当前位置:网站首页>re正則錶達式
re正則錶達式
2022-04-23 17:58:00 【name_qgy】
re正則錶達式
正則錶達式是一個特殊的字符序列,能幫助用戶檢查一個字符串是否與某種模式匹配,從而達成快速檢索或替換某個模式、規則的文本。等同於Word中的查找和替換功能。
import re
text='178,168,123456,9537,123456'
print(re.findall('123456',text))
#Out:
['123456', '123456']
1 認識正則錶達式
| 正則字符 | 描 述 |
|---|---|
| . | 匹配除"\n"之外的任何單個字符。範圍最廣。要匹配包括’\n’在內的任意字符,可使用’[.\n]'模式 |
| \d | 匹配一個數字字符,等價於[0-9] |
| \D | 匹配一個非數字字符,等價於[^0-9] |
| \s | 匹配任意空白字符,包括空格、制錶符、換頁符等,等價於[\f\n\r\t\v] |
| \S | 匹配非空白字符,等價於[^\f\n\r\t\v] |
| \w | 匹配包括下劃線的任意單詞數字字符,等價於[A-Za-z0-9_] |
| \W | 匹配任意非單詞、數字、下劃線字符,等價於[^A-Za-z0-9_] |
| 正則字符 | 描 述 |
|---|---|
| [Pp]ython | 匹配Python或python |
| rub[ye] | 匹配ruby或rube |
| [aeiou] | 匹配中括號內的任意一個字母 |
| [0-9] | 匹配任意數字,等價於[0123456789] |
| [a-z] | 匹配任意小寫字母 |
| [A-Z] | 匹配任意大寫字母 |
| [a-zA-Z0-9] | 匹配任意字母及數字 |
| [^aeiou] | 匹配除aeiou字母之外的所有字符 |
| [^0-9] | 匹配除數字之外的所有字符 |
import re
text='身高:180,體重:130,學號:123456,密碼:9537'
print(re.findall(r'\d',text))
print(re.findall(r'\S',text))
print(re.findall(r'\w',text))
print(re.findall(r'[1-5]',text))
print(re.findall(r'[高重]',text))
#Out:
['1', '7', '8', '1', '6', '8', '1', '2', '3', '4', '5', '6', '9', '5', '3', '7']
['身', '高', ':', '1', '7', '8', ',', '體', '重', ':', '1', '6', '8', ',', '學', '號', ':', '1', '2', '3', '4', '5', '6', ',', '密', '碼', ':', '9', '5', '3', '7']
['身', '高', '1', '7', '8', '體', '重', '1', '6', '8', '學', '號', '1', '2', '3', '4', '5', '6', '密', '碼', '9', '5', '3', '7']
['1', '1', '1', '2', '3', '4', '5', '5', '3']
['高', '重']
| 正則字符 | 描 述 |
|---|---|
| * | 0或多個 |
| + | 1或多個 |
| ? | 0或1個 |
| {2} | 2個 |
| {2,5} | 2-5個 |
| {2,} | 至少2個 |
| {,5} | 至多5個 |
text = "my telephone number is 15951817010,and my hometown's telephone \
number is 13863417300,my landline number is 0634-5608603."
print(re.findall(r'\d{4}-\d{7}(?#找座機號碼)', text))
#Out:
['0634-5608603']
| 組合的正則範例 | 描 述 |
|---|---|
| \d{6}[a-z]{6} | 兩個子模式拼在一起組成一個大模式,匹配6個數字加6個小寫字母 |
| \d{6}|[a-z]{6} | 用豎線錶示前後兩個模式有一個匹配即可,匹配6個數字或者6個小寫字母 |
| (abc){3} | 用小括號錶示分組,分組後可以以組為單比特應用量詞,匹配abcabcabc |
| \X | 匹配第X個匹配到的組 |
| (?#…) | 注釋 |
###\X
text="aabbcc ddfgkk oaddww aaaaaa ababcc"
print(re.findall(r'(\w{2})(\1)',text))
print(re.findall(r'(\w{2})(\1)(\2)',text))
#Out:
[('aa', 'aa'), ('ab', 'ab')]
[('aa', 'aa', 'aa')]
###(?#...)
text = "my telephone number is 15951817010,and my hometown's telephone \
number is 13863417300,my landline number is 0634-5608603."
print(re.findall(r'\d{4}-\d{7}(?#找座機號碼)', text))
#Out:
['0634-5608603']
| 正則字符 | 描 述 |
|---|---|
| ^ | 匹配字符串的開頭 |
| $ | 匹配字符串的末尾 |
| \A | 匹配字符串開始 |
| \Z | 匹配字符串結束,如果存在換行,就只匹配到換行前的結束字符串 |
| \b | 匹配單詞邊界,也就是單詞和空格間的比特置。例如:er\b 可以匹配never中的er,但不能匹配verb中的er |
| \B | 匹配非單詞邊界。例如:er\B可以匹配verb中的er,但不能匹配never中的er |
| (?=…) | 匹配的內容在…之前 |
| (?!..) | 匹配的內容不在…之前 |
| (?<=…) | 匹配的內容在…之後 |
| (?<!..) | 匹配的內容不在…之後 |
###(?=...)
text="height:180,weight:63,student_num:2020802178,key:hello_world"
print(re.findall(r'\w+(?=:2020802178)',text))
#Out:
['student_num']
###(?<=...)
print(re.findall(r'(?<=key:)\w+',text))
#Out:
['hello_world']
正則錶達式的內容博大精深,可以先掌握基礎的框架,知道有哪些東西,必要時再深入的去探索,我覺得這是學習新知識、了解新事物的比較高效的學習方法。就像是學習一門新的學科,不需要將該學科的經典書目一字不漏地背鍋,僅需掌握核心的內容,在腦海中形成網絡,當需要用到這張網的某一處時再去細究他。
2 re模塊
python的re模塊,包括8個方法:
- re.search():查找符合模式的字符,只返回第一個,返回Match對象
- re.match():和search一樣,但要求必須從字符串開頭匹配,返回Match對象
- re.findall():返回所有匹配的字符串列錶
- re.finditer():返回一個迭代器,其中包含所有的匹配,也就是Match對象
- re.sub():替換匹配的字符串,返回替換完成的文本
- re.subn():替換匹配的字符串,返回替換完成的文本和替換的次數
- re.split():用匹配錶達式的字符串做分隔符分割原字符串
- re.compile():把正則錶達式編譯成一個對象,方便後面使用
以上8個方法按照功能不同可以劃分為4列,分別是查找,替換,分割和編譯。
2.1 查找,有4個方法:search、match、findall、finditer
2.1.1 search - 只返回1個
import re
text = "abc,Abc,aBC,abc"
print(re.search(r'abc',text))
#Out:
<re.Match object; span=(0, 3), match='abc'>
search方法是返回了一個Match對象,且僅返回了一個值,span=(0,3) 的意思是匹配到了第1-3個字符,如何從Match對象中拿到匹配的值呢,需要用到group方法。
import re
text = "abc,Abc,aBC,abc"
m = re.search(r'abc', text)
print(m.group())
#Out:
abc
group方法在不給定參數的情况下返回值是匹配的結果。
如果將匹配的值進行分組,就可以通過group方法傳入第幾組的參數,輸出的結果是第幾組匹配的結果。
text = "name:qgy,score:99;name:myt,score:98"
m = re.search(r'(name):(\w{3})',text)
print(m.group())
print(m.group(1))
print(m.group(2))
print(m.groups())
#Out:
name:qgy
name
qgy
('name', 'qgy')
在此補充一個知識點,查找的這四個方法有三個參數,之前的部分僅用到了前兩個,就以re.search()方法為例,
re.search(pattern,string,flags=0)
第一個參數pattern是指匹配的模式,第二個參數string是指要匹配的字符串,flags是標志比特,用於控制正則錶達式的匹配方式,如:是否區分大小寫、多行匹配等。
text = "aBc,Abc,aBC,abc"
m = re.search(r'abc', text, flags=re.I)
print(m.group())
#Out:
aBc
上方正則中,我想要匹配的是abc,text中不存在abc,匹配的結果是aBc。
也就是說,re.I的作用是不區分大小寫。
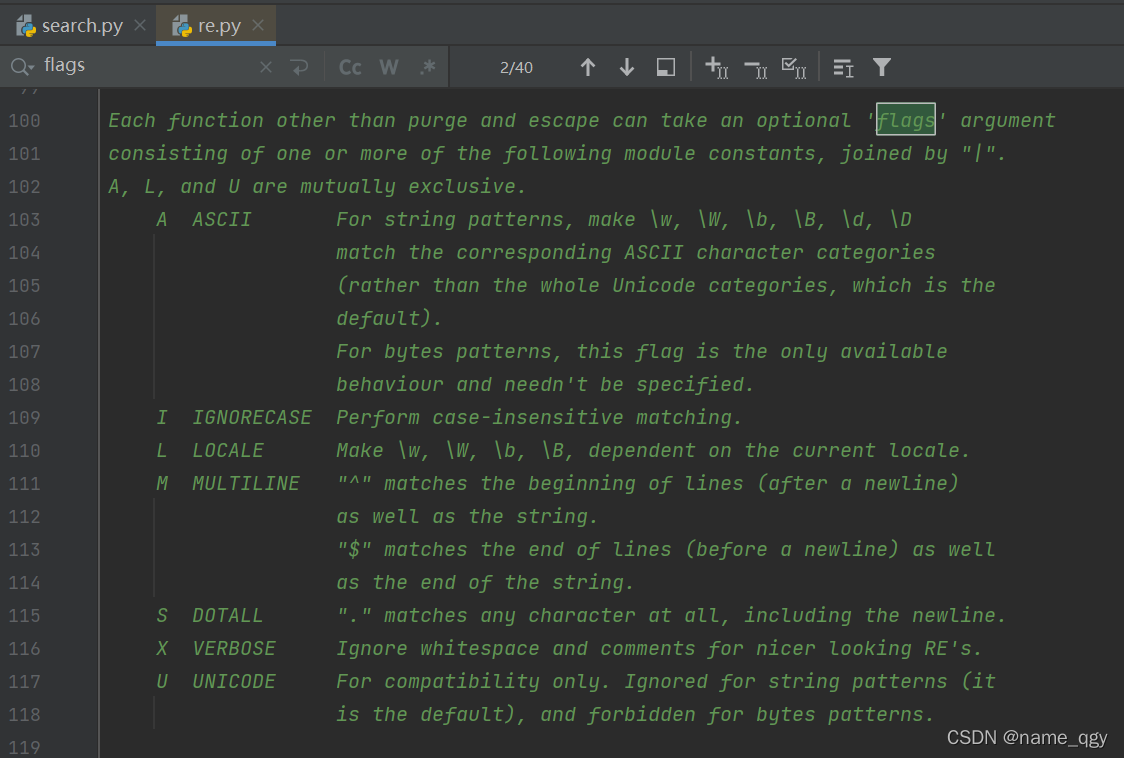
想要查找flags有哪些,可以按住ctrl鍵點一下自己脚本中的re出現的比特置,就會彈出re.py文件,在該文件下按住ctrl+F,彈出查找框,輸入flags就能看到flags有哪些參數了。
2.1.2 match - 也是只返回1個,但是從頭開始匹配
text = "xaBc,Abc,aBC,abc"
m = re.match(r'abc', text, flags=re.I)
n = re.search(r'^abc',text,flags=re.I)
print(m)
print(n)
#Out:
None
None
上方代碼中,我將aBc前添加了x,使用match方法,匹配text開始的字符,如果開始的字符不符合正則錶達式,匹配就會失敗,返回的結果為None。
re.match(r’‘,text) 等價於 re.search(r’^',text)
說實話,match沒啥用,設計這個match給人畫蛇添足的感覺,用search就足够了
2.1.3 findall - 返回所有匹配的字符串
text = "name:qgy,score:99;name:myt,score:98"
m = re.findall(r'(name):(\w{3})',text)
print(m)
#Out:
[('name', 'qgy'), ('name', 'myt')]
findall方法返回一個列錶,匹配時如果有分組的話,列錶中每一個值會用()括起來,不同的組之間用 ‘,’ 分割。
2.1.4 finditer - 返回Match迭代器
text = "name:qgy,score:99;name:myt,score:98"
m = re.finditer(r'(name):(\w{3})',text)
print(m)
for i in m:
print(i)
#Out:
<callable_iterator object at 0x00000224C3D5A460>
<re.Match object; span=(0, 8), match='name:qgy'>
<re.Match object; span=(18, 26), match='name:myt'>
finditer是返回一個迭代器,迭代器是啥我不懂,我估計我也用不著,就暫時不花時間精力去整理了。這一塊就春秋筆法一筆帶過了。
查找功能的4個方法中,search、match和finditer都是返回一個Match對象,可以掌握最基礎的findall和search,找全部就用findall,找一個用search。
2.2 替換,有2個方法:sub、subn
替換的這兩個方法與前面查找的四個方法僅有一處不同,多了個參數,即需要指明想要替換的字符是什麼。
2.2.1 sub - 是英語單詞substitute的英文縮寫
text="abc,aBc,ABc,xyz,opq"
result=re.sub(r'abc','xyz',text,flags=re.I)
print(result)
#Out:
xyz,xyz,xyz,xyz,opq
2.2.2 subn - 替換完成後告訴我有幾個字符被替換掉了
text="abc,aBc,ABc,xyz,opq"
result=re.subn(r'abc','xyz',text,flags=re.I)
print(result)
#Out:
('xyz,xyz,xyz,xyz,opq', 3)
2.3 分割
split方法是將某個字符串按照一定的規則拆分成一些些小字符串。
split有什麼用呢?舉個例子,我有一個序列,我用限制性內切酶對該序列進行酶切,將原來的序列切割成一些小片段,想要知道切割後小片段的序列信息,就可以通過split方法來實現。
MobI = "GATC"
text = "ATCGATCGGTTTAAGATCCTTCG"
result = re.split(MobI, text, flags=re.I)
print(result)
#Out:
['ATC', 'GGTTTAA', 'CTTCG']
2.4 編譯
compile方法是將一個正則錶達式作為一個可以傳達的對象,將該對象傳到別的方法裏也就可以用它,去做search、findall等等。
為什麼要有編譯呢,利用編譯方法的好處是提高效率,如果一個正則錶達式要重複使用成千上百次,每次匹配都要手動輸入一遍豈不是非常麻煩,有了編譯的結果,重複使用時就直接調用了。
re_telephone=re.compile(r'\d{4}-\d{3,8}')
text1="Xiao ming's telephone number is 0634-4854481"
text2="Xiao hone's telephone number is 0531-145488454"
text3="Xiao gang's telephone number is 0452-567188155"
print(re_telephone.search(text1).group())
print(re_telephone.search(text2).group())
print(re_telephone.search(text3).group())
#Out:
0634-4854481
0531-14548845
0452-56718815
版权声明
本文为[name_qgy]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231757533626.html
边栏推荐
- Vite configure proxy proxy to solve cross domain
- Nat commun | current progress and open challenges of applied deep learning in Bioscience
- Thirteen documents in software engineering
- [UDS unified diagnostic service] IV. typical diagnostic service (6) - input / output control unit (0x2F)
- Nat Commun|在生物科学领域应用深度学习的当前进展和开放挑战
- 2022 Jiangxi energy storage technology exhibition, China Battery exhibition, power battery exhibition and fuel cell Exhibition
- Classification of cifar100 data set based on convolutional neural network
- MySQL 中的字符串函数
- Operation of 2022 mobile crane driver national question bank simulation examination platform
- SQL optimization for advanced learning of MySQL [insert, primary key, sort, group, page, count]
猜你喜欢

Compilation principle first set follow set select set prediction analysis table to judge whether the symbol string conforms to the grammar definition (with source code!!!)
C1小笔记【任务训练篇二】
Kubernetes service discovery monitoring endpoints

Comparison between xtask and kotlin coroutine

2022江西光伏展,中国分布式光伏展会,南昌太阳能利用展
C1小笔记【任务训练篇一】

The ultimate experience, the audio and video technology behind the tiktok

Fashion classification case based on keras
Auto. JS custom dialog box

Cloud native Virtualization: building edge computing instances based on kubevirt
随机推荐
MySQL_ 01_ Simple data retrieval
cv_ Solution of mismatch between bridge and opencv
[UDS unified diagnostic service] IV. typical diagnostic service (6) - input / output control unit (0x2F)
Remember using Ali Font Icon Library for the first time
Cloud native Virtualization: building edge computing instances based on kubevirt
C1小笔记【任务训练篇一】
20222 return to the workplace
2022 Shanghai safety officer C certificate operation certificate examination question bank and simulation examination
Listen for click events other than an element
纳米技术+AI赋能蛋白质组学|珞米生命科技完成近千万美元融资
2022 tea artist (primary) examination simulated 100 questions and simulated examination
Halo 开源项目学习(二):实体类与数据表
Gets the time range of the current week
Special effects case collection: mouse planet small tail
Notes on common basic usage of eigen Library
ES6 new method
Logic regression principle and code implementation
Transfer learning of five categories of pictures based on VGg
Nanotechnology + AI enabled proteomics | Luomi life technology completed nearly ten million US dollars of financing
Oil monkey website address