当前位置:网站首页>MySQL select count(*) count is very slow, is there any optimization solution?
MySQL select count(*) count is very slow, is there any optimization solution?
2022-08-11 09:02:00 【One Light Architecture】
携手创作,共同成长!这是我参与「掘金日新计划 · 8 月更文挑战」的第13天,点击查看活动详情
在日常开发工作中,I often need to statistics of the total number of scene,比如:Statistical order total、Statistical subscribers, etc.一般我们会使用MySQL 的count函数进行统计,But as data volumes increase gradually,Statistics is becoming more and more time consuming,Finally slow query condition,这究竟是什么原因呢?This article take you to learn.
1. MyISAMThe storage engine count why so fast?
We always have a illusion,就是感觉MyISAM引擎的countCount thanInnoDB引擎更快,Actually this is not an illusion.
MyISAMEngine total number of rows of tables separately record on the disk,When the query can return directly,Don't need to accumulate statistics.
但是当SQL查询中有where条件的时候,Can't again the total number of rows of a table,Still need to be good to accumulate statistics,Query performance also likeInnoDB相差无几了.
为什么MyISAMEngine can record the total number of,InnoDBThe engine cannot?
因为MyISAM引擎不支持事务,只有表锁,So the record number is accurate.
而InnoDBEngine supports transactions, and row locks,The condition of the concurrent modification.As a result of the transaction isolation, again,会出现不可重复读和幻读,Record the total number of rows cannot guarantee is accurate.
2. Can manually implement statistical number
既然InnoDBThe engine didn't help us to record the total number of rows,We can record the total number of rows manually,比如使用Redis.
其实也是不行的,使用Redis记录总行数,至少有下面3个问题:
- Unable to realize the transaction isolation between
- 更新丢失,因为i++不是原子操作,当然可以使用Lua脚本实现原子操作,更复杂.
- RedisIs a relational database cache,Cannot be used as a relational database persistence,一般需要设置过期时间.

According to above,虽然Redis计数加1Operating on the transaction,But not controlled by the transaction,在事务没有提交前,Other queries are still read about the latest total number,This is the situation of the dirty read.
3. InnoDBEngine can realize fast count
有一种办法,Can be a rough estimate table the total number of,就是使用MySQL命令:
show table status like 'user';
复制代码
Real number is100万行,预估有99万多行,Error in the acceptable range.
部分场景适用,As a rough estimate total site users.
4. Four ways of counting performance difference
Common statistics of the number of the headquarters of means has the following four:
count(*) 、 count(常量) 、 count(id) 、 count(字段)
InnoDB引擎对countCount optimized,Can choose statistical data volume smaller than the cluster index.
Such as user has three indexes in the table,分别是主键索引、name索引和age索引,When using execution plan view count which indexes used to?
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) DEFAULT NULL COMMENT '姓名',
`age` tinyint NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB COMMENT='用户表';
复制代码explain select count(*) from user;
复制代码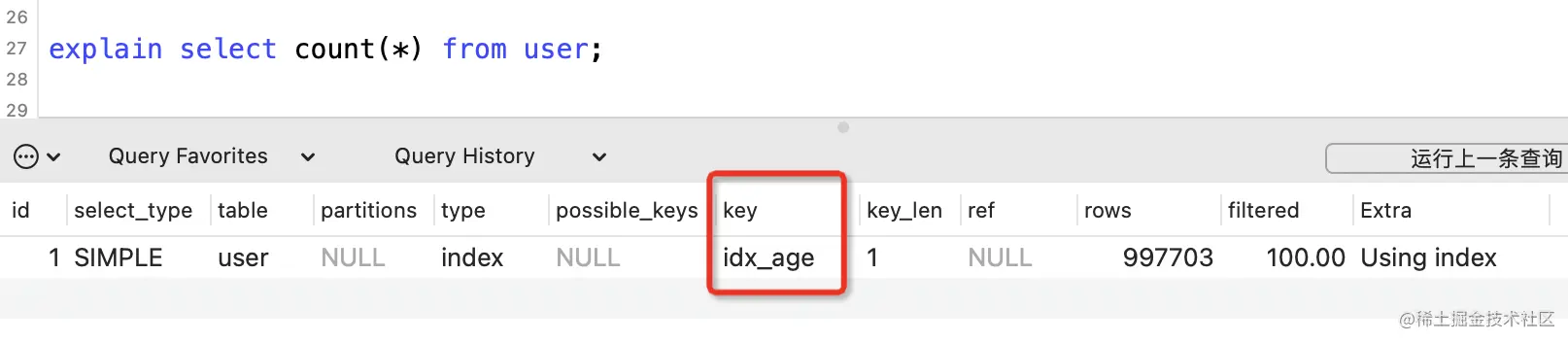
Use the data volume smallerage索引.
count(*) 、 count(常量) Is total number of direct statistics,效率较高.
而 count(id) Still need to put the data back to theMySQL ServerEnd to accumulate count.
最后 count(字段)Need to screen fornull字段,效率最差.
Four counts of query performance from high to low,依次是:
count(*) ≈ count(常量) > count(id) > count(字段)
对于大多数情况,Count results,还是老老实实使用count(*)
所以推荐使用select count(*) ,别跟select * 搞混了,不推荐使用select * 的.
边栏推荐
猜你喜欢
pycharm中绘图,显示不了figure窗口的问题
golang string manipulation

The no-code platform helps Zhongshan Hospital build an "intelligent management system" to realize smart medical care
基于 VIVADO 的 AM 调制解调(3)仿真验证
通过Xshell连接Vagrant创建的虚拟机
Oacle数据库使用问题
nodejs worker_threads的事件监听问题
向日葵安装教程--向日葵远程桌面控制
零基础创作专业wordpress网站12-设置标签栏图标(favicon)

WordpressCMS主题开发02-制作顶部header.php和footer.php
随机推荐
磁盘管理:磁盘结构
Design of Cluster Gateway in Game Server
mindspore 执行模型转换为310的mindir文件显示无LRN算子
pycharm中绘图,显示不了figure窗口的问题
Song of the Cactus - Massive Rapid Expansion (1)
MongoDB 对索引的创建查询修改删除 附代码
[UEFI]EFI_DEVICE_PATH_PROTOCOL 结构体初始化的一个例子
nodejs worker_threads的事件监听问题
研发了 5 年的时序数据库,到底要解决什么问题?
《剑指offer》题解——week3(持续更新)
如何在移动钱包中搭建一个小程序应用商店
Kotlin算法入门求自由落体
mindspore中MindDataset读取mindrecord文件问题
向日葵安装教程--向日葵远程桌面控制
SDUT 2877:angry_birds_again_and_again
tensorflow 基础操作1(tensor 基本属性 , 维度变换,数学运算)
js将table生成excel文件并去除表格中的多余tr(js去除表格中空的tr标签)
Kotlin算法入门计算质因数
【系统梳理】当我们在说服务治理的时候,其实我们说的是什么?
专题讲座8 字符串(一) 学习心得