当前位置:网站首页>零基础SQL教程: 主键、外键和索引 04
零基础SQL教程: 主键、外键和索引 04
2022-08-11 07:05:00 【Add小兵】
主键
在关系数据库中,一张表中的每一行数据被称为一条记录。一条记录就是由多个字段组成的。例如,students表的两行记录:
id class_id name gender score
1 1 小明 M 90
2 1 小红 F 95
每一条记录都包含若干定义好的字段。同一个表的所有记录都有相同的字段定义。
对于关系表,有个很重要的约束,就是任意两条记录不能重复。不能重复不是指两条记录不完全相同,而是指能够通过某个字段唯一区分出不同的记录,这个字段被称为主键。
例如,假设我们把name字段作为主键,那么通过名字小明或小红就能唯一确定一条记录。但是,这么设定,就没法存储同名的同学了,因为插入相同主键的两条记录是不被允许的。
对主键的要求,最关键的一点是:记录一旦插入到表中,主键最好不要再修改,因为主键是用来唯一定位记录的,修改了主键,会造成一系列的影响。
由于主键的作用十分重要,如何选取主键会对业务开发产生重要影响。如果我们以学生的身份证号作为主键,似乎能唯一定位记录。然而,身份证号也是一种业务场景,如果身份证号升位了,或者需要变更,作为主键,不得不修改的时候,就会对业务产生严重影响。
所以,选取主键的一个基本原则是:不使用任何业务相关的字段作为主键。
因此,身份证号、手机号、邮箱地址这些看上去可以唯一的字段,均不可用作主键。
作为主键最好是完全业务无关的字段,我们一般把这个字段命名为id。常见的可作为id字段的类型有:
自增整数类型:数据库会在插入数据时自动为每一条记录分配一个自增整数,这样我们就完全不用担心主键重复,也不用自己预先生成主键;
全局唯一GUID类型:使用一种全局唯一的字符串作为主键,类似8f55d96b-8acc-4636-8cb8-76bf8abc2f57。GUID算法通过网卡MAC地址、时间戳和随机数保证任意计算机在任意时间生成的字符串都是不同的,大部分编程语言都内置了GUID算法,可以自己预算出主键。
对于大部分应用来说,通常自增类型的主键就能满足需求。我们在students表中定义的主键也是BIGINT NOT NULL AUTO_INCREMENT类型。
如果使用INT自增类型,那么当一张表的记录数超过2147483647(约21亿)时,会达到上限而出错。使用BIGINT自增类型则可以最多约922亿亿条记录。
联合主键
关系数据库实际上还允许通过多个字段唯一标识记录,即两个或更多的字段都设置为主键,这种主键被称为联合主键。
对于联合主键,允许一列有重复,只要不是所有主键列都重复即可:
d_num id_type other columns…
1 A …
2 A …
2 B …
如果我们把上述表的id_num和id_type这两列作为联合主键,那么上面的3条记录都是允许的,因为没有两列主键组合起来是相同的。
没有必要的情况下,我们尽量不使用联合主键,因为它给关系表带来了复杂度的上升。
小结
主键是关系表中记录的唯一标识。主键的选取非常重要:主键不要带有业务含义,而应该使用BIGINT自增或者GUID类型。主键也不应该允许NULL。
可以使用多个列作为联合主键,但联合主键并不常用。
外键
当我们用主键唯一标识记录时,我们就可以在students表中确定任意一个学生的记录:
id name other columns…
1 小明 …
2 小红 …
我们还可以在classes表中确定任意一个班级记录:
id name other columns…
1 一班 …
2 二班 …
但是我们如何确定students表的一条记录,例如,id=1的小明,属于哪个班级呢?
由于一个班级可以有多个学生,在关系模型中,这两个表的关系可以称为“一对多”,即一个classes的记录可以对应多个students表的记录。
为了表达这种一对多的关系,我们需要在students表中加入一列class_id,让它的值与classes表的某条记录相对应:
id class_id name other columns…
1 1 小明 …
2 1 小红 …
5 2 小白 …
这样,我们就可以根据class_id这个列直接定位出一个students表的记录应该对应到classes的哪条记录。
例如:
- 小明的
class_id是1,因此,对应的classes表的记录是id=1的一班; - 小红的
class_id是1,因此,对应的classes表的记录是id=1的一班; - 小白的
class_id是2,因此,对应的classes表的记录是id=2的一班; - 在
students表中,通过class_id的字段,可以把数据与另一张表关联起来,这种列称为外键。
外键并不是通过列名实现的,而是通过定义外键约束实现的:
ALTER TABLE students
ADD CONSTRAINT fk_class_id
FOREIGN KEY (class_id)
REFERENCES classes (id);
其中,外键约束的名称fk_class_id可以任意,FOREIGN KEY (class_id)指定了class_id作为外键,REFERENCESclasses (id)指定了这个外键将关联到classes表的id列(即classes表的主键)。
通过定义外键约束,关系数据库可以保证无法插入无效的数据。即如果classes表不存在id=99的记录,students表就无法插入class_id=99的记录。
由于外键约束会降低数据库的性能,大部分互联网应用程序为了追求速度,并不设置外键约束,而是仅靠应用程序自身来保证逻辑的正确性。这种情况下,class_id仅仅是一个普通的列,只是它起到了外键的作用而已。
要删除一个外键约束,也是通过ALTER TABLE实现的:
ALTER TABLE students
DROP FOREIGN KEY fk_class_id;
注意:删除外键约束并没有删除外键这一列。删除列是通过DROP COLUMN …实现的。
多对多
通过一个表的外键关联到另一个表,我们可以定义出一对多关系。有些时候,还需要定义“多对多”关系。例如,一个老师可以对应多个班级,一个班级也可以对应多个老师,因此,班级表和老师表存在多对多关系。
多对多关系实际上是通过两个一对多关系实现的,即通过一个中间表,关联两个一对多关系,就形成了多对多关系:
teachers表:
id name
1 张老师
2 王老师
3 李老师
4 赵老师
classes表:
id name
1 一班
2 二班
中间表teacher_class关联两个一对多关系:
id teacher_id class_id
1 1 1
2 1 2
3 2 1
4 2 2
5 3 1
6 4 2
通过中间表teacher_class可知teachers到classes的关系:
- id=1的张老师对应id=1,2的一班和二班;
- id=2的王老师对应id=1,2的一班和二班;
- id=3的李老师对应id=1的一班;
- id=4的赵老师对应id=2的二班。
同理可知classes到teachers的关系:
id=1的一班对应id=1,2,3的张老师、王老师和李老师;id=2的二班对应id=1,2,4的张老师、王老师和赵老师;
因此,通过中间表,我们就定义了一个“多对多”关系。
一对一
一对一关系是指,一个表的记录对应到另一个表的唯一一个记录。
例如,students表的每个学生可以有自己的联系方式,如果把联系方式存入另一个表contacts,我们就可以得到一个“一对一”关系:
id student_id mobile
1 1 135xxxx6300
2 2 138xxxx2209
3 5 139xxxx8086
有细心的童鞋会问,既然是一对一关系,那为啥不给students表增加一个mobile列,这样就能合二为一了?
如果业务允许,完全可以把两个表合为一个表。但是,有些时候,如果某个学生没有手机号,那么,contacts表就不存在对应的记录。实际上,一对一关系准确地说,是contacts表一对一对应students表。
还有一些应用会把一个大表拆成两个一对一的表,目的是把经常读取和不经常读取的字段分开,以获得更高的性能。例如,把一个大的用户表分拆为用户基本信息表user_info和用户详细信息表user_profiles,大部分时候,只需要查询user_info表,并不需要查询user_profiles表,这样就提高了查询速度。
小结
关系数据库通过外键可以实现一对多、多对多和一对一的关系。外键既可以通过数据库来约束,也可以不设置约束,仅依靠应用程序的逻辑来保证。
索引
在关系数据库中,如果有上万甚至上亿条记录,在查找记录的时候,想要获得非常快的速度,就需要使用索引。
索引是关系数据库中对某一列或多个列的值进行预排序的数据结构。通过使用索引,可以让数据库系统不必扫描整个表,而是直接定位到符合条件的记录,这样就大大加快了查询速度。
例如,对于students表:
id class_id name gender score
1 1 小明 M 90
2 1 小红 F 95
3 1 小军 M 88
如果要经常根据score列进行查询,就可以对score列创建索引:
ALTER TABLE students
ADD INDEX idx_score (score);
使用ADD INDEX idx_score (score)就创建了一个名称为idx_score,使用列score的索引。索引名称是任意的,索引如果有多列,可以在括号里依次写上,例如:
ALTER TABLE students
ADD INDEX idx_name_score (name, score);
索引的效率取决于索引列的值是否散列,即该列的值如果越互不相同,那么索引效率越高。反过来,如果记录的列存在大量相同的值,例如gender列,大约一半的记录值是M,另一半是F,因此,对该列创建索引就没有意义。
可以对一张表创建多个索引。索引的优点是提高了查询效率,缺点是在插入、更新和删除记录时,需要同时修改索引,因此,索引越多,插入、更新和删除记录的速度就越慢。
对于主键,关系数据库会自动对其创建主键索引。使用主键索引的效率是最高的,因为主键会保证绝对唯一。
唯一索引
在设计关系数据表的时候,看上去唯一的列,例如身份证号、邮箱地址等,因为他们具有业务含义,因此不宜作为主键。
但是,这些列根据业务要求,又具有唯一性约束:即不能出现两条记录存储了同一个身份证号。这个时候,就可以给该列添加一个唯一索引。例如,我们假设students表的name不能重复:
ALTER TABLE students
ADD UNIQUE INDEX uni_name (name);
通过UNIQUE关键字我们就添加了一个唯一索引。
也可以只对某一列添加一个唯一约束而不创建唯一索引:
ALTER TABLE students
ADD CONSTRAINT uni_name UNIQUE (name);
这种情况下,name列没有索引,但仍然具有唯一性保证。
无论是否创建索引,对于用户和应用程序来说,使用关系数据库不会有任何区别。这里的意思是说,当我们在数据库中查询时,如果有相应的索引可用,数据库系统就会自动使用索引来提高查询效率,如果没有索引,查询也能正常执行,只是速度会变慢。因此,索引可以在使用数据库的过程中逐步优化。
小结
通过对数据库表创建索引,可以提高查询速度。
通过创建唯一索引,可以保证某一列的值具有唯一性。
数据库索引对于用户和应用程序来说都是透明的。
边栏推荐
- 2.1-梯度下降
- 2022 China Soft Drink Market Insights
- 支持各种文件快速重命名最简单的小技巧
- 6月各手机银行活跃用户较快增长,创半年新高
- Tensorflow中使用tf.argmax返回张量沿指定维度最大值的索引
- Pytorch模型转ONNX模型
- Do you know the basic process and use case design method of interface testing?
- 项目2-年收入判断
- 2022-08-10 mysql/stonedb-slow SQL-Q16-time-consuming tracking
- 2021-08-11 for循环结合多线程异步查询并收集结果
猜你喜欢

TF中的四则运算
机器学习总结(二)
3GPP LTE/NR信道模型
4.1-支持向量机
1036 Programming with Obama (15 points)

tf.cast(), reduce_min(), reduce_max()
easyrecovery15数据恢复软件收费吗?功能强大吗?
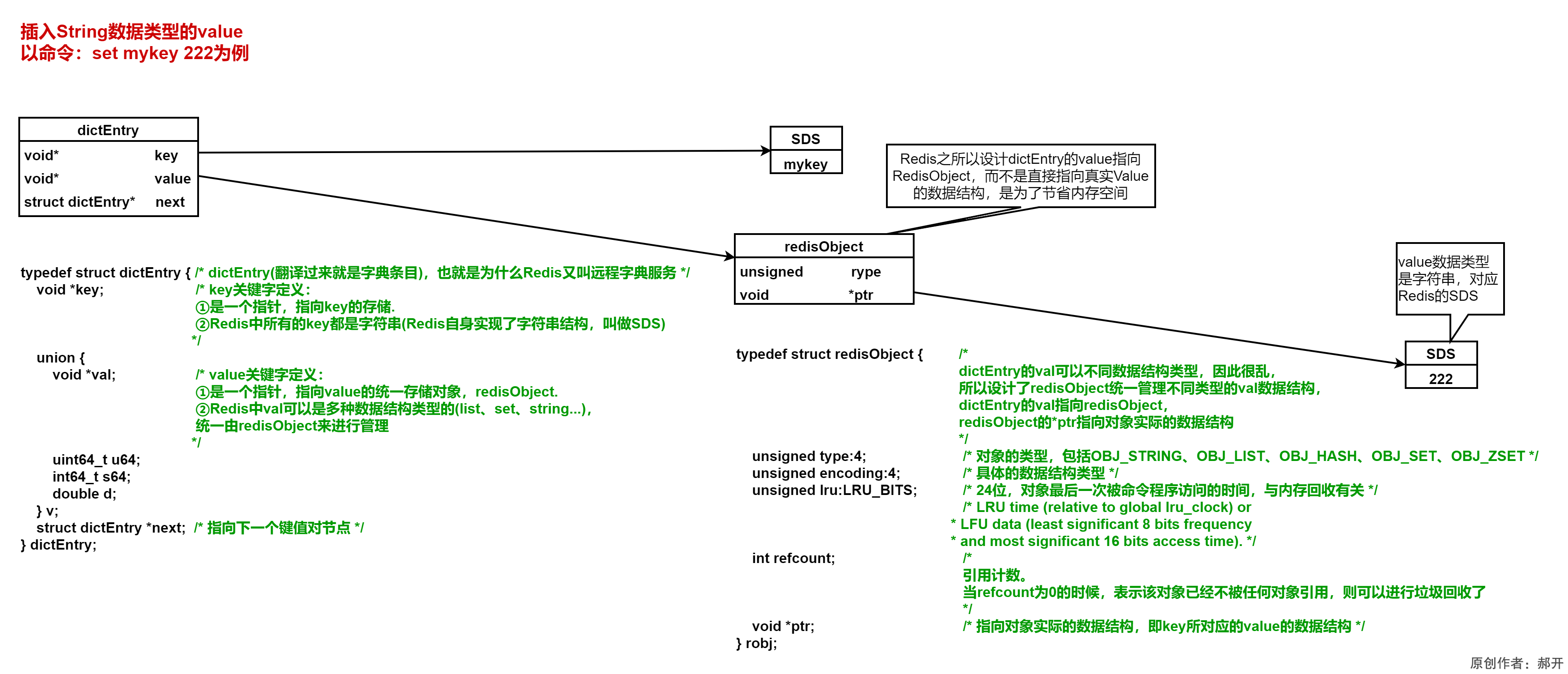
Redis source code-String: Redis String command, Redis String storage principle, three encoding types of Redis string, Redis String SDS source code analysis, Redis String application scenarios
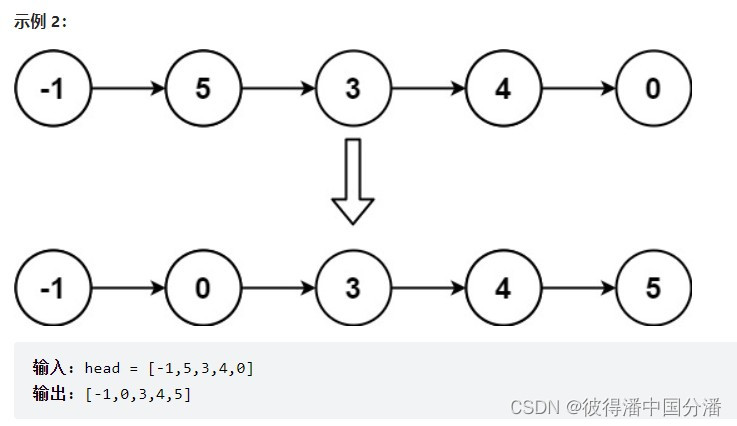
【LeetCode】Summary of linked list problems
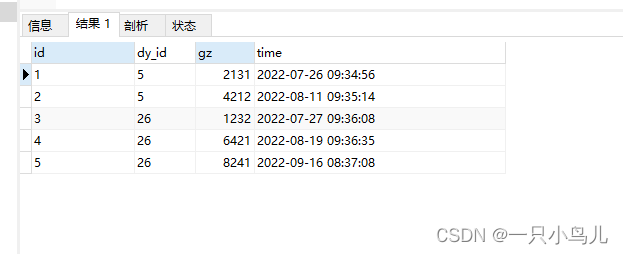
Find the latest staff salary and the last staff salary changes

随机推荐
1101 B是A的多少倍 (15 分)
Project 1 - PM2.5 Forecast
分布式锁-Redission - 缓存一致性解决
Activity的四种状态
1.1-回归
easyrecovery15数据恢复软件收费吗?功能强大吗?
租房小程序
The most complete documentation on Excel's implementation of grouped summation
Item 2 - Annual Income Judgment
1081 Check Password (15 points)
Decrement operation in tf; tf.assign_sub()
项目2-年收入判断
TF中的四则运算
囍楽cloud task source code
Distributed Lock-Redission - Cache Consistency Solution
My creative anniversary丨Thank you for being with you for these 365 days, not forgetting the original intention, and each is wonderful
从何跟踪伦敦金最新行情走势?
1106 2019数列 (15 分)
Redis source code-String: Redis String command, Redis String storage principle, three encoding types of Redis string, Redis String SDS source code analysis, Redis String application scenarios
1106 2019 Sequence (15 points)