当前位置:网站首页>SiamFC:用于目标跟踪的全卷积孪生网络 fully-convolutional siamese networks for object tracking
SiamFC:用于目标跟踪的全卷积孪生网络 fully-convolutional siamese networks for object tracking
2022-08-09 07:09:00 【代码的路】
SiamFC网络
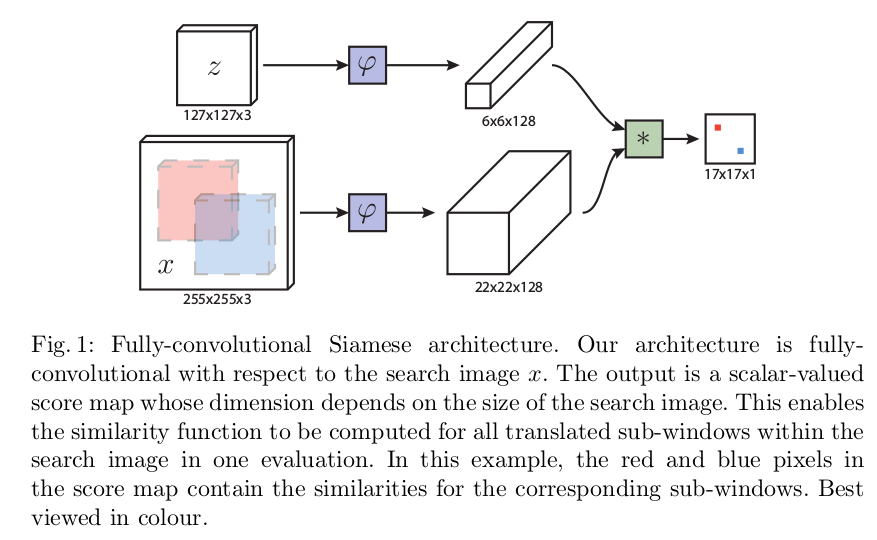
图中z代表的是模板图像,算法中使用的是第一帧的ground truth;x代表的是search region,代表在后面的待跟踪帧中的候选框搜索区域;ϕ代表的是一种特征映射操作,将原始图像映射到特定的特征空间,文中采用的是CNN中的卷积层和pooling层;6×6×128代表z经过ϕ后得到的特征,是一个128通道6×6大小feature,同理,22×22×128是x经过ϕ后的特征;后面的×代表卷积操作,让22×22×128的feature被6×6×128的卷积核卷积,得到一个17×17的score map,代表着搜索区域中各个位置与模板相似度值。
算法本身是比较搜索区域与目标模板的相似度,最后得到搜索去区域的score map。其实从原理上来说,这种方法和相关性滤波的方法很相似。其在搜索区域中逐点的目标模板进行匹配,将这种逐点平移匹配计算相似度的方法看成是一种卷积,然后在卷积结果中找到相似度值最大的点,作为新的目标的中心。
上图所画的ϕ其实是CNN中的一部分,并且两个ϕ的网络结构是一样的,这是一种典型的孪生神经网络,并且在整个模型中只有conv层和pooling层,因此这也是一种典型的全卷积(fully-convolutional)神经网络。
在训练模型的时肯定需要损失函数,并通过最小化损失函数来获取最优模型。本文算法为了构造有效的损失函数,对搜索区域的位置点进行了正负样本的区分,即目标一定范围内的点作为正样本,这个范围外的点作为负样本,例如图1中最右侧生成的score map中,红色点即正样本,蓝色点为负样本,他们都对应于search region中的红色矩形区域和蓝色矩形区域。文章采用的是logistic loss,具体的损失函数形式如下:
对于score map中了每个点的损失:
![]()
其中v是score map中每个点真实值,y∈{+1,−1}是这个点所对应的标签。
上面的是score map中每个点的loss值,而对于score map整体的loss,则采用的是全部点的loss的均值。即:
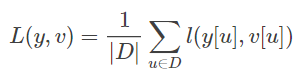
这里的u∈D代表score map中的位置。
整个网络结构类似与AlexNet,但是没有最后的全连接层,只有前面的卷积层和pooling层。

整个网络结构入上表,其中pooling层采用的是max-pooling,每个卷积层后面都有一个ReLU非线性激活层,但是第五层没有。另外,在训练的时候,每个ReLU层前都使用了batch normalization(批规范化是深度学习中经常见到的一种训练方法,指在采用梯度下降法训练DNN时,对网络层中每个mini-batch的数据进行归一化,使其均值变为0,方差变为1,其主要作用是缓解DNN训练中的梯度消失/爆炸现象,加快模型的训练速度),用于降低过拟合的风险。
AlexNet:
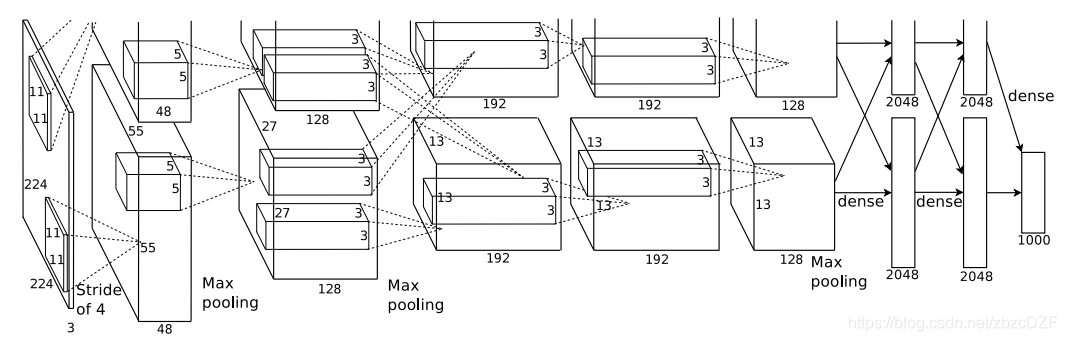
AlexNet为8层结构,其中前5层为卷积层,后面3层为全连接层;学习参数有6千万个,神经元有650,000个。AlexNet在两个GPU上运行;AlexNet在第2,4,5层均是前一层自己GPU内连接,第3层是与前面两层全连接,全连接是2个GPU全连接;
RPN层第1,2个卷积层后;Max pooling层在RPN层以及第5个卷积层后。ReLU在每个卷积层以及全连接层后。
卷积核大小数量:
- conv1:96 11×11×3(个数/长/宽/深度)
- conv2:256 5×5×48
- conv3:384 3×3×256
- conv4: 384 3×3×192
- conv5: 256 3×3×192
ReLU、双GPU运算:提高训练速度。(应用于所有卷积层和全连接层)
重叠pool池化层:提高精度,不容易产生过度拟合。(应用在第一层,第二层,第五层后面)
局部响应归一化层(LRN):提高精度。(应用在第一层和第二层后面)
Dropout:减少过度拟合。(应用在前两个全连接层)
微调(fine-tune)
看到别人一个很好的模型,虽然针对的具体问题不一样,但是也想试试看,看能不能得到很好的效果,而且自己的数据也不多,怎么办?没关系,把别人现成的训练好了的模型拿过来,换成自己的数据,调整一下参数,在训练一遍,这就是微调(fine-tune)。
冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层),训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。从某意义上来说,微调应该是迁移学习中的一部分。
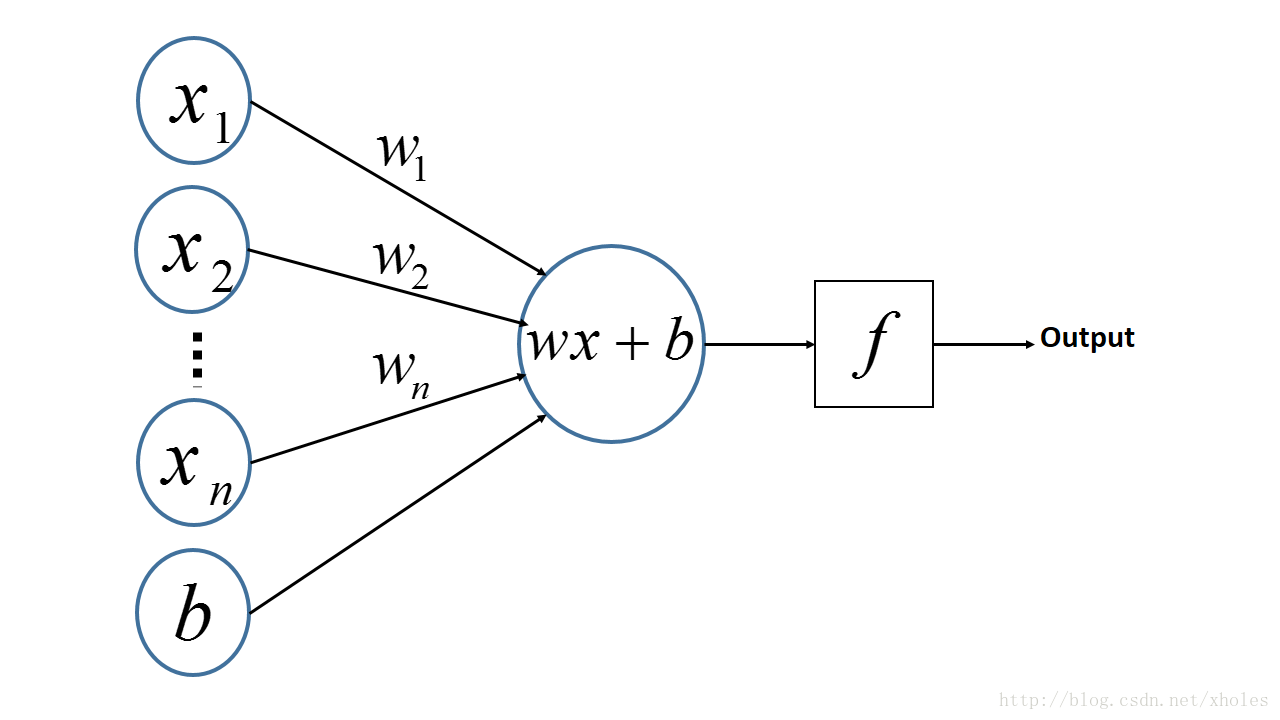
感知机:PLA
多层感知机是由感知机推广而来,感知机学习算法(PLA: Perceptron Learning Algorithm)用神经元的结构进行描述的话就是一个单独的。
感知机的神经网络表示如下:
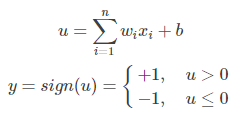
多层感知机:MLP
多层感知机的一个重要特点就是多层,我们将第一层称之为输入层,最后一层称之有输出层,中间的层称之为隐层。MLP并没有规定隐层的数量,因此可以根据各自的需求选择合适的隐层层数。且对于输出层神经元的个数也没有限制。
MLP神经网络结构模型如下,本文中只涉及了一个隐层,输入只有三个变量[x1,x2,x3]和一个偏置量b,输出层有三个神经元。相比于感知机算法中的神经元模型对其进行了集成。
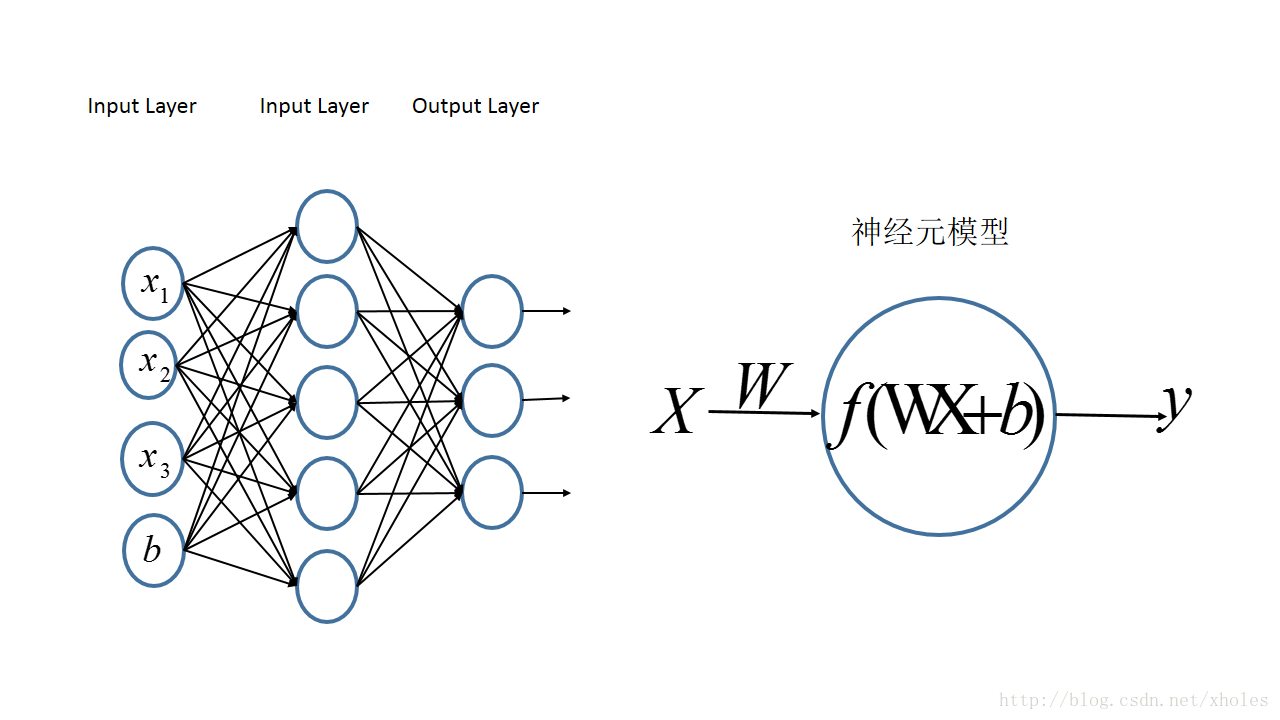
ReLU函数:
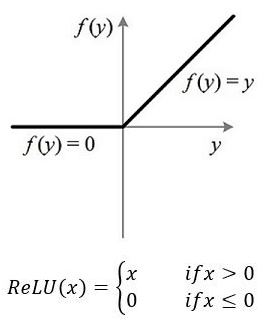
sigmod函数:
学习更多编程知识,请关注我的公众号:

边栏推荐
- 力扣 636. 函数的独占时间
- 基于布朗运动的文本生成方法-LANGUAGE MODELING VIA STOCHASTIC PROCESSES
- Variable used in lambda expression should be final or effectively final报错解决方案
- unity第一课
- The division principle summary within the collection
- The AD in the library of library file suffix. Intlib. Schlib. Pcblib difference
- stm32定时器之简单封装
- The Integer thread safe
- vim 程序编辑器的基本操作(积累)
- 什么是分布式事务
猜你喜欢
错误:为 repo ‘oracle_linux_repo‘ 下载元数据失败 : Cannot download repomd.xml: Cannot download repodata/repomd.
数据库索引原理
Distributed id generator implementation

web自动化测试有哪些工具和框架?
postgresql窗口功能
【修电脑】系统重装但IP不变后VScode Remote SSH连接失败解决

Important news丨.NET Core 3.1 will end support on December 13 this year
Mysql实操
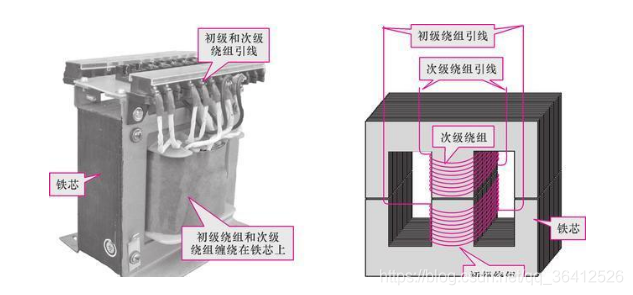
The working principle of the transformer (illustration, schematic explanation, understand at a glance)
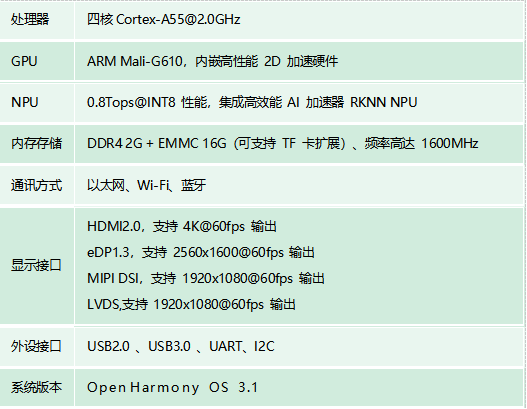
RK3568商显版开源鸿蒙板卡产品解决方案
随机推荐
半导体新能源智能装备整机软件系统方案设计
常见的分布式事务解决方案
分布式事务的应用场景
codeforces Valera and Elections (这思维题是做不明白了)
rsync:recv_generator: mkdir (in backup) failed:Permission denied (13) |failed to set times on '.'
Thread Pool Summary
高德地图JS - 已知经纬度来获取街道、城市、详细地址等信息
TCP段重组PDU
浅识微服务架构
imageio读取.exr报错 ValueError: Could not find a backend to open `xxx.exr‘ with iomode `r`
买口罩(0-1背包)
基于布朗运动的文本生成方法-LANGUAGE MODELING VIA STOCHASTIC PROCESSES
什么是分布式事务
longest substring without repeating characters
Lottie系列三 :原理分析
tianqf的解题思路
eyb:Redis学习(2)
【Template】Tree Chain Segmentation P3384
高项 04 项目变更管理
RK3568商显版开源鸿蒙板卡产品解决方案