Jump Reward Inference for 1D Music Rhythmic State Spaces
An implementation of the probablistic jump reward inference model for music rhythmic information retrieval using the proposed 1D state space.

This repository contains the source code and demo videos of a joint music rhythmic analyzer system using the 1D state space and jump reward technique proposed in ICASSP-2022. This implementation includes music beat, downbeat, tempo, and meter tracking jointly and in a causal fashion.
The model first takes the waveform to the spectral domain and then feeds them into one of the pre-trained BeatNet models to obtain beat/downbeat activations. Finally, the activations are used in a jump-reward inference model to infer beats, downbeats, tempo, and meter.
System Input:
Raw audio waveform
System Output:
A vector including beats, downbeats, local tempo, and local meter columns, respectively and with the following shape: numpy_array(num_beats, 4).
Installation Command:
Approach #1: Installing binaries from the pypi website:
pip install jump-reward-inference
Approach #2: Installing directly from the Git repository:
pip install git+https://github.com/mjhydri/1D-StateSpace
Usage Example:
estimator = joint_inference(1, plot=True)
output = estimator.process("music file directory")
Video Demos:
This section demonstrates the system performance for several music genres. Each demo comprises four plots that are described as follows:
- The first plot: 1D state space for music beat and tempo tracking. Each bar represents the posterior probability of the corresponding state at each time frame.
- The second plot: The jump-back reward vector for the corresponding beat states.
- The third plot:1D state space for music downbeat and meter tracking.
- The fourth plot: The jump-back reward vector for the corresponding downbeat states.
1: Music Genre: Pop
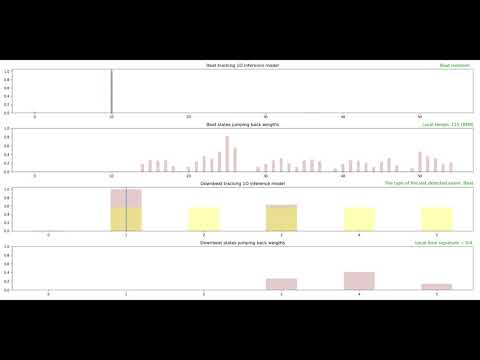
2: Music Genre: Country
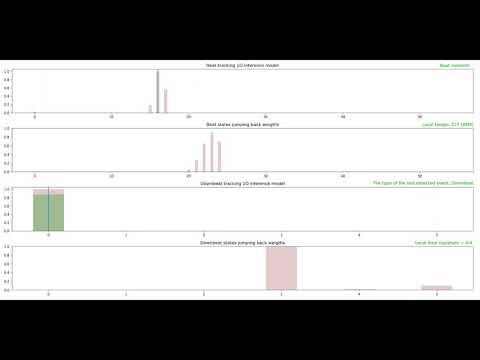
3: Music Genre: Reggae
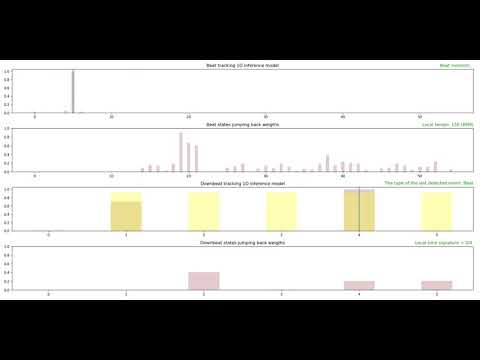
4: Music Genre: Blues
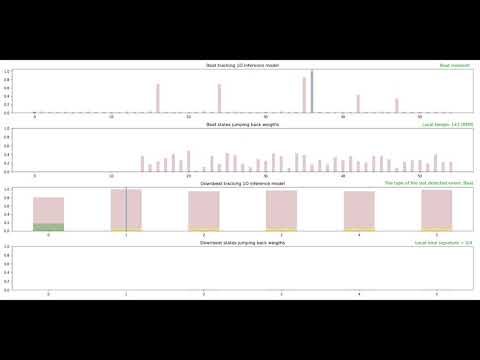
5: Music Genre: Classical
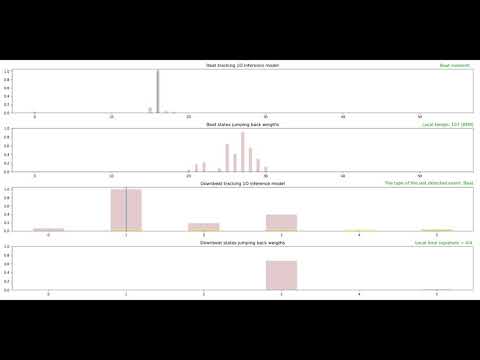
Demos Discussion:
1- As demo videos suggest, the system infers multiple music rhythmic parameters, including music beat, downbeat, tempo and meter jointly and in an online fashion using very compact 1D state spaces and jump back reward technique. The system works suitably for different music genres. However, the process is relatively more straightforward for some genres such as pop and country due to the rich percussive content, solid attacks, and simpler rhythmic structures. In contrast, it is more challenging for genres with poor percussive profile, longer attack times, and more complex rhythmic structures such as classical music.
2- Since both neural networks and inference models are designed for online/real-time applications, the causalilty constrains are applied and future data is not accessible. It makes the jumpback weigths weaker initially and become stronger over time.
3- Given longer listening time is required to infer higher hierarchies, i.e., downbeat and meter, within the very early few seconds, downbeat results are less confident than lower hierarchies, i.e., beat and tempo, however, they get accurate after observing a bar period.
Acknowledgement
This work has been partially supported by the National Science Foundation grant 1846184.
References:
M. Heydari, M. McCallum, A. Ehmann and Z. Duan, "A Novel 1D State Space for Efficient Music Rhythmic Analysis", In Proc. IEEE Int. Conf. Acoust. Speech Signal Process. (ICASSP), 2022. #(Submitted)
M. Heydari, F. Cwitkowitz, and Z. Duan, “BeatNet:CRNN and particle filtering for online joint beat down-beat and meter tracking,” in Proc. of the 22th Intl. Conf.on Music Information Retrieval (ISMIR), 2021.
M. Heydari and Z. Duan, “Don’t Look Back: An online beat tracking method using RNN and enhanced particle filtering,” in Proc. IEEE Int. Conf. Acoust. Speech Signal Process. (ICASSP), 2021.
 34 Nov 15, 2022
34 Nov 15, 2022
 61 Nov 25, 2022
61 Nov 25, 2022
 4 Sep 13, 2022
4 Sep 13, 2022

 398 Dec 30, 2022
398 Dec 30, 2022
 80 Dec 30, 2022
80 Dec 30, 2022
 66 Dec 26, 2022
66 Dec 26, 2022
 182 Jan 7, 2023
182 Jan 7, 2023

 38 Oct 11, 2022
38 Oct 11, 2022

 108 Nov 23, 2022
108 Nov 23, 2022


 140 Dec 19, 2022
140 Dec 19, 2022
 24 May 30, 2022
24 May 30, 2022
 2 Aug 09, 2022
2 Aug 09, 2022
 61 Dec 28, 2022
61 Dec 28, 2022
 7 Sep 20, 2022
7 Sep 20, 2022
 87 Dec 26, 2022
87 Dec 26, 2022
 7 Oct 12, 2022
7 Oct 12, 2022
 694 Dec 23, 2022
694 Dec 23, 2022
 769 Dec 08, 2022
769 Dec 08, 2022
 57 Dec 04, 2022
57 Dec 04, 2022
 102 Dec 26, 2022
102 Dec 26, 2022
 1 Jan 04, 2022
1 Jan 04, 2022
 176 Dec 17, 2022
176 Dec 17, 2022
 15 Apr 21, 2022
15 Apr 21, 2022
 6 Dec 07, 2022
6 Dec 07, 2022
 1.1k Dec 18, 2022
1.1k Dec 18, 2022
 559 Dec 14, 2022
559 Dec 14, 2022
 1 Feb 24, 2022
1 Feb 24, 2022
 18 Jan 01, 2023
18 Jan 01, 2023
 28 Aug 25, 2022
28 Aug 25, 2022