当前位置:网站首页>Interpretation of the paper: GAN and detection network multi-task/SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network
Interpretation of the paper: GAN and detection network multi-task/SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network
2022-08-11 06:33:00 【pontoon】
1. Bottleneck:
Small-scale targets are limited by the lack of sufficient target feature information, making it difficult to distinguish them from the background, and small-scale targets are generally low-resolution and blurry, so the detection performance is average
CNN-based target detection algorithms all need to use downsampling operations, resulting in small-scale targets not only losing spatial location information, but also the original few target features are almost submerged by the features on the background
2. Contribution to this article:
A novel unified end-to-end multi-task generative adversarial network (MTGAN) for small object detection is proposed, which can be combined with any existing detectors
In MTGAN, a generator network generates super-resolution images, and a multi-task discriminator network is introduced to simultaneously distinguish real high-resolution images from fake images, predict object categories, and refine bounding boxes.More importantly, the classification and regression losses are back-propagated to further guide the generator network to produce super-resolution images for easier classification and better localization.
Finally, the effectiveness of MTGAN for object detection is demonstrated, where the detection performance is much improved over several state-of-the-art detectors (mainly for small objects)
3. Solution:
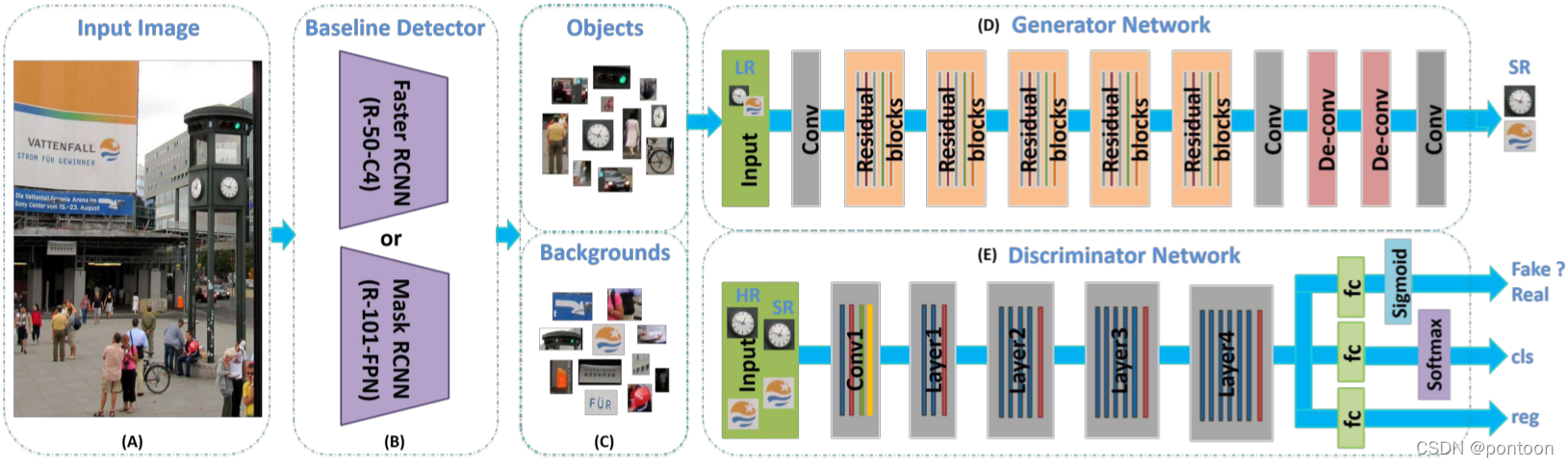
(A) Overall network input image
(B) The detector separates the target from the background in the input image (cropping, which is equivalent to extracting ROI from RPN), and then uses it for training the generator and discriminator, or extracting ROI during testing
(C) Positive and negative samples generated by the detector
(D) The generator is a super-resolution network that generates super-resolution from low-resolution images
(E) The discriminator is a multi-task network, whose input comes from the super-resolution image generated by the generator, judges the authenticity of the image, image classification, and image regression (equivalent to adding classification and regression to the original discriminatorbranch, introducing detection tasks)
The discriminator is a multi-task network whose gradients are passed back to the generator, so that the images generated by the generator are generated in the following direction (high resolution, easy for classification and regression)
Three branches of the discriminator (the true and false branch of the detection image is finally output by sigmoid, the classification branch is finally output by softmax, and the regression branch is finally output as (x,y,w,h))
Generator and discriminator network structure: (x5 represents a residual block with five layers of convolution)

Overall design objective function: (this is only an approximate function, which will be split later)
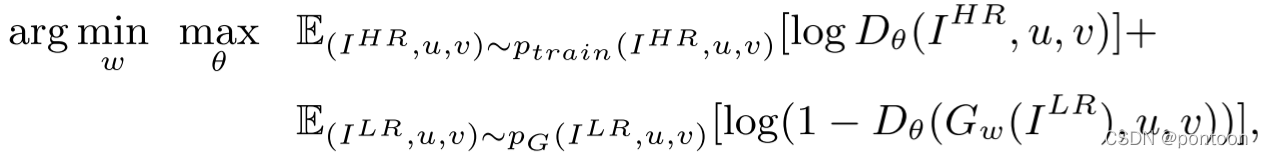
I^{LR} means low resolution image
I^{HR} means high resolution image
u represents the category label value
v represents the detection box regression label value
θ represents the discriminator network parameters
w means generator parameter
Objective function details:
(1) MSE-LOSS is minimized to make it close to the real image, but the disadvantage is that it is more blurry
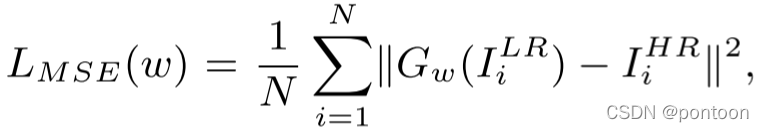
(2) Adversarial Loss adds adversarial loss to improve detail reconstruction ability and fool the discriminator
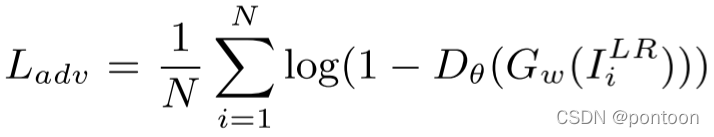
(3) Classification Loss Classification Loss
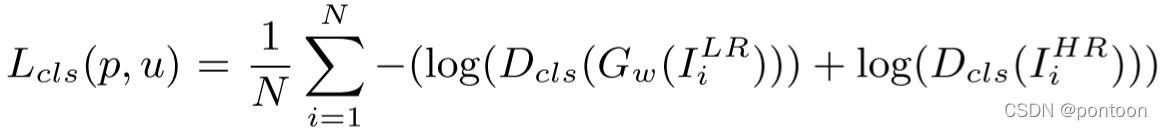
and represent the probability that the generated image belongs to category u, and the probability that the real image is input to category u.
(4) Regression Loss regression loss, SR represents the generated super-score, and when ui=0, there is no regression value for the background class
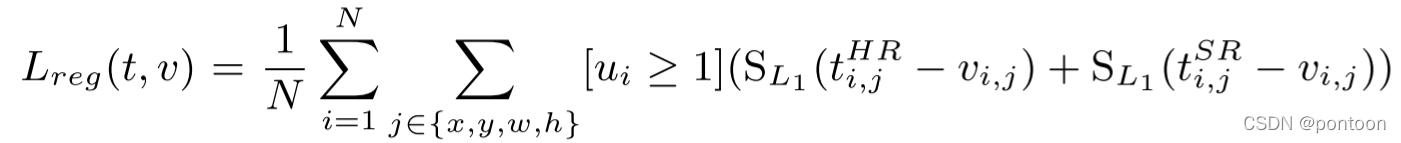
smmoth L1 loss
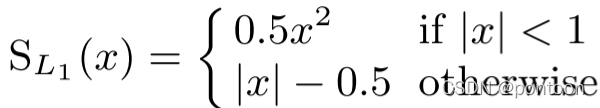
Overall objective function: where α, β and γ are the weights to weigh different terms (α = 0.001, β = γ = 0.01)
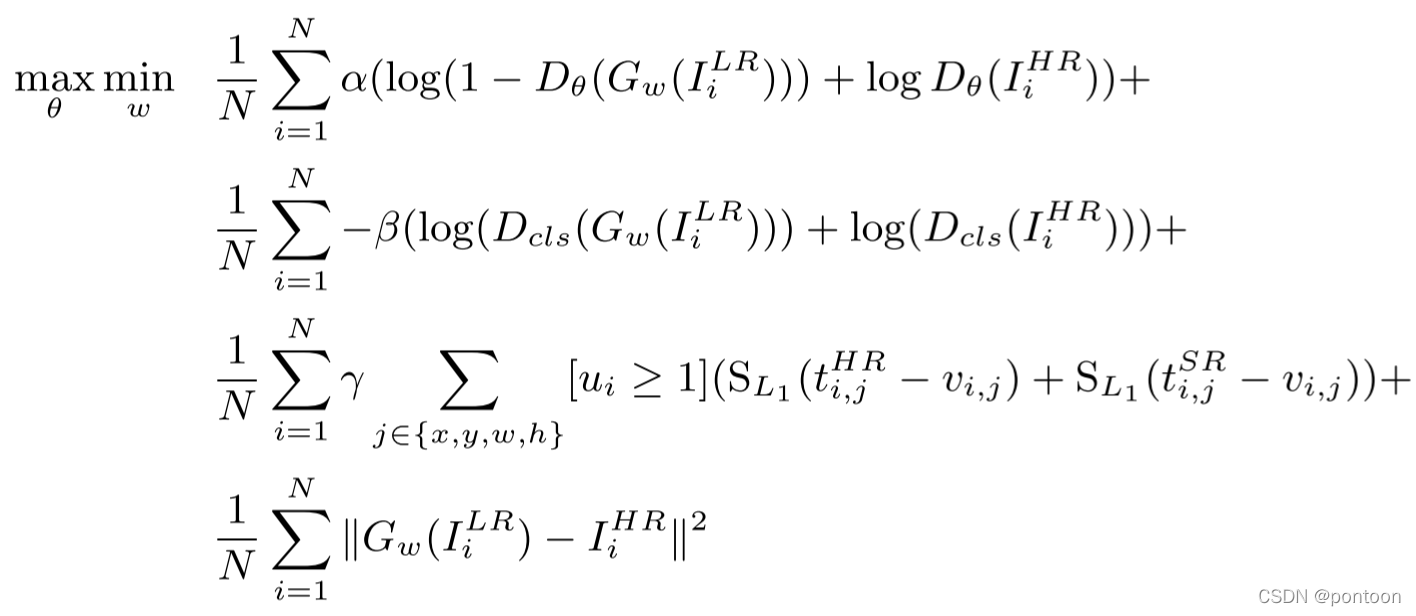
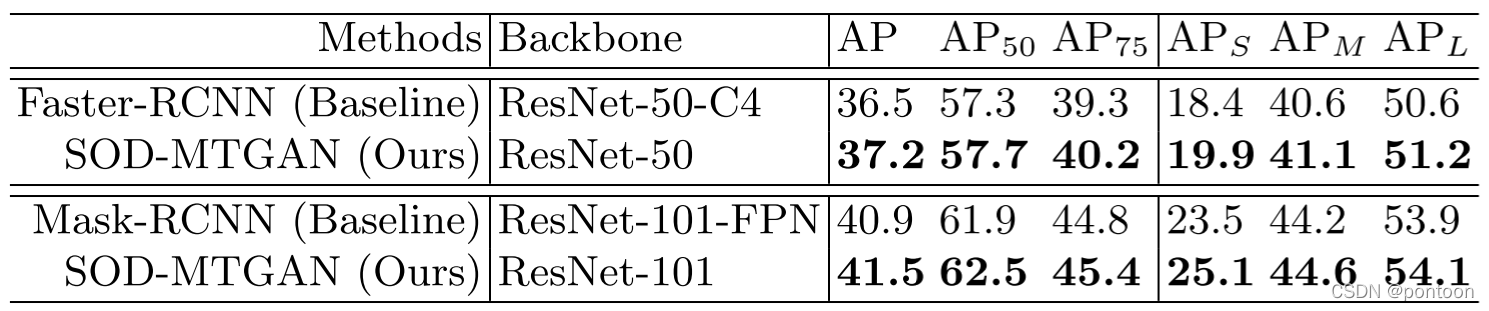
4. Experiment:
Experiment on COCO dataset
The initial GAN is not stable. In order to avoid local optima, an MSE-based SR network is first trained to initialize the generator network.
COCO minival subset
Column 1: Real low-res image
Second column: real high-resolution images
Column 3: Generate high-resolution images

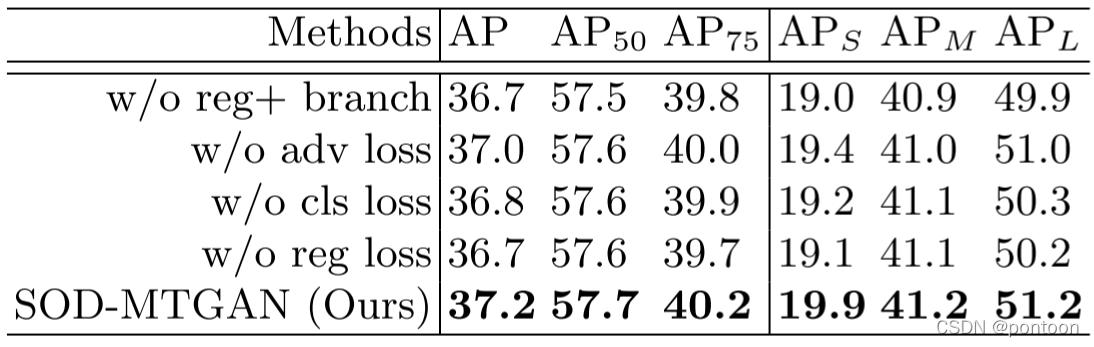
Ablation experiment:
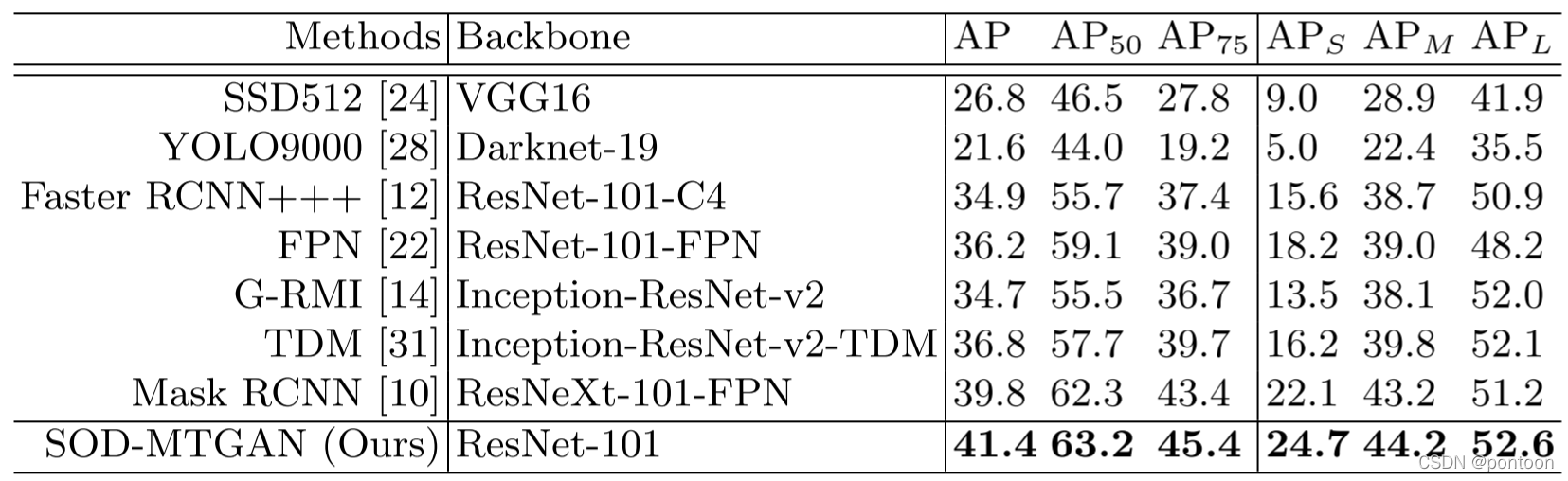
Comparison of SOTA detection models:
Red: model prediction
Green: true tag

The author concludes that there is still a lot of room for improvement...
边栏推荐
- 10 个超好用的 DataGrip 快捷键,快加入收藏! | 实用技巧
- STM32学习笔记(白话文理解版)—按键控制
- 使用adb命令管理应用
- JNI入门
- Thesis unscramble TransFG: A Transformer Architecture for Fine - grained Recognition
- 论文解读:GAN与检测网络多任务/SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network
- Error: Flash Download failed - “Cortex-M4“-STM32F4
- ActiveReports报表分类之页面报表
- STM32学习总结(一)——时钟RCC
- OpenMLDB v0.5.0 发布 | 性能、成本、灵活性再攀高峰
猜你喜欢
STM32 基于固件库的工程模板的建立
![[Meetup]OpenMLDBxDolphinScheduler 链接特征工程与调度环节,打造端到端MLOps工作流](/img/d8/a367c26b51d9dbaf53bf4fe2a13917.png)
[Meetup]OpenMLDBxDolphinScheduler 链接特征工程与调度环节,打造端到端MLOps工作流
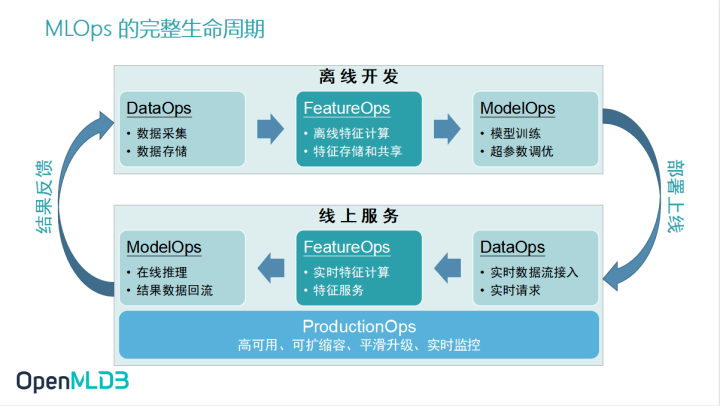
构建面向特征工程的数据生态 ——拥抱开源生态,OpenMLDB全面打通MLOps生态工具链
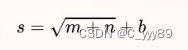
Mei cole studios - deep learning second BP neural network
活动预告 | 4月23日,多场OpenMLDB精彩分享来袭,不负周末好时光
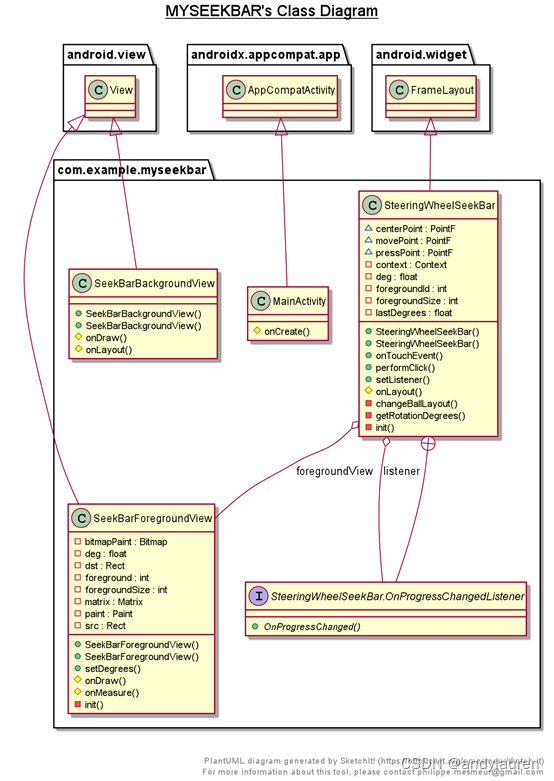
自定义形状seekbar学习--方向盘view
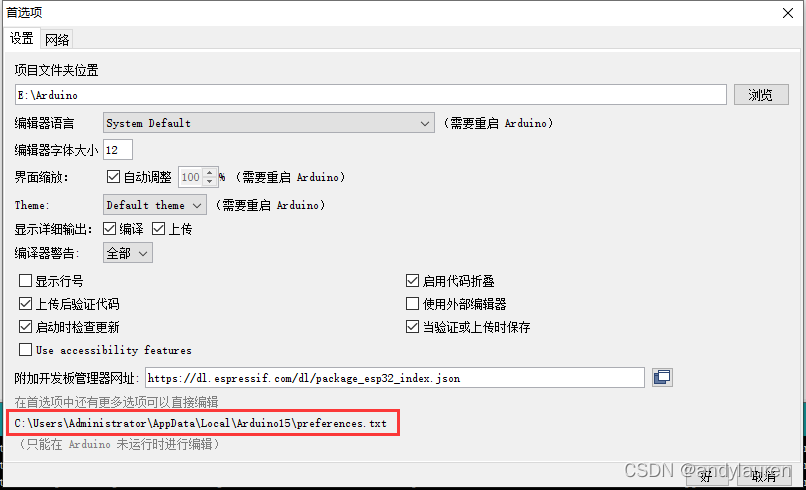
arduino的esp32环境搭建(不需要翻墙,不需要离线安装)
Diagnostic Log and Trace——dlt的编译和安装
vscode插件开发——懒人专用markdown插件开发
使用adb命令管理应用
随机推荐
CMT2380F32模块开发10-高级定时器例程
构建面向特征工程的数据生态 ——拥抱开源生态,OpenMLDB全面打通MLOps生态工具链
Argparse模块 学习
CMT2380F32模块开发9-可编程计数阵列 PCA例程
The latest safety helmet wearing recognition system in 2022
Maykel Studio - Django Web Application Framework + MySQL Database Third Training
华为IOT平台温度过高时自动关闭设备场景试用
IIC 和 SPI
自定义形状seekbar学习--方向盘view
STM32学习笔记(白话文理解版)—外部IO中断实验
vscode插件开发——懒人专用markdown插件开发
Visual studio2019 configuration uses pthread
SWOT分析法
USB URB
Mei cole studios - deep learning second BP neural network
栈stack
vscode插件开发——代码提示、代码补全、代码分析(续)
蓝牙技术-简介
使用ActiveReports制作第一张报表
10 个超好用的 DataGrip 快捷键,快加入收藏! | 实用技巧