当前位置:网站首页>loggie 源码分析 source file 模块主干分析
loggie 源码分析 source file 模块主干分析
2022-04-23 16:34:00 【序冢--磊】
项目官网:
代码细节很多,自己也比较懒、比如说job生成的jobUid,rename的标识等等细节很多,所以不去挨个梳理,只梳理大体流程,了解大框架更容易读懂代码
一、file模块整体架构
有些模块就不分析了,比如mutliline模块
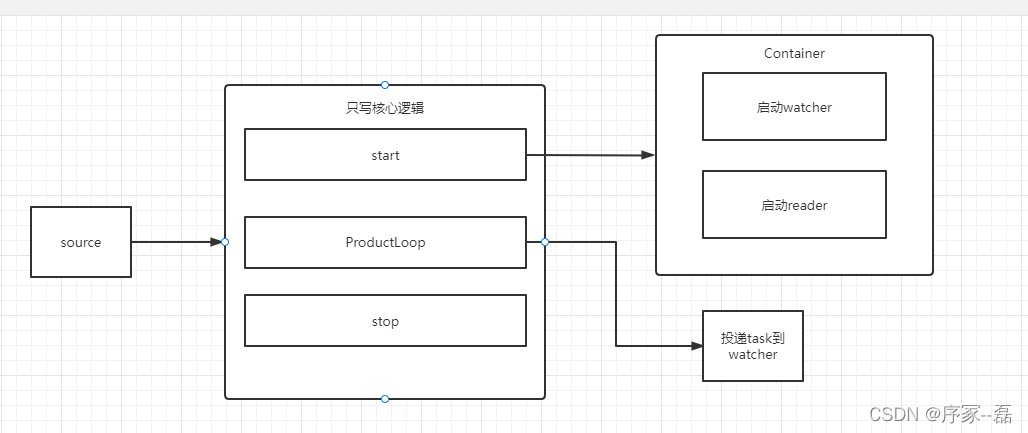
source 通过manager.go 创建和使用 watcher、reader、ascTask、watcherTask、DbHandle MultiProcess等子模块
source->start 函数是一个比较关键的函数,创建并启动了 watcher 和 reader等待任务投递到channel
func (s *Source) Start() {
log.Info("start source: %s", s.String())
if s.config.ReaderConfig.MultiConfig.Active {
s.multilineProcessor = GetOrCreateShareMultilineProcessor()
}
// register queue listener for ack
if s.ackEnable {
s.dbHandler = GetOrCreateShareDbHandler(s.config.DbConfig)
s.ackChainHandler = GetOrCreateShareAckChainHandler(s.sinkCount, s.config.AckConfig)
s.rc.RegisterListener(&AckListener{
sourceName: s.name,
ackChainHandler: s.ackChainHandler,
})
}
s.watcher = GetOrCreateShareWatcher(s.config.WatchConfig, s.config.DbConfig)
s.r = GetOrCreateReader(s.isolation, s.config.ReaderConfig, s.watcher)
s.HandleHttp()
}watcher 的创建并且监听
func newWatcher(config WatchConfig, dbHandler *dbHandler) *Watcher {
w := &Watcher{
done: make(chan struct{}),
config: config,
sourceWatchTasks: make(map[string]*WatchTask),
waiteForStopWatchTasks: make(map[string]*WatchTask),
watchTaskChan: make(chan *WatchTask),
dbHandler: dbHandler,
zombieJobChan: make(chan *Job, config.MaxOpenFds+1),
allJobs: make(map[string]*Job),
osWatchFiles: make(map[string]bool),
zombieJobs: make(map[string]*Job),
countDown: &sync.WaitGroup{},
stopOnce: &sync.Once{},
}
w.initOsWatcher()
go w.run()
return w
}reader 的创建切监听,start里开启协程等待Job进来
func newReader(config ReaderConfig, watcher *Watcher) *Reader {
r := &Reader{
done: make(chan struct{}),
config: config,
jobChan: make(chan *Job, config.ReadChanSize),
watcher: watcher,
countDown: &sync.WaitGroup{},
stopOnce: &sync.Once{},
startOnce: &sync.Once{},
}
r.Start()
return r
}投递task.从而继续后面watcher的工作
func (s *Source) ProductLoop(productFunc api.ProductFunc) {
log.Info("%s start product loop", s.String())
s.productFunc = productFunc
if s.config.ReaderConfig.MultiConfig.Active {
s.mTask = NewMultiTask(s.epoch, s.name, s.config.ReaderConfig.MultiConfig, s.eventPool, s.productFunc)
s.multilineProcessor.StartTask(s.mTask)
s.productFunc = s.multilineProcessor.Process
}
if s.config.AckConfig.Enable {
s.ackTask = NewAckTask(s.epoch, s.pipelineName, s.name, func(state *State) {
s.dbHandler.state <- state
})
s.ackChainHandler.StartTask(s.ackTask)
}
s.watchTask = NewWatchTask(s.epoch, s.pipelineName, s.name, s.config.CollectConfig, s.eventPool, s.productFunc, s.r.jobChan, s.config.Fields)
// start watch source paths
s.watcher.StartWatchTask(s.watchTask)
}二、watcher模块整体架构
watcher 管理多个WatcherTasks,每一个watcherTask 管理多个Job。
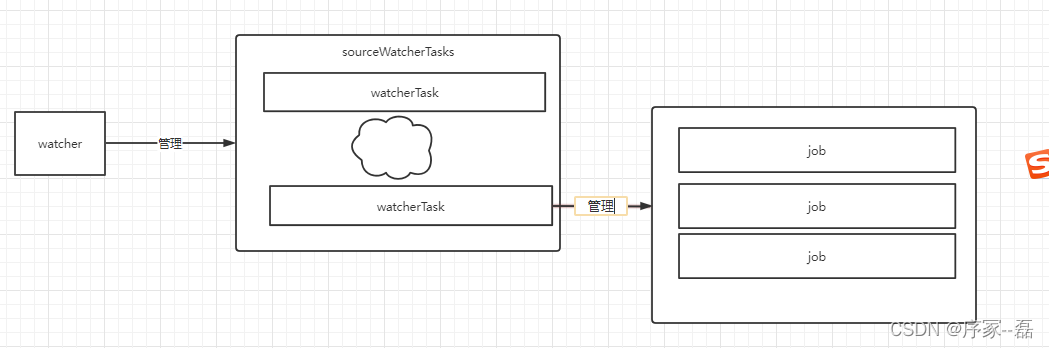
首先watcher做了什么?
watcher再等待,等待消息和事件的 到来
func (w *Watcher) run() {
w.countDown.Add(1)
log.Info("watcher start")
scanFileTicker := time.NewTicker(w.config.ScanTimeInterval)
maintenanceTicker := time.NewTicker(w.config.MaintenanceInterval)
defer func() {
w.countDown.Done()
scanFileTicker.Stop()
maintenanceTicker.Stop()
log.Info("watcher stop")
}()
var osEvents chan fsnotify.Event
if w.config.EnableOsWatch && w.osWatcher != nil {
osEvents = w.osWatcher.Events
}
for {
select {
case <-w.done:
return
case watchTask := <-w.watchTaskChan:
w.handleWatchTaskEvent(watchTask)
case job := <-w.zombieJobChan:
w.decideZombieJob(job)
case e := <-osEvents:
//log.Info("os event: %v", e)
w.osNotify(e)
case <-scanFileTicker.C:
w.scan()
case <-maintenanceTicker.C:
w.maintenance()
}
}
}w.done 标志已经处理完了,不做任何处理
handleWatchTaskEvent 用来管理task列表的启动和停止,并且进行持久化加载sqlite数据库处理
decideZombieJob 用来决定任务是否是僵尸作业,如果作业不活跃会被加到僵尸作业里,等待观察
osEvent 其实就是底层的inotify 用来接收文件变动事件
scan是个比较重要的事件,定时扫描文件和作业,性能这样比较好,如果用inotify create 事件可能会造成频繁唤醒,占用cpu比较高
func (w *Watcher) scan() {
// check any new files
w.scanNewFiles()
// active job
w.scanActiveJob()
// zombie job
w.scanZombieJob()
}Job 作业是通过消息总线eventBus,投递给reader的,投递动作在
func (j *Job) Read() {
j.task.activeChan <- j
}可以把当前的job投递给reader
三、Reader模块简要分析
reader 开始读作业文件,从上次的偏移量一直读到当前的末尾,然后通过ProductEvent发送给下游,发送给拦截器
核心代码:
func (r *Reader) work(index int) {
r.countDown.Add(1)
log.Info("read worker-%d start", index)
defer func() {
log.Info("read worker-%d stop", index)
r.countDown.Done()
}()
readBufferSize := r.config.ReadBufferSize
maxContinueReadTimeout := r.config.MaxContinueReadTimeout
maxContinueRead := r.config.MaxContinueRead
inactiveTimeout := r.config.InactiveTimeout
backlogBuffer := make([]byte, 0, readBufferSize)
readBuffer := make([]byte, readBufferSize)
jobs := r.jobChan
for {
select {
case <-r.done:
return
case job := <-jobs:
filename := job.filename
status := job.status
if status == JobStop {
log.Info("job(uid: %s) file(%s) status(%d) is stop, job will be ignore", job.Uid(), filename, status)
r.watcher.decideJob(job)
continue
}
file := job.file
if file == nil {
log.Error("job(uid: %s) file(%s) released,job will be ignore", job.Uid(), filename)
r.watcher.decideJob(job)
continue
}
lastOffset, err := file.Seek(0, io.SeekCurrent)
if err != nil {
log.Error("can't get offset, file(name:%s) seek error, err: %v", filename, err)
r.watcher.decideJob(job)
continue
}
job.currentLines = 0
startReadTime := time.Now()
continueRead := 0
isEOF := false
wasSend := false
readTotal := int64(0)
processed := int64(0)
backlogBuffer = backlogBuffer[:0]
for {
readBuffer = readBuffer[:readBufferSize]
l, readErr := file.Read(readBuffer)
if errors.Is(readErr, io.EOF) || l == 0 {
isEOF = true
job.eofCount++
break
}
if readErr != nil {
log.Error("file(name:%s) read error, err: %v", filename, err)
break
}
read := int64(l)
readBuffer = readBuffer[:read]
now := time.Now()
processed = 0
for processed < read {
index := int64(bytes.IndexByte(readBuffer[processed:], '\n'))
if index == -1 {
break
}
index += processed
endOffset := lastOffset + readTotal + index
if len(backlogBuffer) != 0 {
backlogBuffer = append(backlogBuffer, readBuffer[processed:index]...)
job.ProductEvent(endOffset, now, backlogBuffer)
// Clean the backlog buffer after sending
backlogBuffer = backlogBuffer[:0]
} else {
job.ProductEvent(endOffset, now, readBuffer[processed:index])
}
processed = index + 1
}
readTotal += read
// The remaining bytes read are added to the backlog buffer
if processed < read {
backlogBuffer = append(backlogBuffer, readBuffer[processed:]...)
// TODO check whether it is too long to avoid bursting the memory
//if len(backlogBuffer)>max_bytes{
// log.Error
// break
//}
}
wasSend = processed != 0
if wasSend {
continueRead++
// According to the number of batches 2048, a maximum of one batch can be read,
// and a single event is calculated according to 512 bytes, that is, the maximum reading is 1mb ,maxContinueRead = 16 by default
// SSD recommends that maxContinueRead be increased by 3 ~ 5x
if continueRead > maxContinueRead {
break
}
if time.Since(startReadTime) > maxContinueReadTimeout {
break
}
}
}
if wasSend {
job.eofCount = 0
job.lastActiveTime = time.Now()
}
l := len(backlogBuffer)
if l > 0 {
// When it is necessary to back off the offset, check whether it is inactive to collect the last line
wasLastLineSend := false
if isEOF && !wasSend {
if time.Since(job.lastActiveTime) >= inactiveTimeout {
// Send "last line"
endOffset := lastOffset + readTotal
job.ProductEvent(endOffset, time.Now(), backlogBuffer)
job.lastActiveTime = time.Now()
wasLastLineSend = true
// Ignore the /n that may be written next.
// Because the "last line" of the collection thinks that either it will not be written later,
// or it will write /n first, and then write the content of the next line,
// it is necessary to seek a position later to ignore the /n that may be written
_, err = file.Seek(1, io.SeekCurrent)
if err != nil {
log.Error("can't set offset, file(name:%s) seek error: %v", filename, err)
}
} else {
// Enable the job to escape and collect the last line
job.eofCount = 0
}
}
// Fallback accumulated buffer offset
if !wasLastLineSend {
backwardOffset := int64(-l)
_, err = file.Seek(backwardOffset, io.SeekCurrent)
if err != nil {
log.Error("can't set offset, file(name:%s) seek error: %v", filename, err)
}
}
}
r.watcher.decideJob(job)
}
}
}版权声明
本文为[序冢--磊]所创,转载请带上原文链接,感谢
https://blog.csdn.net/qq_32783703/article/details/124332577
边栏推荐
- Change the icon size of PLSQL toolbar
- Es common query, sorting and aggregation statements
- Database dbvisualizer Pro reported file error, resulting in data connection failure
- 浅谈 NFT项目的价值、破发、收割之争
- JSP learning 1
- Install redis and deploy redis high availability cluster
- Custom implementation of Baidu image recognition (instead of aipocr)
- homwbrew安装、常用命令以及安装路径
- On the value, breaking and harvest of NFT project
- G008-HWY-CC-ESTOR-04 华为 Dorado V6 存储仿真器配置
猜你喜欢
On the security of key passing and digital signature

力扣-746.使用最小花费爬楼梯

人脸识别框架之dlib

下载并安装MongoDB

第九天 static 抽象类 接口
Creation of RAID disk array and RAID5
阿里研发三面,面试官一套组合拳让我当场懵逼

Research and Practice on business system migration of a government cloud project
Set cell filling and ranking method according to the size of the value in the soft report
G008-hwy-cc-estor-04 Huawei Dorado V6 storage simulator configuration
随机推荐
Hyperbdr cloud disaster recovery v3 Release of version 3.0 | upgrade of disaster recovery function and optimization of resource group management function
JIRA screenshot
RecyclerView advanced use - to realize drag and drop function of imitation Alipay menu edit page
451. 根据字符出现频率排序
Grbl learning (II)
Qipengyuan horizon credible meta universe social system meets diversified consumption and social needs
捡起MATLAB的第(3)天
The system research problem that has plagued for many years has automatic collection tools, which are open source and free
JSP learning 1
The first line and the last two lines are frozen when paging
Day 9 static abstract class interface
ES常用查询、排序、聚合语句
The solution of not displaying a whole line when the total value needs to be set to 0 in sail software
Sail soft segmentation solution: take only one character (required field) of a string
Detailed explanation of gzip and gunzip decompression parameters
Force buckle-746 Climb stairs with minimum cost
100 deep learning cases | day 41 - convolutional neural network (CNN): urbansound 8K audio classification (speech recognition)
ESXi封装网卡驱动
捡起MATLAB的第(6)天
Database dbvisualizer Pro reported file error, resulting in data connection failure