当前位置:网站首页>Redis缓存设计
Redis缓存设计
2022-08-09 08:48:00 【Java大厂面试君】
缓存优点
加速读写:缓存通常是全内存的(例如Redis、Memcache),而存储层通常读写性能不够强悍,通过缓存的使用可以有效地加速读写,优化用户体验;
降低后端负载:帮助后端减少访问量和复杂计算(比如很复杂的sql逻辑),很大程度上降低了后端的负载。
缓存缺点
数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性,时间窗口跟更新策略有关;
代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本;
运维成本:比如Redis Cluster,加入后无形中增加了运维成本。
P.S. 分析缓存优缺点,不难看出缓存主要用于两种场景,一是开销大的复杂计算,比如很复杂的sql计算等;二是加速请求响应。
缓存更新策略
缓存中的数据一般是有生命周期的,需要在指定时间后被删除或更新,从而来保证缓存空间在一个可控的范围内,但缓存中的数据会和数据源的真实数据有一段时间窗口的不一致,需要利用某些策略进行更新。常见的有三种缓存的更新策略:
LRU/LFU/FIFO算法剔除
剔除算法一般用于缓存使用量超过预设最大值,如何对现有的数据进行剔除。Redis使用maxmemory-policy作为内存最大值对数据进行剔除。清理哪些数据交由算法决定,开发人员只能决定选择何种算法,所以数据的一致性最差,但也意味着维护成本低,不需要自己设计算法,只要选择适合的算法即可。
超时剔除
超时剔除一般用于给缓存设置过期时间,让其过期后自动删除。Redis使用expire来实现。不过一段时间内窗口内(取决于过期时间长短)存在一致性问题,即缓存数据和真实数据源不一致。该策略的优点在于维护成本较低,只需设置expire过期时间即可,当然也要接受其不一致的缺点。
主动更新
这种一般用于应用对于数据一致性要求很高,需要在真实数据更新后,立即更新缓存数据。比如可以利用消息系统或其他方式通知缓存更新。其一致性是三种策略中最高的,维护成本也是最高的。
P.S.低一致性业务建议配置最大内存和淘汰策略;高一致性业务建议结合使用超时剔除和主动更新
穿透优化
缓存穿透是指查询一个不存在的数据,存储层和缓冲层都不会命中,通常用于容错考虑,如果存储层查不到数据则不写入缓冲层。如下图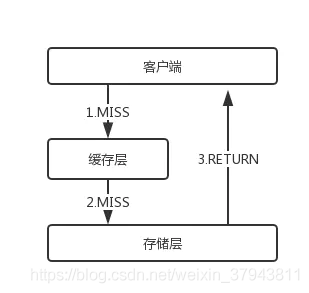
缓存穿透将导致不存在的数据每次请求都要都存储层去查询,失去了缓存保护后端存储的意义。
缓存穿透问题可能会使后端存储负载加大,并且由于很多后端存储不具备高并发性,严重的会导致后端存储宕掉。可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层命中,说明可能发生了缓存穿透。
缓存穿透基本原因有两个,一是自身业务代码或数据出现问题;二是恶意攻击或爬虫。
目前解决方案有两种,一是缓存空对象,二是布隆过滤器拦截。
缓存空对象
缓存穿透过程中,当存储层不命中后,仍将空对象保留到缓存层中,之后再访问这个数据将会从缓存中获取,这样就可以保护后端数据源。
这种方案有两个问题,一是空对象做了缓存,意味着缓存层中存了更多的键,需要分配更多的内存空间。可以通过对这类数据设置一个较短的过期时间,让其自动剔除,释放内存空间。二是缓存层和存储层会有一段时间窗口的不一致,可以利用消息系统或其他方式消除掉缓存层中的空对象。
布隆过滤器拦截
在访问缓存层和存储层之前,将存在的key用布隆过滤器(BloomFilter)提前保存,做一层拦截。
举个例子,一个推荐系统有1亿个id,一定时间算法会根据用户之前历史行为计算出推荐数据,并将其存入缓存层,但是如果用户没有历史行为,那么就会发生缓存穿透,因为可以将所有推荐数据的用户做成布隆过滤器。过滤器判定是否存在该历史用户,如果不存在,就不让访问存储层,一定程度上保护后端数据源。
无底洞优化
随着业务的发展,需要添加更加庞大的节点,批量操作需要从不同节点上获取,而且键值分布到更多的节点上,网络和性能开销变得更高,即投入越多产出却不一定越多。无底洞优化也就是在分布式缓存中批量操作的优化。
一般的IO优化方案有:优化命令;减少网络通信次数;降低接入成本。
Redis批量操作获取n个字符串,有三种实现思路:
1.客户端n次get:n次网络+n次get命令,具体方案有串行命令
2.客户端1次pipeline get:1次网络+n次get命令,具体方案有串行 IO,并行IO
3.客户端1次mget:1次网络+1次mget命令,具体方案有hash_tag实现
雪崩优化
由于缓存层承载着大量请求,有效地保护了存储层,但由于某种原因缓存层挂了,所有请求都直接达到存储层,造成存储层出现级联宕机,这就是缓存雪崩。
预防和解决缓存雪崩有三种思路:
1.保证缓存层服务高可用性。这样个别节点、个别机器或者是机房宕机都能继续提供服务。
2.依赖隔离组件为后端限流并降级。简单来说,就是隔离和降级。
3.提前演练。模拟缓存层宕掉的情况,然后对后端负载等其他情况进行方案演练。
热点key重建优化
前面讲过“缓存+过期时间”的策略可以满足大部分需求,但是如果当前key是很热门的key(热门新闻等),并发量非常大,或者是由于有复杂计算,重建缓存不能短时间内完成。
在缓存失效的瞬间,有大量线程来重建缓存,会造成后端负载加大,严重可能会导致应用崩溃。
简单来分析,需要做到减少重建缓存次数,数据尽可能一致,减少潜在危险。有两种解决方案:
1.互斥锁:只允许一个线程重建缓存,其他线程等待其重建结束,重新重缓存获取数据。思路简单,但如果重建缓存时间过程或出现问题,可能会存在死锁或线程池阻塞的风险。不过这种方案能较好地降低后端存储负载,保持不错的一致性。
2.“永远不过期”:从缓存角度上,不设置过期expire时间,从功能角度上,为每个value设置逻辑过期时间,当发现超过逻辑过期时间,则使用单独线程去构建缓存。这种方案很明显会存在一致性问题,并且代码复杂度会增大,不过热点key导致的问题基本能根除。
边栏推荐
- 小程序调用百度api实现图像识别
- NodeMCU(ESP8266) 接入阿里云物联网平台 踩坑之旅
- 【redis】使用redis实现简单的分布式锁,秒杀并发场景可用
- 零搜索量的关键词,你需要布局吗?
- 大端小端存储区别一看即懂
- The difference between big-endian and little-endian storage is easy to understand at a glance
- Static routing principle and configuration
- ctf misc 图片题知识点
- DeFi 项目中的治理Token
- uniapp编译到小程序后丢失static文件夹问题
猜你喜欢
三次握手,四次挥手
![【MySQL】mysql:解决[Err] 1093 - You can‘t specify target table ‘表名‘ for update in FROM clause问题](/img/76/8e6a3a1c5fdc9bffc0c7c9187a027c.png)
【MySQL】mysql:解决[Err] 1093 - You can‘t specify target table ‘表名‘ for update in FROM clause问题
【redis】使用redis实现简单的分布式锁,秒杀并发场景可用

OpenHarmony Light Smart Product Development Live Notes
消息中间件(MQ)前置知识介绍(必看)

bs4的使用基础学习

leetcode 33. 搜索旋转排序数组 (二分经典题)

requests爬取百度翻译

MySql homework practice questions

Different styles of Flask-restful
随机推荐
UE4 RTS frame selection function implementation
MySQL数据库
web3到底是什么?
QT program generates independent exe program (pit-avoiding version)
管理方向发展
makefile - 学习小结
requests之数据解析Xpath介绍
VoLTE基础自学系列 | IMS的业务触发机制
BUUCTF MISC Writing Notes (1)
引导过程与服务控制
jdbctemplate连接sql server,代码中查出来的数据跟数据库中不一致,如何解决?
canvas 文字垂直居中
内存监控以及优化
【愚公系列】2022年08月 Go教学课程 033-结构体方法重写、方法值、方法表达式
XCTF高校战“疫”网络安全分享赛Misc wp
Literature retrieval operation code
epoll LT和ET 问题总结
scp upload file to remote server
零搜索量的关键词,你需要布局吗?
鸿蒙开发实战一——手表篇