当前位置:网站首页>是什么让训练综合分类网络艰苦?
是什么让训练综合分类网络艰苦?
2022-08-10 03:32:00 【Rainylt】
paper : What makes training multi-modal classification networks hard?
cvpr2020
One sentence summary: In multi-modal training, the overfitting index obtained by combining the validation set and the training set is used to modulate the Loss< of different modalities./strong>Weights to solve the imbalance problem of multimodal training.
After a sentence is finished, there are still many questions. This article is also worth writing a note.
Multimodal fusion method
(1) Early Fusion
Concat or fuse by other means when the original data is input
(2) Mid Fusion
After extracting features, concat, then go through the Fusion module, and then go through the classification head
(3) Late Fusion
After extracting features, concat, and directly pass the classification header
What is the multimodal training imbalance problem?
The reason is that the author found that in the video classification task, the multi-modal model is not as good as the single-modal model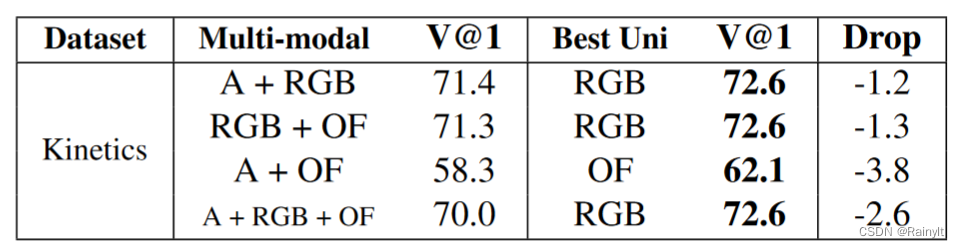
As shown above, A is Audio and OF is optical flow.
The models used are similar. For example, A+RGB is to add Audio's Encoder on the basis of single RGB, and then concat the two features together and classify them through the classifier.The single RGB is directly RGB through the encoder, and then classified by the classifier.
It seems that there is no transformer added after concat for fuse?Maybe the fuse module can solve this problem to some extent?
Why?
Two findings:
(1) The multi-modal model has a higher training set accuracy, but the validation set accuracy is lower
(2) The Late Fusion model has a singleThe modal model has almost twice as many parameters
=>Suspected problem is overfitting
How to solve it?
First try the conventional solution to overfitting:
1. Dropout
2. Pre-train
3. early stop
Then try the mid-Fusion solution:
1. Concatenate (conv gets the feature, continue to conv after concat, and finally pass the classification header)
2. Gating in SE mode
3. Gating in Non-Local mode (that is, transformer)
Comments:
1. Early stop is completely impossible, maybe it is stoptoo early?
2. Pre-train is better than late-concat without Pre-train, but it can't catch up with single-modal RGB, or maybe it's because Pre-train is not very good?
3. Mid-concat has some improvements, but it is better than Non-Local. I didn't expect it, because Non-Local is only connected to one layer?Are there more convs after mid-concat?
4. Dropout has some effects, because there is indeed overfitting, but dropout was not added?
5. SE is a channel-level Attention, and there is no space, time, and frequency-level Attention, and the effect is poor.Excusable, adding it is the same as not adding it
This part has to look at the detail.
In other words, mid-concat is better than late concat, and dropout can also work, but the improvement is not much.
If dropout can work, it means that the network does have overfitting. After adding dropout, it finally exceedsSingle mode, mid-concat can also exceed single mode, so it is still necessary to fusion early.
Project for this article
In order to solve the problem of overfitting, this paper first proposes an indicator to measure the degree of overfitting: 
*Represents the real scene (approximately on the validation set).
At the same time, based on Late Fusion, there are 3 branches, each with a classification header: 
The middle is the feature after concat, plus a classification header, and the two sides are the respective classification headers.Each Loss has a weight, and the weight is optimized by the above indicators: 
Finally get the weight formula:
The derivation is not too muchI understand, but in short, he assigned a weight to each Loss, so how did he do it in the final test?
边栏推荐
猜你喜欢
![[Semantic Segmentation] 2022-HRViT CVPR](/img/6c/b1e6bc32a8e06c5dccbf2bd62e1751.png)





随机推荐
Anchor_generators.py analysis of MMDetection framework
[Kali Security Penetration Testing Practice Tutorial] Chapter 6 Password Attack
Open3D 网格均匀采样
基于C51的中断控制
2022.8.8考试区域链接(district)题解
[Semantic Segmentation] 2022-HRViT CVPR
[Red Team] ATT&CK - Self-starting - Self-starting mechanism using LSA authentication package
How Microbes Affect Physical Health
Robust Real-time LiDAR-inertial Initialization(实时鲁棒的LiDAR惯性初始化)论文学习
2022年立下的flag完成情况
In automated testing, test data is separated from scripts and parameterized methods
【图像分类】2022-ResMLP
Will signal with different start time alignment
Open3D 泊松盘网格采样
16. 最接近的三数之和
MySQL: What MySQL optimizations have you done?
Arcgis进阶篇(1)——安装Arcgis Enterprise,创建sde库
ArcGIS Advanced (1) - Install ArcGIS Enterprise and create an sde library
State compression small experience
第二十一章 源代码文件 REST API 参考(三)