当前位置:网站首页>SA-Siam:用于实时目标跟踪的双重连体网络A Twofold Siamese Network for Real-Time Object Tracking
SA-Siam:用于实时目标跟踪的双重连体网络A Twofold Siamese Network for Real-Time Object Tracking
2022-08-09 07:09:00 【代码的路】
摘要:
1.本文核心一:将图像分类任务中的语义特征(Semantic features)与相似度匹配任务中的外观特征(Appearance features)互补结合,非常适合与目标跟踪任务,因此本文方法可以简单概括为:SA-Siam=语义分支+外观分支;
2.Motivation:目标跟踪的特点是,我们想从众多背景中区分出变化的目标物体,其中难点为:背景和变化。本文的思想是用一个语义分支过滤掉背景,同时用一个外观特征分支来泛化目标的变化,如果一个物体被语义分支判定为不是背景,并且被外观特征分支判断为该物体由目标物体变化而来,那么我们认为这个物体即需要被跟踪的物体;
3.本文的目的是提升SiamFC在目标跟踪任务中的判别力。在深度CNN训练目标分类的任务中,网络中深层的特征具有强的语义信息并且对目标的外观变化拥有不变性。这些语义特征是可以用于互补SiamFC在目标跟踪任务中使用的外观特征。基于此发现,我们提出了SA-Siam,这是一个双重孪生网络,由语义分支和外观分支组成。每一个分支都使用孪生网络结构计算候选图片和目标图片的相似度。为了保持两个分支的独立性,两个孪生网络在训练过程中没有任何关系,仅仅在测试过程中才会结合。
4.本文核心二:对于新引入的语义分支,本文进一步提出了通道注意力机制。在使用网络提取目标物体的特征时,不同的目标激活不同的特征通道,我们应该对被激活的通道赋予高的权值,本文通过目标物体在网络特定层中的响应计算这些不同层的权值。实验证实,通过此方法,可以进一步提升语义孪生网络的判别力。
其仍然沿用SiamFC在跟踪过程中所有帧都和第一帧对比,是该类方法的主要缺陷。
相关工作:
RPN详细介绍:区域候选网络RPN
SiamFC详细介绍:SiamFC:用于目标跟踪的全卷积孪生网络
SiamRPN详细介绍:SiamRPN:孪生网络与RPN的结合
1.SiamFC:对于A,B,C三个图片,假设C图片和A图片是一个物体,但是外观发生了一些变化,B和A没有任何关系。SiamFC网络输入两张图片,那么经过SiamFC后会得到A和C相似度高,A和B相似度低。通过上述SiamFC的功能,自然地其可以用于目标跟踪算法中。SiamFC网络突出优点:无需在线fine-tune和end-to-end跟踪模式,使得其可以做到保证跟踪效果的前提下进行实时跟踪。
2.集成跟踪器:大多数跟踪是一个模型A,利用模型A对当前数据进行计算得到跟踪结果,集成跟踪器就是它有多个模型A,B,C,分别对当前数据进行分析,然后对结果融合得到最终的跟踪结果。本文的语义特征+外观特征正是借鉴了集成跟踪器的思路。在集成跟踪器,模型A,B,C相关度越低,跟踪效果越好,这个很好理解,如果他们三非常相关,那么用三个和用一个没啥区别,因为这个原因,本文的语义特征和外观特征网络在训练过程中是完全不相关的。
框架:
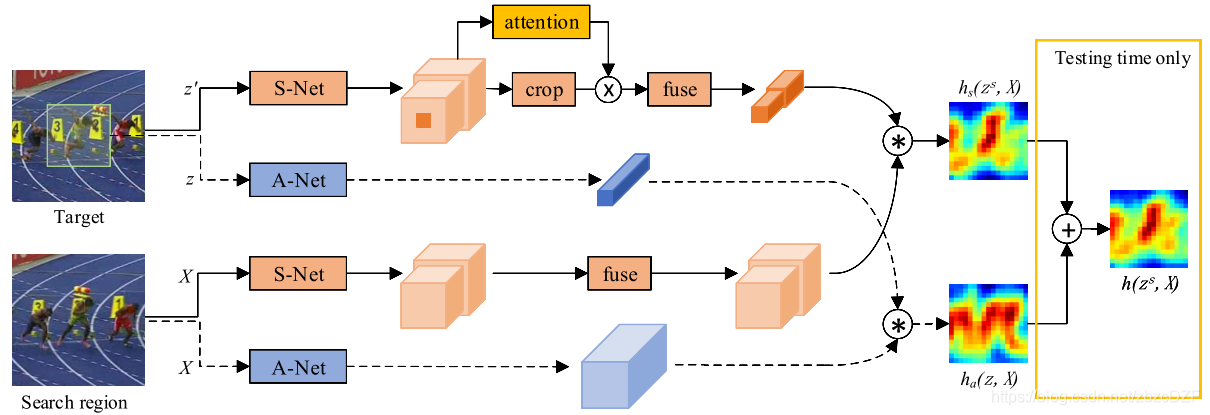
图2.提议的双重SA-Siam网络的体系结构。A-Net表示外观网络。用虚线连接的网络和数据结构与SiamFC完全相同。S-Net表示语义网络。提取最后两个卷积层的特征。信道关注模块基于目标和上下文信息确定每个特征信道的权重。外观分支和语义分支是单独训练的,直到测试时间才结合。
1.外观分支(蓝色部分):
一个目标A送到网络P里,一个比目标大的搜索域S送到网络P里,A出来的特征图与S出来的特征图进行卷积操作得到相关系数图,相关系数越大,越可能是同一个目标,网络则采用和SiamFC中一样的网络。
外观分支以(z,X)为输入。它克隆了SiamFC网络。用于提取外观特征的卷积网络称为A-Net。来自外观分支的响应映射可以写为:
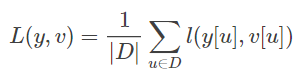
其中z是目标图像,X是搜索区域,fa(·)是特征提取,corr(·)是相关操作。在相似性学习问题中,A-Net中的所有参数都是从头开始训练的。
通过最小化逻辑损失函数L(·)来优化A-Net,如下:

其中θa表示A-Net中的参数,N是训练样本的数量,Yi是ground truth的响应。
2.语义分支(橙色部分):
这篇文章的重点便是此。橙色的表示语义网络,用的是预训练好的AlexNet,在训练和测试时固定所有参数,只提取最后conv4和conv5的特征,目标模板变为zs,zs和X一样大,和z有一样的中心,但包含了上下文信息,因为支路上加了通道注意力模型,通过目标和周围的信息来决定权重,选择对特定跟踪目标影响更大的通道。另外,为了更好的进行后续的相关操作,作者将上下两支路加入融合模型,加入了1×1的卷积层,对提取的两层每层进行卷积操作,使目标模板支路和检测支路的特征通道相同,而且通道总数和外观网络的通道一样。
语义分支网络训练时只训练通道注意力模块和融合模块。
来自语义分支的响应映射可以写为:
![]()
ξ是通道权重,g()是对特征进行融合,便于相关操作。
损失函数L(·)如下:

其中θs表示可训练参数,N是训练样本的数量。
3.结合:
外观网络和语义网络分开训练,语义网络只训练通道注意力模块和融合模块。在测试时间内,最终的响应图计算为来自两个分支的图的加权平均值:
![]()
其中λ是加权参数,以平衡两个分支的重要性。在实践中,λ可以从验证集估计。作者通过实验得出λ=0.3最好。
4.语义分支中的Channel Attention机制:
为什么要这么做:高维语义特征对目标的外观(图片的形变、旋转等)变化是鲁棒的,导致判别力低。为了提升语义分支的判别力,我们设计了一个Channel Attention模块。直觉上,在跟踪不同的物体时,不同的通道扮演着不同的角色,某些通道对于一些物体来说是极其重要的,但是对于其他物体而言则可以被忽略,甚至可能引入噪声。如果我们能自适应的调整通道的重要性,那么我们将获得目标跟可靠地特征表达。为了达到这个目的,不仅目标对于我们来说是重要的,其周围一定范围内的背景对于我们来说同样重要,因此这里输入网络的模板要比外观分支大一圈。
下面讲具体怎么实现这个功能的。

图3.通道注意力通过最大池化层和多层感知器(MLP)生成通道i的加权系数ξi。
上述图中,假设是conv5层的第i个通道特征图,维度为22×22,将该图分割成3×3份(其中中间的那份为6×6,是准确的目标),经过max-pooling操作后变成3×3的图,经过一个两层的MLP网络(Multi-Layer Perceptron多层感知机,含有9个神经元和一个隐层,隐层采用ReLU函数)后得到分数,在sigmoid一下(为了让得分系数在0~1之间)得到最终的得分系数。值得注意的是:这里的得分系数计算操作仅仅在第一帧进行计算,后续帧沿用第一帧的结果,所以其计算时间是可以忽略不计的;
实验:
数据维度:在我们的实现中,目标图像块z的尺寸为127×127×3,并且zs和X都具有255×255×3的尺寸。对于z和X,A-Net的输出特征具有尺寸分别为6×6×256和22×22×256。来自S-Net的conv4和conv5功能具有尺寸为24×24×384和22×22×256通道的zs和X。这两组功能的1×1 ConvNet每个输出128个通道(最多可达256个通道) ),空间分辨率不变。响应图具有相同的17×17维度。

SiamFC网络:

图中z代表的是模板图像,算法中使用的是第一帧的ground truth;x代表的是search region,代表在后面的待跟踪帧中的候选框搜索区域;ϕ代表的是一种特征映射操作,将原始图像映射到特定的特征空间,文中采用的是CNN中的卷积层和pooling层;6×6×128代表z经过ϕ后得到的特征,是一个128通道6×6大小feature,同理,22×22×128是x经过ϕ后的特征;后面的×代表卷积操作,让22×22×128的feature被6×6×128的卷积核卷积,得到一个17×17的score map,代表着搜索区域中各个位置与模板相似度值。
算法本身是比较搜索区域与目标模板的相似度,最后得到搜索去区域的score map。其实从原理上来说,这种方法和相关性滤波的方法很相似。其在搜索区域中逐点的目标模板进行匹配,将这种逐点平移匹配计算相似度的方法看成是一种卷积,然后在卷积结果中找到相似度值最大的点,作为新的目标的中心。
上图所画的ϕ其实是CNN中的一部分,并且两个ϕ的网络结构是一样的,这是一种典型的孪生神经网络,并且在整个模型中只有conv层和pooling层,因此这也是一种典型的全卷积(fully-convolutional)神经网络。
在训练模型的时肯定需要损失函数,并通过最小化损失函数来获取最优模型。本文算法为了构造有效的损失函数,对搜索区域的位置点进行了正负样本的区分,即目标一定范围内的点作为正样本,这个范围外的点作为负样本,例如图1中最右侧生成的score map中,红色点即正样本,蓝色点为负样本,他们都对应于search region中的红色矩形区域和蓝色矩形区域。文章采用的是logistic loss,具体的损失函数形式如下:
对于score map中了每个点的损失:
![]()
其中v是score map中每个点真实值,y∈{+1,−1}是这个点所对应的标签。
上面的是score map中每个点的loss值,而对于score map整体的loss,则采用的是全部点的loss的均值。即:
这里的u∈D代表score map中的位置。
整个网络结构类似与AlexNet,但是没有最后的全连接层,只有前面的卷积层和pooling层。

整个网络结构入上表,其中pooling层采用的是max-pooling,每个卷积层后面都有一个ReLU非线性激活层,但是第五层没有。另外,在训练的时候,每个ReLU层前都使用了batch normalization(批规范化是深度学习中经常见到的一种训练方法,指在采用梯度下降法训练DNN时,对网络层中每个mini-batch的数据进行归一化,使其均值变为0,方差变为1,其主要作用是缓解DNN训练中的梯度消失/爆炸现象,加快模型的训练速度),用于降低过拟合的风险。
AlexNet:

AlexNet为8层结构,其中前5层为卷积层,后面3层为全连接层;学习参数有6千万个,神经元有650,000个
AlexNet在两个GPU上运行;
AlexNet在第2,4,5层均是前一层自己GPU内连接,第3层是与前面两层全连接,全连接是2个GPU全连接;
RPN层第1,2个卷积层后;
Max pooling层在RPN层以及第5个卷积层后。
ReLU在每个卷积层以及全连接层后。
卷积核大小数量:
conv1:96 11×11×3(个数/长/宽/深度)
conv2:256 5×5×48
conv3:384 3×3×256
conv4: 384 3×3×192
conv5: 256 3×3×192
ReLU、双GPU运算:提高训练速度。(应用于所有卷积层和全连接层)
重叠pool池化层:提高精度,不容易产生过度拟合。(应用在第一层,第二层,第五层后面)
局部响应归一化层(LRN):提高精度。(应用在第一层和第二层后面)
Dropout:减少过度拟合。(应用在前两个全连接层)
微调(fine-tune):
看到一个很好的模型,虽然针对的具体问题不一样,可以把别人现成的训练好了的模型拿过来,换成自己的数据,调整一下参数,再训练一遍,这就是微调(fine-tune)。
冻结预训练模型的部分卷积层(通常是靠近输入的多数卷积层),训练剩下的卷积层(通常是靠近输出的部分卷积层)和全连接层。从某意义上来说,微调应该是迁移学习中的一部分。
感知机:PLA
多层感知机是由感知机推广而来,感知机学习算法(PLA: Perceptron Learning Algorithm)用神经元的结构进行描述的话就是一个单独的。
感知机的神经网络表示如下:

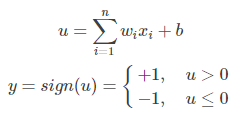
多层感知机:MLP
多层感知机的一个重要特点就是多层,我们将第一层称之为输入层,最后一层称之有输出层,中间的层称之为隐层。MLP并没有规定隐层的数量,因此可以根据各自的需求选择合适的隐层层数。且对于输出层神经元的个数也没有限制。
MLP神经网络结构模型如下,本文中只涉及了一个隐层,输入只有三个变量[x1,x2,x3]和一个偏置量b,输出层有三个神经元。相比于感知机算法中的神经元模型对其进行了集成。

ReLU函数:

sigmod函数:

学习更多编程知识,请关注我的公众号:
边栏推荐
- 更改Jupyter Notebook默认打开目录
- ByteDance Interview Questions: Mirror Binary Tree 2020
- bzoj 5333 [Sdoi2018]荣誉称号
- Leetcode 70 stairs issues (Fibonacci number)
- Built-in macros in C language (define log macros)
- Lottie系列四:使用建议
- MySQL高级特性之分布式(XA)事务的介绍
- SAP ALV data export many of the bugs
- 金九银十即将到来,求职套路多,面试指南我来分享~
- 基于布朗运动的文本生成方法-LANGUAGE MODELING VIA STOCHASTIC PROCESSES
猜你喜欢

Variable used in lambda expression should be final or effectively final报错解决方案

排序第一节——插入排序(直接插入排序+希尔排序)(视频讲解26分钟)
子路由及路由出口配置
灵活好用的sql monitoring 脚本 part7

web自动化测试有哪些工具和框架?
排序第二节——选择排序(选择排序+堆排序)(两个视频讲解)

Tkinter可以选择的颜色
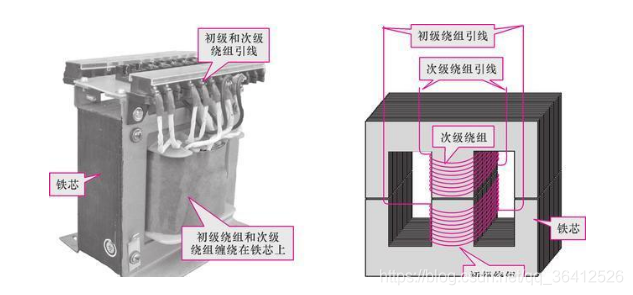
The working principle of the transformer (illustration, schematic explanation, understand at a glance)
链表专项练习(三)
postgresql Window Functions
随机推荐
Neural Network Optimizer
2022年7月小结
The working principle of the transformer (illustration, schematic explanation, understand at a glance)
Lottie系列三 :原理分析
P1505 [国家集训队]旅游 树链剖分
链表专项练习(三)
找出数组中不重复的值php
排序第四节——归并排序(附有自己的视频讲解)
买口罩(0-1背包)
leetcode:55. 跳跃游戏
jmeter并发数量以及压力机的一些限制
Use tensorflow.keras to build a neural network model modularly
【nuxt】服务器部署步骤
XxlJobConfig distributed timer task management XxlJob configuration class, replace
The maximum validity period of an SSL certificate is 13 months. Is it necessary to apply for multiple years at a time?
Leetcode 70 stairs issues (Fibonacci number)
Distributed id generator implementation
Learning Notes---Machine Learning
SAP ALV 数据导出被截断的bug
【报错】Root Cause com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure