaction on the chain is quite high

Recognition of high-speed road signs by Matlab using alexnet
100天拿下11K,转岗测试的超全学习指南
Modeling based on catiav6

Rt-1052 learning notes - GPIO architecture analysis

How to configure SSH public key in code cloud
随机推荐
go slice
2021-09-02 unity project uses rider to build hot change project failure record of ilruntime
Go limit depth traversal of files in directory
The problem of 1 pixel border on the mobile terminal
三十一. `prototype`显示原型属性和`__proto__`隐式原型属性
Development of Matlab GUI bridge auxiliary Designer (functional introduction)
Leetcode 74. Search two-dimensional matrix
Leetcode 20. Valid parentheses
Selenium 显示等待WebDriverWait
Recognition of high-speed road signs by Matlab using alexnet
內網滲透之DOS命令
Shanghai responded that "flour official website is an illegal website": neglect of operation and maintenance has been "hacked", and the police have filed a case
Monte Carlo py solves the area problem! (save pupils Series)
Unity asset import settings
Matlab analytic hierarchy process to quickly calculate the weight
Go language development Daily Fresh Project Day 3 Case - Press Release System II
Identification of bolt points in aerial photography based on perception
Leetcode 1337. Row K with the weakest combat effectiveness in the matrix
bounding box iou
MySQL stored procedures and functions