当前位置:网站首页>③ 关系数据库标准语言SQL 数据查询(SELECT)
③ 关系数据库标准语言SQL 数据查询(SELECT)
2022-08-11 00:00:00 【只爭朝夕不負韶華】
查看专栏更多内容:
② 关系数据库标准语言SQL 数据定义(创建、修改基本表)、数据更新(增删改)
相关实战:
关系数据库标准语言SQL
写下博客用于自我复习、自我总结。
如有错误之处,请各位指出。
数据查询
数据查询是数据库的核心操作。MySQL 数据库使用 SELECT 语句来查询数据。
其一般格式为:([]中的内容为可选项,<>中的内容为必填项)
SELECT [ALL|DISTINCT] <目标列表达式> [,<目标列表达式>] ...
FROM <表名或视图名> [,<<表名或视图名>>]
[WHERE <条件表达式>]
[GROUP BY <列名1> [HAVING <条件表达式>]]
[ORDER BY <列名2> [ASC|DESC]]
整个SELECT语句的基本含义是,根据 WHERE 子句的条件表达式从 FROM 子句指定的基本表、视图或派生表中找出满足条件的元组,再按 SELECT 子句中的目标列表达式选出元组中的属性值形成结果表。
如果有 GROUP BY 子句,则将结果按<列名1>的值进行分组,该属性列值相等的元组为一个组。通常会在每组中作用聚集函数。如果 GROUP BY 子句带 HAVING 短语,则只有满足指定条件的组才予以输出。
如果有 ORDER BY 子句,则结果表还要按<列名2>的值的升序(ASC)或降序(DESC)排序。
SELECT语句既可以完成简单的单表查询,也可以完成复杂的连接查询和嵌套查询。上述内容将会在下面逐个演示。
下面就以之前提到的学生-课程数据库为例说明SELECT语句的各种用法。
建表,插入数据:
CREATE TABLE Student
(Sno CHAR(9) PRIMARY KEY, /*列级完整性约束条件,Sno是主码*/
Sname CHAR(20) UNIQUE, /*Sname取唯一值*/
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20)
);
CREATE TABLE Course
(Cno CHAR(4) PRIMARY KEY, /*列级完整性约束条件,Cno是主码*/
Cname CHAR(40) NOT NULL, /*列级完整性约束条件,Cname不能取空值*/
Cpno CHAR(4), /*Cpno的含义是先修课*/
Ccredit SMALLINT,
FOREIGN KEY(Cpno)REFERENCES Course(Cno)
/*表级完整性约束条件,Cpno是外码,被参照表是Course,被参照列是Cno*/
);
CREATE TABLE SC
(Sno CHAR(9),
Cno CHAR(4),
Grade SMALLINT,
PRIMARY KEY(Sno,Cno), /*主码由两个属性构成:必须作为表级完整性进行定义*/
FOREIGN KEY(Sno)REFERENCES Student(Sno),
/*表级完整性约束条件,Sno是外码,被参照表是Student*/
FOREIGN KEY(Cno)REFERENCES Course(Cno)
/*表级完整性约束条件,Cno是外码,被参照表是Course*/
);
insert into Student
values('201215121','李勇','男',20,'CS');
insert into Student
values('201215122','刘晨','女',19,'CS');
insert into Student
values('201215123','王敏','女',18,'MA');
insert into Student
values('201215125','张立','男',19,'IS');
insert into Course
values('1','数据库','5',4);
insert into Course
values('2','数学',NULL,2);
insert into Course
values('3','信息系统','1',4);
insert into Course
values('4','操作系统','6',3);
insert into Course
values('5','数据结构','7',4);
insert into Course
values('6','数据处理',NULL,2);
insert into Course
values('7','PASCAL语言','6',4);
insert into SC
values('201215121','1',92);
insert into SC
values('201215121','2',85);
insert into SC
values('201215121','3',88);
insert into SC
values('201215122','2',90);
insert into SC
values('201215122','3',80);
单表查询
(1)选择表中若干列
选择表中的全部或部分列,即关系代数的投影运算。
例1:查询全体学生的学号与姓名
SELECT Sno,Sname
FROM Student;
例2:查询全体学生的全部信息
SELECT *
FROM Student;
-- * 用于查询所有信息,它等价于下面的内容
SELECT Sno,Sname,Ssex,Sage,Sdept
FROM Student;
例3:查询全体学生的姓名及其出生年份
SELECT Sname,2021-Sage
FROM Student;
我们从查询的结果可以发现,SELECT 子句的<目标列表达式>不仅可以是表中的属性列也可以是算术表达式。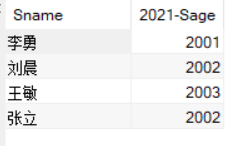
除此以外,它还可以是字符串常量、函数等。
例4:查询全体学生的姓名、出生年份和所在院系,要求用小写字母表示系名
SELECT Sname,'Year of Birth',2021-Sage,LOWER(Sdept)
FROM Student;
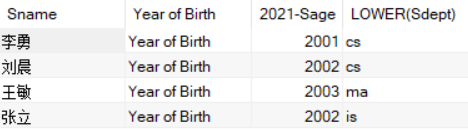
这么做之后,我们可能不想展示 函数名或者表达式 在列名上,比如这里的LOWER(Sdept)。所以,我们是有办法通过指定别名来改变查询结果的列标题的,这对于含算术表达式、常量、函数名的目标列表达式尤为有用。比如现在我们可以这么做:
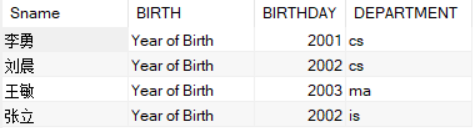
SELECT Sname,'Year of Birth' BIRTH,2021-Sage BIRTHDAY,LOWER(Sdept) DEPARTMENT
FROM Student;
例5:查询选修了课程的学生学号
SELECT Sno
FROM SC;
在这种条件下,我们会得到下面的结果:
我们有时会获得很多重复数据,此时我们可以用关键词 DISTINCT 来去掉重复行。
SELECT DISTINCT Sno
FROM SC;
除了DISTINCT其实还有个ALL,只不过我们默认情况下就会获得满足条件的所有数据,所以ALL被省略了。即省略前是这样的,它等价于例5结果:
SELECT ALL Sno
FROM SC;
(2)选择表中若干元组
我们在查询的时候肯定是通过WHERE子句来实现,它常用的查询条件如下图所示: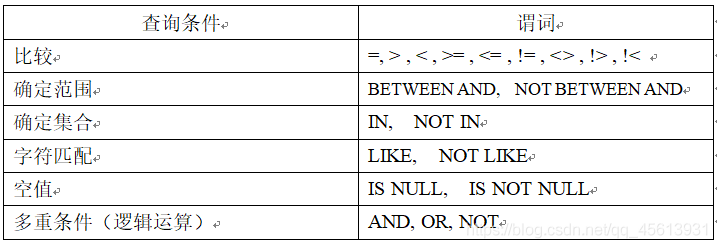
例1:查询计算机科学系全体学生的名单
SELECT Sname
FROM Student
WHERE Sdept = 'CS';
例2:查询所有年龄在20岁以下的学生姓名及其年龄
SELECT Sname,Sage
FROM Student
WHERE Sage < 20;
例3:查询年龄在20~23岁(包括20和23)之间的学生姓名、系别和年龄
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;
例4:查询CS、MA、IS系的学生姓名和性别
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN('CS','MA','IS');
例5:查询没有成绩的学生学号和课程号
SELECT Sno,Cno
FROM SC
WHERE Grade IS NULL;
例6:查询计算机科学系年龄在20岁以下的学生姓名
SELECT Sname
FROM Student
WHERE Sdept = 'CS' AND Sage < 20;
字符匹配
谓词LIKE可以用来进行字符串的匹配。其一般语法格式如下:
[NOT] LIKE '<匹配串>' [ESCAPE '<换码字符>']
其含义是查找指定的属性列值与<匹配串>相匹配的元组。<匹配串>可以是一个完整的字符串,也可以含有通配符 % 和 _ 。其中:
- %(百分号)代表任意长度(长度可以为0)的字符串。例如
a%b表示以 a 开头,以 b 结尾的任意长度字符串。比如 acb、addgb、ab 都满足该匹配串。 - _(下横线)代表任意单个字符。例如
a_b表示以 a 开头,以 b 结尾的长度为3的任意字符串。比如 acb、afb 都满足该匹配串。 - 它们的组合就可以用来设计更多匹配串,比如:
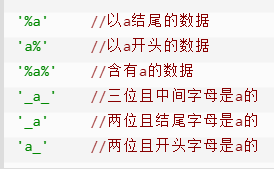
更多内容可以参考:MySQL LIKE 子句
例7:查询所有姓刘的学生姓名、学号和性别
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname LIKE '刘%';
例8:查询名字中第二个字为“阳”的学生姓名和学号
SELECT Sname,Sno
FROM Student
WHERE Sname LIKE '_阳%';
例9:查询以“DB_”开头,且倒数第三个字符为i的课程的详细情况
如果我们直接用_,那匹配串中的_将会被当作通配符,我们想让_变为普通的字符,我们就会用到ESCAPE。ESCAPE'\'表示 \为换码字符。这样匹配串中紧跟在\后的字符_就不再是通配符,而是普通的字符。
SELECT *
FROM Course
WHERE Cname LIKE 'DB\_%i__'ESCAPE'\';
(该用法在SQL_Front中不能使用)
(3)ORDER BY 子句
用户可以用ORDER BY子句对查询结果按照一个或者多个属性列的升序(ASC)或降序(DESC)排序,默认值为升序。
例1:查询选修了3号课程的学生学号及其成绩,查询结果按分数的降序排列
SELECT Sno,Grade
FROM SC
WHERE Cno = '3'
ORDER BY Grade DESC;
对于空值,排序时显示的次序将会由具体系统实现来决定。
例2:查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列
SELECT *
FROM Student
ORDER BY Sdept,Sage DESC;
(4)聚集函数
为了进一步方便用户,增强检索功能,SQL提供了许多聚集函数,主要有:
COUNT(*) // 统计元组个数
COUNT([DISTINCT|ALL] <列名>) // 统计一列中值的个数
SUM([DISTINCT|ALL] <列名>) // 计算一列值的总和(此列必须是数值型)
AVG([DISTINCT|ALL] <列名>) // 计算一列值的平均值(此列必须是数值型)
MAX([DISTINCT|ALL] <列名>) // 求一列值中的最大值
MIN([DISTINCT|ALL] <列名>) // 求一列值中的最小值
如果指定DISTINCT短语,则表示在计算时会取消指定列中的重复值。如果不指定DISTINCT短语或指定ALL短语(ALL为默认值),则表示不取消重复值。
例1:查询学生总人数
SELECT COUNT(*)
FROM Student;
例2:查询选修了课程的学生人数
SELECT COUNT(DISTINCT Sno)
FROM SC;
例3:计算选修1号课程的学生平均成绩
SELECT AVG(Grade)
FROM SC
WHERE Cno = '1';
当聚集函数遇到空值时,除COUNT(*)外,都跳过空值而只处理非空值。COUNT(*)是对元组进行计数,某个元组的一个或部分列取空值不影响COUNT的统计结果。
注:WHERE子句中是不能直接用聚集函数作为条件表达式的,需要使用到GROUP BY中的HAVING子句。
(5)GROUP BY 子句
GROUP BY 子句会将查询结果按某一列或多列的值分组,值相等的为一组。对查询结果分组的目的是为了细化聚集函数的作用对象。如果未对查询结果分组,聚集函数将作用于整个查询结果。分组后聚集函数将作用于每一个组。比如看例1。
例1:求各个课程号及相应的选课人数
如果不用GROUP BY,聚集函数就会作用于整个查询结果,得到1组数据:
SELECT Cno,COUNT(Sno)
FROM SC;

现在用GROUP BY 对查询结果按Cno的值分组,就会获得多组数据:
SELECT Cno,COUNT(Sno)
FROM SC
GROUP BY Cno;
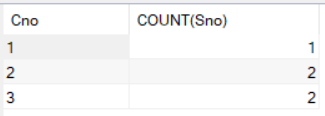
如果分组后还要求按一定的条件对这些组进行筛选,最终只输出满足指定条件的组,则可以使用HAVING短语指定筛选条件。
例2:查询选修了两门以上课程的学生学号和他们的选课数
SELECT Sno,COUNT(*) '选课数'
FROM SC
GROUP BY Sno
HAVING COUNT(*) > 2;
简单解析:使用GROUP BY后,数据就会按Sno分组,值相等的为一组,即按学生学号分成了多个组。现在想得知他们选修课程的数量,需要使用COUNT。但如果想用聚集函数作为查询条件,不能使用WHERE,而是选用HAVING,所以将表达式写在HAVING后。这样做之后,聚集函数COUNT就会对每一组计数,再将满足条件的组选出来并展示。
WHERE 子句 与 HAVING 短语的区别在于作用对象不同。WHERE 子句作用于基本表或视图,从中选择满足条件的元组。HAVING 短语作用于组,从中选择满足条件的组。
也就是说,这么用是错误的:
SELECT Sno,COUNT(*) '选课数'
FROM SC
WHERE COUNT(*) > 2
GROUP BY Sno
例3:
SELECT Sno,AVG(Grade) '平均分',MIN(Grade) '最低分',MAX(Grade) '最高分',COUNT(*) '选课次数'
FROM SC
GROUP BY Sno
HAVING AVG(Grade) >= 70 AND COUNT(*) >= 3;
例4:
SELECT Sno,Grade
FROM SC
WHERE Grade > 70
GROUP BY Sno
HAVING COUNT(*) >= 1
ORDER BY 1 desc;
如果涉及到 WHERE、GROUP BY 、HAVING 、 ORDER BY,它们的排列顺序如上例4所示。
(ORDER BY 后可以不用写具体的列名,可以像例4一样,使用列号。比如这里的1,指的是按Sno列的降序排列,如果写2,指的是按Grade列的降序排列)
其中注意:排序一定需要在最后一行!
连接查询
前面的查询都是针对一个表进行的。若一个查询同时涉及两个以上的表,则称之为连接查询。
(1)等值与非等值连接查询
连接查询的WHERE子句中用来连接两个表的条件称为连接条件或连接谓词。当连接运算符为 = 时,称为等值连接。使用其他运算符称为非等值连接。连接谓词中的列名称为连接字段。连接条件中的各连接字段类型必须是可比的,但名字不必相同。
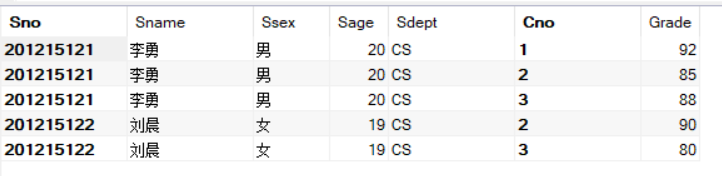
例1:查询每个学生及其选修课程的情况
SELECT *
FROM Student,SC
WHERE Student.Sno = SC.Sno;
简单解析:学生情况存放在Student表中,学生选课情况存放在SC表中,所以这里肯定需要这两个表。而这两个表的联系是通过公共属性Sno实现的。它的查询结果是这样的:
通过结果我们可以看到有重复的列,如果在等值连接中把目标列中重复的属性列去掉则为自然连接。实现起来很简单,如果属性列的列名是唯一的,在引用时可以去掉表名前缀,如果重复了,引用时附加其中一个表名前缀即可。即:
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student,SC
WHERE Student.Sno = SC.Sno;
而执行这个操作的一个可能过程是:首先在表Student中找到第一个元组,然后从头开始扫描SC表,逐一查找与Student第一个元组的Sno相等的SC元组,找到后就将Student中的第一个元组与该元组拼接起来,形成结果表中一个元组。SC全部查找完后,再找Student中第二个元组,然后再从头开始扫描SC,逐一查找满足连接条件的元组,找到后就将Student中的第二个元组与该元组拼接起来,形成结果表中一个元组。重复上述操作,直到Student中的全部元组都处理完毕为止。
很显然的是,这个过程需要完整扫描SC表多次,如果在SC表Sno上建立了索引的话,那么之后就会根据Sno值通过索引找到相应的SC元组。这样就会提高扫描速度。
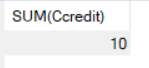
例2:查询学生 201215121 选修课程的总学分数
SELECT SUM(Ccredit)
FROM SC,Course
WHERE Sno = '201215121' AND SC.Cno = Course.Cno;
简单解析:这里涉及到了多表查询。在这里需要用到多个表是因为学生的选课信息存放在SC表中,但SC表中没有学分数,所以除了用到SC表还需要用到查询学分数的Course表。它们之间的逻辑关系是,在SC表中寻找学号为201215121的学生的选修课程,然后去Course表查询这些课程的学分并求和。
该查询的一种优化执行过程是,先从SC中挑选出学号为 201215121 的元组形成一个中间关系,再和Course中满足连接条件的元组进行连接得到最终的结果关系。
其实内容很简单,但是初次看到代码可能有点难以理解,现在对代码拆分一下:
第一步:
SELECT *
FROM SC
WHERE Sno = '201215121'
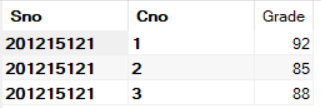
第二步:
SELECT *
FROM SC,Course
WHERE Sno = '201215121' AND SC.Cno = Course.Cno;

现在已经获取到了相关信息,再简化看一下:
SELECT Sno,SC.Cno,Ccredit
FROM SC,Course
WHERE Sno = '201215121' AND SC.Cno = Course.Cno;
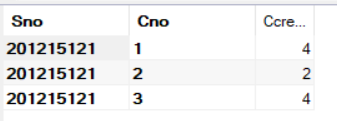
最后,我们用聚集函数SUM对值求和即可。
SELECT SUM(Ccredit)
FROM SC,Course
WHERE Sno = '201215121' AND SC.Cno = Course.Cno;
(2)自身连接
连接操作不仅可以在两个表之间进行,也可以是一个表与其自己进行连接。
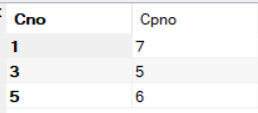
例1:查询每一门课的间接先修课(即先修课的先修课)
简单解析: 在Course表中,只有每门课的直接先修课信息,而没有先修课的先修课。要得到这个信息,必须先对一门课找到其先修课,再按此先修课的课程号查找它的先修课。这就要将Course表与其自身连接。自身连接的时候需要为Course表取两个别名:
SELECT FIRST.Cno,SECOND.Cpno
FROM Course FIRST,Course SECOND
WHERE FIRST.Cpno = SECOND.Cno
AND SECOND.Cpno IS NOT NULL;
(3)外连接
在通常的连接操作中,只有满足连接条件的元组才能作为结果输出。我们在文章顶部设置的数据中,201215123和201215125两个学生没有选课信息,因此它们也不会出现在任何有关SC表的查询结果中。假设,我们想知道每个学生的基本情况及其选课情况,若某学生未选课,仍把Student的悬浮元组保存在结果关系中,而在SC表的属性上填空值NULL,这时就需要使用外连接。外连接的概念已经在文章①中给出样例进行过说明,在这里就不再赘述。
左外连接就是列出左边关系中所有的元组,用LEFT OUTER JOIN;右外连接就是列出右边关系中所有的元组,用RIGHT OUTER JOIN;内连接(等值连接)用INNER JOIN(也可省略为JOIN)。
上述问题结果: 因为我们想知道学生选课情况,所以要保证Student中所有元组都被保留下来,所以可以这样写:
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student LEFT OUTER JOIN SC
ON(Student.Sno = SC.Sno);
注:这里用ON,而不是用WHERE来设置查询条件。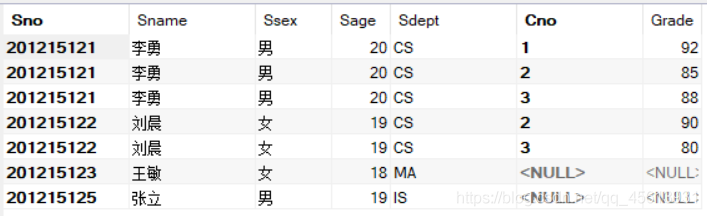
如果只针对上面代码,将左外连接改成右外连接,很显然,如果保留SC中所有元组,因为SC中没有201215123和201215125,所以这两个学生的信息就会被删去。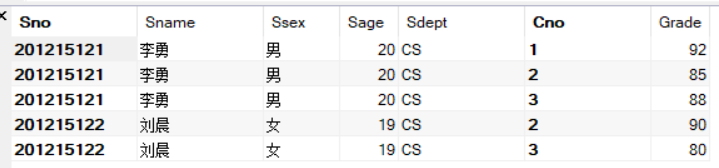
等值连接:
SELECT Student.Sno,Sname,Ssex,Sage,Sdept,Cno,Grade
FROM Student JOIN SC
ON(Student.Sno = SC.Sno);
嵌套查询
在SQL语言中,一个 SELECT - FROM - WHERE 语句称为一个查询块。将一个查询块嵌套在另一个查询块的 WHERE 子句或 HAVING 短语的条件中的查询称为嵌套查询。
例1:查询与“刘晨”在同一个系学习的学生
简单解析: 在嵌套查询中,子查询的结果往往是一个集合,所以谓词 IN 是嵌套查询中最经常使用的谓词。为了更容易理解,可以分布来解析:
(1)确定“刘晨”所在系名
SELECT Sdept
FROM Student
WHERE Sname = '刘晨';
结果为CS
(2)查找所有在CS系学习的学生
SELECT Sno,Sname,Sdept
FROM Student
WHERE Sdept = 'CS';
结果为: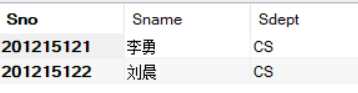
将(1)中查询嵌入到(2)查询的条件中(用IN),就构造出了嵌套查询。
SELECT Sno,Sname,Sdept /*外层查询或父查询*/
FROM Student
WHERE Sdept IN
(SELECT Sdept /*内层查询或子查询*/
FROM Student
WHERE Sname = '刘晨');
但其实,在这里的 IN 也可以改写为 =,因为子查询的结果只能是一个值,(因为在这里假设)一个学生只可能在一个系学习,如果为多个那显然只能用IN。
本例中,子查询的查询条件不依赖于父查询,称为不相关子查询。
SQL语言允许多层嵌套查询,即一个子查询中还可以嵌套其它子查询。需要特别指出的是,子查询的 SELECT 语句中不能使用 ORDER BY 子句,ORDER BY 子句只能对最终查询结果排序。
嵌套查询使用户可以用多个简单查询构成复杂的查询,从而增加SQL的查询能力。比如在本例中,还可以有以下几种解答方案:
SELECT FIRST.Sno,FIRST.Sname,FIRST.Sdept
FROM Student FIRST,Student SECOND
WHERE FIRST.Sdept = SECOND.Sdept
AND SECOND.Sname = '刘晨'
SELECT FIRST.Sno,FIRST.Sname,FIRST.Sdept
FROM Student FIRST JOIN Student SECOND
ON FIRST.Sdept = SECOND.Sdept
AND SECOND.Sname = '刘晨'
可见,实现同一个查询请求可以有多种方法,当然不同的方法其执行效率可能会有差别,甚至会差别很大。这就涉及到数据库的性能优化了。(笔者认为,嵌套查询是最好理解的)
相对的,相关子查询就是:如果子查询的查询条件依赖于父查询,这类子查询称为相关子查询。举例如下:
例2:找出每个学生超过他自己选修课程平均成绩的课程号
SELECT Sno,Cno
FROM SC x
WHERE Grade >=(SELECT AVG(Grade)
FROM SC y
WHERE y.Sno = x.Sno);
在这里,子查询是求一个学生所有选修课程平均成绩的,至于是哪个学生的平均成绩要看参数 x.Sno 的值,而这个值是与父查询相关的,因此这类查询称为相关子查询。
例3:查询选修了课程名为“信息系统”的学生学号和姓名
SELECT Sno,Sname
FROM Student
WHERE Sno IN
(SELECT Sno
FROM SC
WHERE Cno IN
(SELECT Cno
FROM Course
WHERE Cname = '信息系统'
)
);
该查询同样可以用连接查询实现:
SELECT Student.Sno,Sname
FROM Student,SC,Course
WHERE Student.Sno = SC.Sno AND
SC.Cno = Course.Cno AND
Course.Cname = '信息系统';
SELECT Student.Sno,Sname
FROM Student JOIN SC
ON Student.Sno = SC.Sno JOIN Course
ON SC.Cno = Course.Cno
AND Cname = '信息系统'
有些嵌套查询可以用连接运算提代,有些是不能替代的。因为目前商用关系数据库管理系统对嵌套查询的优化做得还不够完善,所以在实际应用中,能够用连接运算表达的查询尽可能采用连接运算。
除此以外,对于查询还有很多用法,但就笔者来看并不是很常用,所以就不在这里演示了。
SQL集合查询:并UNION、差EXCEPT、交INTERSECT
边栏推荐
- Dump file generation, content, and analysis
- 只会懒汉式和饿汉式 你还不懂单例模式!
- 【redis】发布和订阅消息
- 如何利用原生JS实现回到顶部以及吸顶效果
- 【.NET Core】使用 NPOI 读写Excel 文件
- 三栏布局实现
- 从0开始设计JVM ,忘记名词跟上思路一次搞懂
- How to quickly grasp industry opportunities and introduce new ones more efficiently is an important proposition
- YOLOv5的Tricks | 【Trick11】在线模型训练可视化工具wandb(Weights & Biases)
- 9. Rest style request processing
猜你喜欢
李彦宏拆墙交朋友,大厂“塑料友情”能否帮百度啃下硬骨头?

只会懒汉式和饿汉式 你还不懂单例模式!
Deep Learning Transformer Architecture Analysis
百战RHCE(第四十八战:运维工程师必会技-Ansible学习3-构建Ansible清单)
地下管廊可视化管理系统搭建
12. 处理 JSON
![[数据可视化] 图表设计原则](/img/f3/691dd58d1e334f9f62efa23e27ec76.png)
[数据可视化] 图表设计原则

Why do programming languages have the concept of variable types?
SQL injection base
Is there a way out in the testing industry if it is purely business testing?
随机推荐
12. 处理 JSON
SQL注入基础---order by \ limit \ 宽字节注入
16. File upload
[21-day learning challenge - kernel notes] (5) - devmem read and write register debugging
两个链表的第一个公共节点——LeetCode
91.(cesium之家)cesium火箭发射模拟
SQL injection base
Design and implementation of flower online sales management system
Is there a way out in the testing industry if it is purely business testing?
App regression testing, what are the efficient testing methods?
I caught a 10-year-old Ali test developer, and after talking about it, I made a lot of money...
3. 容器功能
全排列思路详解
iNFTnews | In the Web3 era, users will have data autonomy
如何做专利挖掘,关键是寻找专利点,其实并不太难
力扣每日一题-第52天-387. 字符串中的第一个唯一字符
7. yaml
李彦宏拆墙交朋友,大厂“塑料友情”能否帮百度啃下硬骨头?
[21天学习挑战赛——内核笔记](五)——devmem读写寄存器调试
ADC和DAC记录