当前位置:网站首页>"Meta function" of tidb 6.0: what is placement rules in SQL?
"Meta function" of tidb 6.0: what is placement rules in SQL?
2022-04-23 20:31:00 【TiDB】
TiDB Some functions are different from others , Such functions can be used as the basis for building other functions , Combine new features , This kind of function is called :Meta Feature.
《 Thinking about the value of basic software products 》 - Huang Dongxu
For a distributed database , How to store data in different nodes is always an interesting topic . Do you sometimes expect to have specific control over which nodes the data is stored on ?
-
When you're in the same TiDB Support multiple services on the cluster to reduce costs , But they are worried that the business pressure after mixed storage interferes with each other
-
When you want to increase the number of copies of important data , Improve business critical availability and data reliability
-
When you want to put hot data leader Put it in a high-performance TiKV For instance , promote OLTP performance
-
When you want to separate hot and cold data ( Thermal data is stored in high-performance media , Cold data vice versa ), Reduce storage costs
-
When you want to deploy in multiple centers , Store the data according to the actual geographical ownership and the location of the data center , To reduce long-distance access and transmission
You may already know ,TiDB Use Placement Driver Component to control the scheduling of replicas , It has a hotspot based , Storage capacity and other scheduling strategies . But these logics were almost uncontrollable for users in the past , You can't control how the data is placed . And this control ability is TiDB 6.0 Of Placement Rules in SQL The data placement framework wants to give users .
TiDB 6.0 The version is officially available based on SQL Interface data placement framework (Placement Rules in SQL). It supports providing the number of copies for any data 、 The role type 、 Flexible scheduling and management capabilities in dimensions such as placement location , This makes it possible to share clusters in multiple services 、 Span AZ Deployment and other scenarios ,TiDB To provide more flexible data management capabilities , Meet various business demands .
Let's look at some specific examples .
Cross regional deployment reduces latency
Imagine you are a service provider , Business is all over the world , Early architecture was centralized design , With the development of business across regions , Business splitting and global deployment , High data access latency in the center , The cost of cross regional traffic is high . As the business evolves , You set out to promote the cross regional deployment of data , To be close to local business . There are two forms of your data architecture , Locally managed area data and globally accessed global configuration data . Local data is updated frequently , Large amount of data , But there are few cross regional visits . Global configuration data , Less data , Low update frequency , But globally unique , Need to support access to any region , The traditional stand-alone database or single region deployment database can not meet the above business demands .
The following is an example , Users will TiDB Deployed across three data centers , Covering North China respectively , User base in East and South China , Allow users in different regions to access local data nearby . In previous versions , Users can indeed deploy in a cross central way TiDB colony , However, data belonging to different user groups cannot be stored in different data centers , The data can only be distributed in different centers according to the logic of uniform distribution of hot spots and data volume . In the case of high frequency access , Users are likely to visit frequently across regions and suffer high delays .

adopt Placement Rules In SQL Ability , You set a placement policy to assign all copies of area data to a specific computer room in a specific area , All data storage , Management is done in this area , Reduces data replication latency across regions , Reduce traffic cost . All you need to do is , Label nodes in different data centers , And create corresponding placement rules :
CREATE PLACEMENT POLICY 'east_cn' CONSTRAINTS = "[+region=east_cn]";CREATE PLACEMENT POLICY 'north_cn' CONSTRAINTS = "[+region=north_cn]";And pass SQL Statement controls the placement of data , Take different urban districts as an example :
ALTER TABLE orders PARTITION p_hangzhou PLACEMENT POLICY = 'east_cn';ALTER TABLE orders PARTITION p_beijing PLACEMENT POLICY = 'north_cn';such , Copies of order data belonging to different cities will be 「 Fix 」 In the corresponding data center .
Business isolation
Suppose you are responsible for the data platform of large Internet enterprises , Internal business includes 2000 Varied , Relevant businesses adopt one or more sets of MySQL To manage , But because there are too many businesses ,MySQL The number of instances is close to 1000 individual , Daily monitoring 、 The diagnosis 、 Version update 、 Safety protection and other work have caused great pressure on the operation and maintenance team , And with the increasing scale of business , The cost of operation and maintenance increases year by year . You want to reduce the cost of operation and maintenance management by reducing the number of database instances , But data isolation between businesses 、 Access security 、 The flexibility of data scheduling and management cost become serious challenges you face .
With the help of TiDB 6.0, Through the configuration of data placement rules , You can easily flexible cluster sharing rules , For example, business A,B Shared resources , Reduce storage and management costs , And business C and D Exclusive resources , Provide the highest isolation . Because multiple businesses share one set TiDB colony , upgrade 、 patch up 、 Backup plan 、 The frequency of daily operation and maintenance management such as capacity expansion and contraction can be greatly reduced , Reduce management burden and improve efficiency .

CREATE PLACEMENT POLICY 'shared_nodes' CONSTRAINTS = "[+region=shared_nodes]";CREATE PLACEMENT POLICY 'business_c' CONSTRAINTS = "[+region=business_c]";CREATE PLACEMENT POLICY 'business_d' CONSTRAINTS = "[+region=business_d]";ALTER DATABASE a POLICY=shared_nodes;ALTER DATABASE b POLICY=shared_nodes;ALTER DATABASE c POLICY=business_c;ALTER DATABASE d POLICY=business_d;be based on SQL Data placement rules of interface , You only use a few TiDB The cluster manages a large number of MySQL example , Data from different businesses are placed in different locations DB, And manage the different through placement rules DB The data under is scheduled to different hardware nodes , Realize the physical resource isolation of data between businesses , Avoid competing for resources , Mutual interference caused by hardware failure and other problems . Avoid cross business data access through account authority management , Improve data quality and data security . In this way of deployment , The number of clusters is greatly reduced , The original upgrade , Daily operation and maintenance work such as monitoring alarm setting will be greatly reduced , Achieve a balance between resource isolation and cost performance , Significantly reduce daily DBA Operation and maintenance management costs .
Master slave multi machine room + Low latency read
Now you are an Internet architect , Hope to pass TiDB Build a local multi data center architecture . Manage through data placement rules , You can make Follower The replica is dispatched to the standby center , Achieve high availability in the same city .
CREATE PLACEMENT POLICY eastnwest PRIMARY_REGION="us-east-1" REGIONS="us-east-1,us-east-2,us-west-1" SCHEDULE="MAJORITY_IN_PRIMARY" FOLLOWERS=4;CREATE TABLE orders (order_id BIGINT PRIMARY KEY, cust_id BIGINT, prod_id BIGINT) PLACEMENT POLICY=eastnwest;meanwhile , You let history queries with low consistency and freshness be read in a timestamp based way ( Stale Read ), This avoids the access delay caused by cross center data synchronization , At the same time, it also improves the hardware utilization of the slave computer room .
SELECT * FROM orders WHERE order_id = 14325 AS OF TIMESTAMP '2022-03-01 16:45:26';summary
TiDB 6.0 Of Placement Rules In SQL Is a very interesting feature : It exposes the internal scheduling ability beyond the control of users in the past , And provides a convenient SQL Interface . You can use it to partition / surface / The data of different levels in the library can be placed freely based on labels , This opens up many scenarios that were previously impossible to achieve . In addition to the above possibilities , We also look forward to exploring more interesting applications with you .
see TiDB 6.0.0 Release Notes , immediately Download trial , Turn on TiDB 6.0.0 Enterprise Cloud database journey .
版权声明
本文为[TiDB]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204210550494306.html
边栏推荐
- JDBC database addition, deletion, query and modification tool class
- LeetCode 116. 填充每个节点的下一个右侧节点指针
- Why does ES6 need to introduce map when JS already has object type
- Commande dos pour la pénétration de l'Intranet
- Plato Farm元宇宙IEO上线四大,链上交易颇高
- Alicloud: could not connect to SMTP host: SMTP 163.com, port: 25
- Resolve the eslint warning -- ignore the warning that there is no space between the method name and ()
- Common form verification
- 2022dasctf APR x fat epidemic prevention challenge crypto easy_ real
- LeetCode 994、腐烂的橘子
猜你喜欢

Go zero framework database avoidance Guide
![Es error: request contains unrecognized parameter [ignore_throttled]](/img/17/9131c3eb023b94b3e06b0e1a56a461.png)
Es error: request contains unrecognized parameter [ignore_throttled]
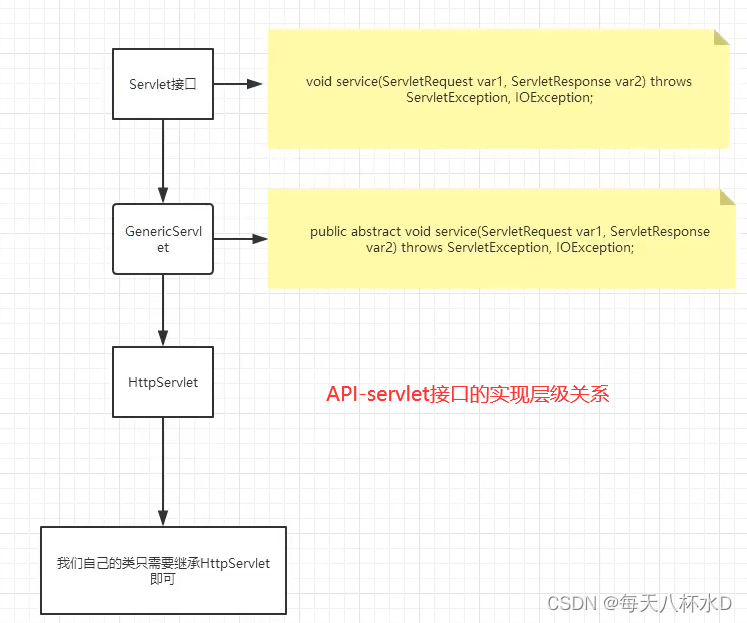
Servlet learning notes
The construction and use of Fortress machine and springboard machine jumpserver are detailed in pictures and texts
GO语言开发天天生鲜项目第三天 案例-新闻发布系统二

LeetCode 994、腐烂的橘子
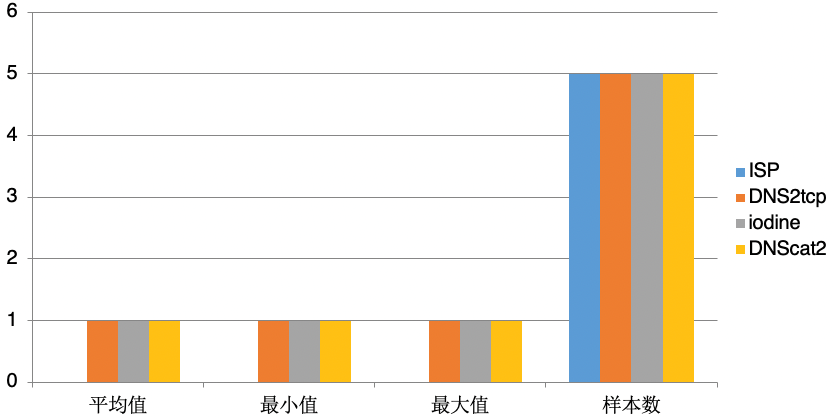
DNS cloud school | analysis of hidden tunnel attacks in the hidden corner of DNS
![Azkaban recompile, solve: could not connect to SMTP host: SMTP 163.com, port: 465 [January 10, 2022]](/img/1a/669c330e64af8e75f4b05e472d03d3.png)
Azkaban recompile, solve: could not connect to SMTP host: SMTP 163.com, port: 465 [January 10, 2022]
Shanghai a répondu que « le site officiel de la farine est illégal »: l'exploitation et l'entretien négligents ont été « noirs » et la police a déposé une plainte

Matlab analytic hierarchy process to quickly calculate the weight
随机推荐
LeetCode 20、有效的括号
Customize timeline component styles
LeetCode 994、腐烂的橘子
Zdns was invited to attend the annual conference of Tencent cloud basic resources and share the 2020 domain name industry development report
LeetCode 116. Populate the next right node pointer for each node
【PTA】L2-011 玩转二叉树
LeetCode 1346、检查整数及其两倍数是否存在
高薪程序员&面试题精讲系列91之Limit 20000加载很慢怎么解决?如何定位慢SQL?
How to configure SSH public key in code cloud
How many hacking methods do you know?
Automatically fill in body temperature and win10 task plan
The ODB model calculates the data and outputs it to excel
6-5 字符串 - 2. 字符串复制(赋值) (10 分)C语言标准函数库中包括 strcpy 函数,用于字符串复制(赋值)。作为练习,我们自己编写一个功能与之相同的函数。
LeetCode 1337、矩阵中战斗力最弱的 K 行
JS arrow function user and processing method of converting arrow function into ordinary function
What is the difference between a host and a server?
Latest investigation and progress of building intelligence based on sati
Solve the Chinese garbled code of URL in JS - decoding
Leetcode 1346. Check whether integers and their multiples exist
Leetcode 232, queue with stack