当前位置:网站首页>爬虫基本原理介绍、实现以及问题解决
爬虫基本原理介绍、实现以及问题解决
2022-08-10 19:16:00 【InfoQ】
一、爬虫的意义
1.前言
2.爬虫能做什么
大量自动化公开的数据公开shuju3.爬虫有什么意义

二、爬虫的实现
1.爬虫的基础原理
2.api的获取

graphqlpayload = {"operation_name": "userPublicProfile", #查询数据库请求内容
"query": '''query userPublicProfile($userSlug: String!) {
userProfilePublicProfile(userSlug: $userSlug) {
username
submissionProgress {
acTotal
}
}
}
''',
"variables": '{"userSlug":"查询对象"}'
}
3.爬虫实现
import requests as rq
from urllib.parse import urlencode
headers={ #请求头信息
"Referer":"https://leetcode.cn",
}
payload = {"operation_name": "userPublicProfile", #查询数据库请求内容
"query": '''query userPublicProfile($userSlug: String!) {
userProfilePublicProfile(userSlug: $userSlug) {
username
submissionProgress {
acTotal
}
}
}
''',
"variables": '{"userSlug":"romantic-haibty42"}'
}
res = rq.post("https://leetcode.cn/graphql/"+"?"+ urlencode(payload),headers = headers)
print(res.text)

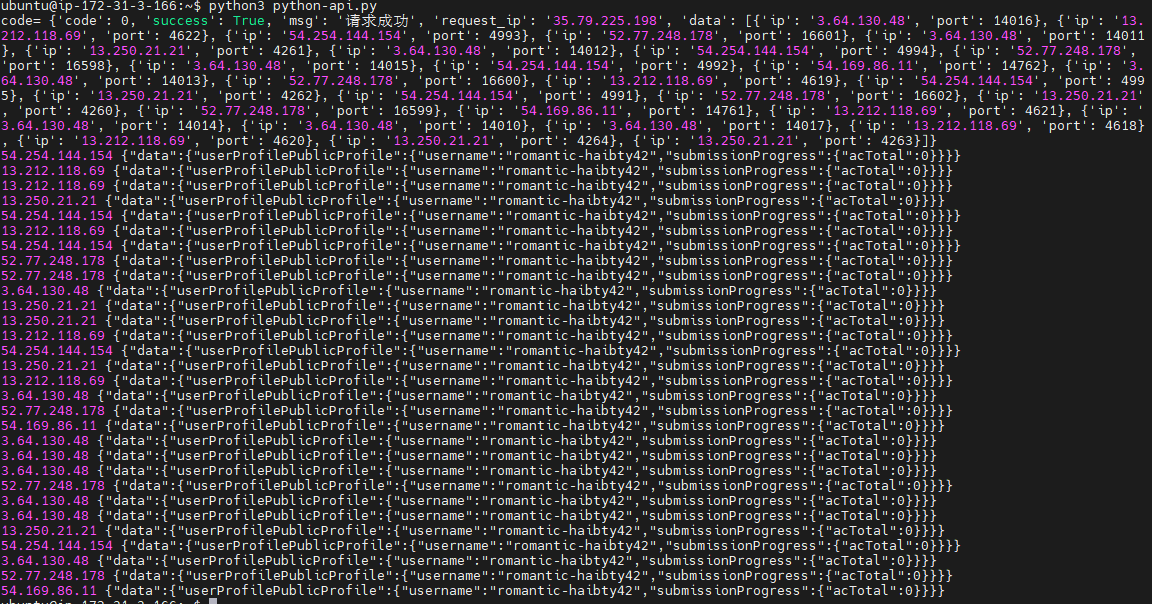
acTotal3三、反爬解决方案
1.反爬的实现方式
2.反爬的解决方法

3.反爬的实现代码

tiqu# coding=utf-8
# !/usr/bin/env python
import json
import threading
import time
import requests as rq
from urllib.parse import urlencode
headers={
"Referer":"https://leetcode.cn",
}
payload = {"operation_name": "userPublicProfile",
"query": '''query userPublicProfile($userSlug: String!) {
userProfilePublicProfile(userSlug: $userSlug) {
username
submissionProgress {
acTotal
}
}
}
''',
"variables": '{"userSlug":"kingley"}'
}
username = "romantic-haibty42"
def int_csrf(proxies,header):
sess= rq.session()
sess.proxies = proxies
sess.head("https://leetcode.cn/graphql/")
header['x-csrftoken'] = sess.cookies["csrftoken"]
testUrl = 'https://api.myip.la/en?json'
# 核心业务
def testPost(host, port):
proxies = {
'http': 'socks5://{}:{}'.format(host, port),
'https': 'socks5://{}:{}'.format(host, port),
}
res = ""
while True:
try:
header = headers
# print(res.status_code)
chaxun = payload
chaxun['variables'] = json.dumps({"userSlug" : f"{username}"})
res = rq.post("https://leetcode.cn/graphql/"+"?"+ urlencode(chaxun),headers = header,proxies=proxies)
print(host,res.text)
except Exception as e:
print(e)
break
class ThreadFactory(threading.Thread):
def __init__(self, host, port):
threading.Thread.__init__(self)
self.host = host
self.port = port
def run(self):
testPost(self.host, self.port)
# 提取代理的链接 json类型的返回值 socks5方式
tiqu = ''
while 1 == 1:
# 每次提取10个,放入线程中
resp = rq.get(url=tiqu, timeout=5)
try:
if resp.status_code == 200:
dataBean = json.loads(resp.text)
else:
print("获取失败")
time.sleep(1)
continue
except ValueError:
print("获取失败")
time.sleep(1)
continue
else:
# 解析json数组
print("code=", dataBean)
code = dataBean["code"]
if code == 0:
threads = []
for proxy in dataBean["data"]:
threads.append(ThreadFactory(proxy["ip"], proxy["port"]))
for t in threads: # 开启线程
t.start()
time.sleep(0.01)
for t in threads: # 阻塞线程
t.join()
# break
break
4.IPIDEA还能做什么


四、总结
边栏推荐
- Public Key Retrieval is not allowed(不允许公钥检索)【解决办法】
- 多线程与高并发(五)—— 源码解析 ReentrantLock
- WCF and TCP message communication practice, c # 】 【 realize group chat function
- Ransom Letter Questions and Answers
- [CNN] Brush SOTA's trick
- 七月券商金工精选
- GBASE 8s 高可用RSS集群搭建
- What is the upstream bandwidth and downstream bandwidth of the server?
- 不止跑路,拯救误操作rm -rf /*的小伙儿
- XML小讲
猜你喜欢
[Go WebSocket] Your first Go WebSocket server: echo server

uni-app 数据上拉加载更多功能
Ransom Letter Questions and Answers

链表应用----约瑟夫问题

Public Key Retrieval is not allowed(不允许公钥检索)【解决办法】
YOLOv3 SPP源码分析
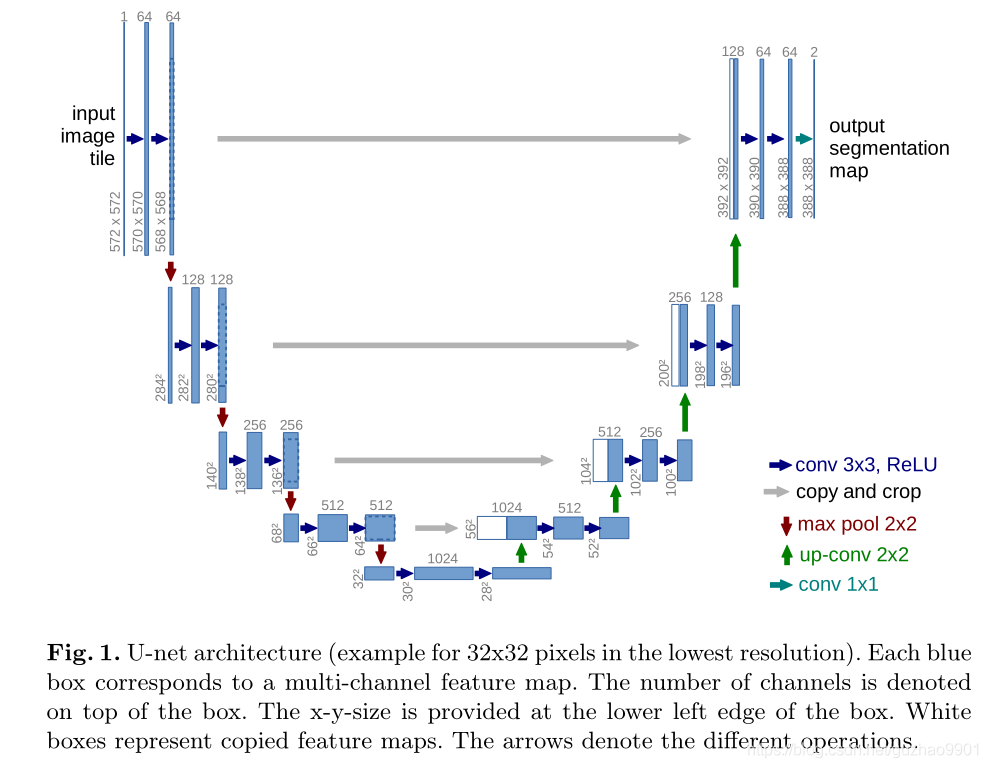
【语义分割】2015-UNet MICCAI
转铁蛋白修饰长春新碱-粉防己碱脂质体|转铁蛋白修饰共载紫杉醇和金雀异黄素脂质体(试剂)
铁蛋白颗粒Tf包载多肽/凝集素/细胞色素C/超氧化物歧化酶/多柔比星(定制服务)
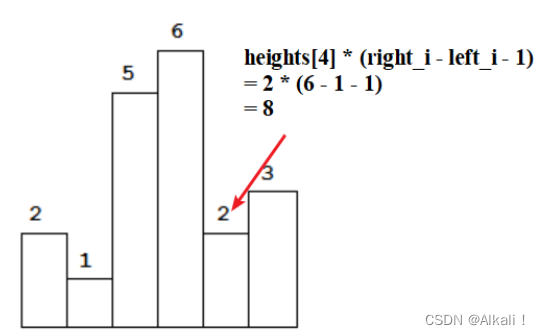
leetcode 84.柱状图中最大的矩形 单调栈应用
![[Go WebSocket] Your first Go WebSocket server: echo server](/img/ac/a5f0a9b9e97470c4c74c5ca84383ab)
随机推荐
MATLAB设计,FPGA实现,联合ISE和Modelsim仿真的FIR滤波器设计
【LeetCode】42、接雨水
【语义分割】2017-PSPNet CVPR
whois information collection & corporate filing information
spark学习笔记(九)——sparkSQL核心编程-DataFrame/DataSet/DF、DS、RDD三者之间的转换关系
Common ports and services
leetcode 547.省份数量 并查集
[Go WebSocket] Your first Go WebSocket server: echo server
(12) findContours function hierarchy explanation
@Autowired注解 --required a single bean, but 2 were found出现的原因以及解决方法
优雅退出在Golang中的实现
whois信息收集&企业备案信息
这7个自动化办公模版 教你玩转表格数据自动化
GBASE 8s 高可用RSS集群搭建
几行深度学习代码设计包含功能位点的候选免疫原、酶活性位点、蛋白结合蛋白、金属配位蛋白
servlet映射路径匹配解析
【SemiDrive源码分析】【MailBox核间通信】51 - DCF_IPCC_Property实现原理分析 及 代码实战
[Teach you how to make a small game] Write a function with only a few lines of native JS to play sound effects, play BGM, and switch BGM
越折腾越好用的 3 款开源 APP
Apple Font Lookup